
1. RabbitMQ概念
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而群集和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
RabbitMQ特点
可靠性: RabbitMQ使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
灵活的路由 : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
扩展性: 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
高可用性 : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
多种协议: RabbitMQ除了原生支持AMQP协议,还支持STOMP, MQTT等多种消息 中间件协议。
多语言客户端 :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
管理界面 : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
令插件机制 : RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件。
2. RabbitMQ配置
服务器配置
默认文件位置: /etc/rabbitmq/rabbitmq.conf ,没有可以自己创建。
主要的配置文件示例:https://github.com/rabbitmq/rabbitmq-server/blob/master/deps/rabbit/docs/rabbitmq.conf.example ,可以直接先复制下来,再根据自己的需求更改。
各项配置作用说明,可以查看官方地址:https://www.rabbitmq.com/configure.html#config-file。
此外还有其他配置,如可选的advanced.config,可以一起参考:https://github.com/rabbitmq/rabbitmq-server/tree/master/deps/rabbit/docs 下的文件,根据自己的情况选择
rabbitmq.conf 和 advanced.config 更改在节点重新启动后生效。
3. RabbitMQ整体结构
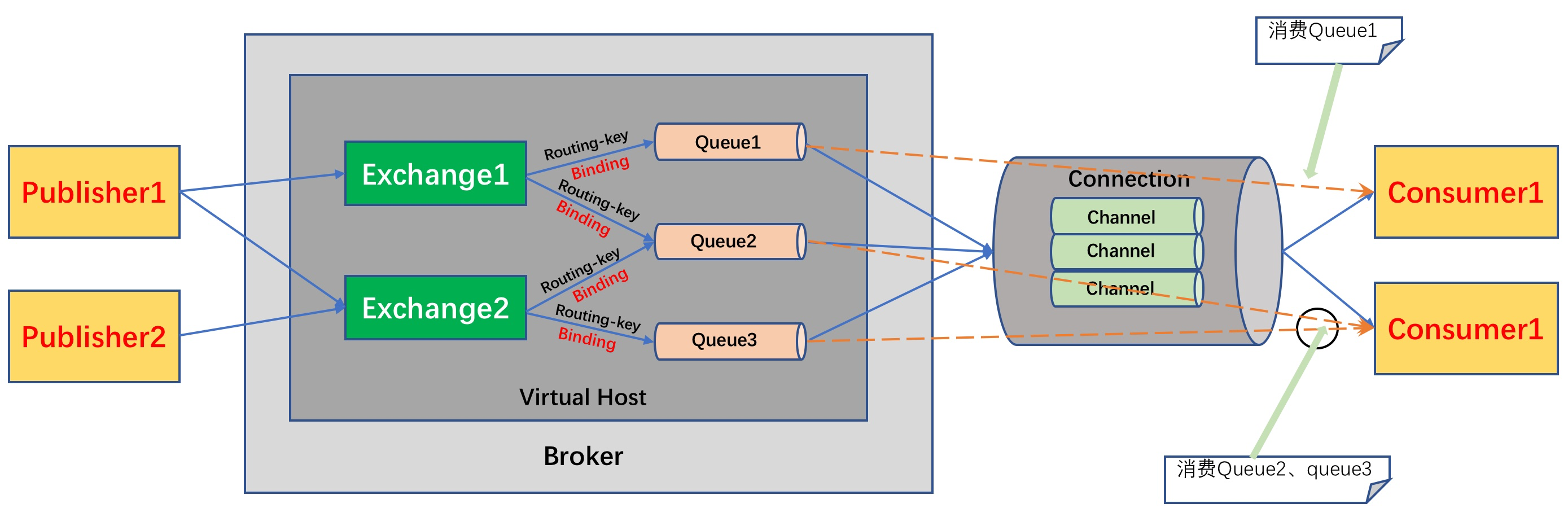

转载至:https://www.cnblogs.com/jing99/p/11679426.html
作者: kosamino
AMQP是一个异步消息传递所使用的应用层协议规范,AMQP客户端能够无视消息来源任意发送和接受消息,Broker提供消息的路由、队列等功能。Broker主要由Exchange和Queue组成:Exchange负责接收消息、转发消息到绑定的队列;Queue存储消息,提供持久化、队列等功能。AMQP客户端通过Channel与Broker通信,Channel是多路复用连接中的一条独立的双向数据流通道。
1. RabbitMQ进程模型
RabbitMQ Server实现了AMQP模型中Broker部分,将Channel和Queue设计成了Erlang进程,并用Channel进程的运算实现Exchange的功能。
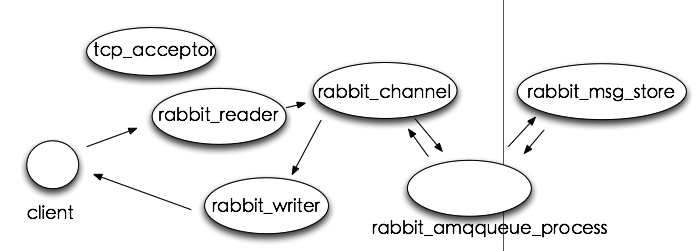
图中,tcp_acceptor进程接收客户端连接,创建rabbit_reader、rabbit_writer、rabbit_channel进程。rabbit_reader接收客户端连接,解析AMQP帧;rabbit_writer向客户端返回数据;rabbit_channel解析AMQP方法,对消息进行路由,然后发给相应队列进程。rabbit_amqqueue_process是队列进程,在RabbitMQ启动(恢复durable类型队列)或创建队列时创建。rabbit_msg_store是负责消息持久化的进程。
在整个系统中,存在一个tcp_accepter进程,一个rabbit_msg_store进程,有多少个队列就有多少个rabbit_amqqueue_process进程,每个客户端连接对应一个rabbit_reader和rabbit_writer进程。
2. RabbitMQ流控
RabbitMQ可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞(block),直到对应项恢复正常。除了这两个阈值,RabbitMQ在正常情况下还用流控(Flow Control)机制来确保稳定性。
Erlang进程之间并不共享内存(binaries类型除外),而是通过消息传递来通信,每个进程都有自己的进程邮箱。Erlang默认没有对进程邮箱大小设限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。
在RabbitMQ中,如果生产者持续高速发送,而消费者消费速度较低时,如果没有流控,很快就会使内部进程邮箱大小达到内存阈值,阻塞生产者(得益于block机制,并不会崩溃)。然后RabbitMQ会进行page操作,将内存中的数据持久化到磁盘中。
为了解决该问题,RabbitMQ使用了一种基于信用证的流控机制。消息处理进程有一个信用组{InitialCredit,MoreCreditAfter},默认值为{200, 50}。消息发送者进程A向接收者进程B发消息,每发一条消息,Credit数量减1,直到为0,A被block住;对于接收者B,每接收MoreCreditAfter条消息,会向A发送一条消息,给予A MoreCreditAfter个Credit,当A的Credit>0时,A可以继续向B发送消息。
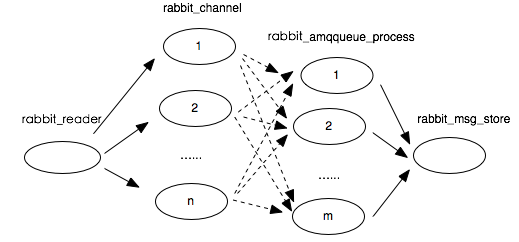
可以看出基于信用证的流控最终将消息发送进程的发送速度限制在消息处理进程的处理速度内。RabbitMQ中与流控有关的进程构成了一个有向无环图。
3. amqqueue进程与Paging
如上所述,消息的存储和队列功能是在amqqueue进程中实现。为了高效处理入队和出队的消息、避免不必要的磁盘IO,amqqueue进程为消息设计了4种状态和5个内部队列。
4种状态包括:alpha,消息的内容和索引都在内存中;beta,消息的内容在磁盘,索引在内存;gamma,消息的内容在磁盘,索引在磁盘和内存中都有;delta,消息的内容和索引都在磁盘。对于持久化消息,RabbitMQ先将消息的内容和索引保存在磁盘中,然后才处于上面的某种状态(即只可能处于alpha、gamma、delta三种状态之一)。
5个内部队列包括:q1、q2、delta、q3、q4。q1和q4队列中只有alpha状态的消息;q2和q3包含beta和gamma状态的消息;delta队列是消息按序存盘后的一种逻辑队列,只有delta状态的消息。所以delta队列并不在内存中,其他4个队列则是由erlang queue模块实现。

消息从q1入队,q4出队,在内部队列中传递的过程一般是经q1顺序到q4。实际执行并非必然如此:开始时所有队列都为空,消息直接进入q4(没有消息堆积时);内存紧张时将q4队尾部分消息转入q3,进而再由q3转入delta,此时新来的消息将存入q1(有消息堆积时)。
Paging就是在内存紧张时触发的,paging将大量alpha状态的消息转换为beta和gamma;如果内存依然紧张,继续将beta和gamma状态转换为delta状态。Paging是一个持续过程,涉及到大量消息的多种状态转换,所以Paging的开销较大,严重影响系统性能。
二. 问题分析
在生产者、消费者均正常情况下,RabbitMQ压测性能非常稳定,保持在一个恒定的速度。当消费者异常或不消费时,RabbitMQ则表现极不稳定。
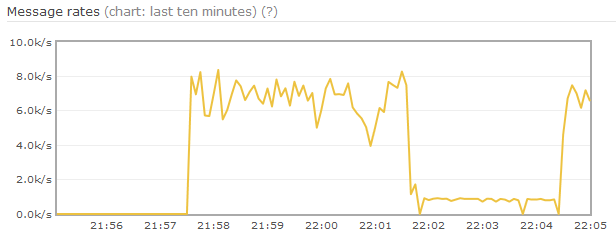

测试场景如下,exchange和队列都是持久化的,消息也是持久化的、固定为1K,并且无消费者。如上图所示,在达到内存paging阈值后,生产速率降低,并持续较长时间。内存使用情况表明,在内存中的消息数目只有18M内容,其他消息已经page到磁盘中,然而进程内存仍占用2G。Erlang内存使用表明,Queues占用了2G,Binaries占用了2.1G。
该情况说明在消息从内存page到磁盘后(即从q2、q3队列转到delta后),系统中产生了大量的垃圾(garbage),而Erlang VM没有进行及时的垃圾回收(GC)。这导致RabbitMQ错误的计算了内存使用量,并持续调用paging流程,直到Erlang VM隐式垃圾回收。
三. 内存管理优化
RabbitMQ内存使用量的计算是在memory_monitor进程内执行的,该进程周期性计算系统内存使用量。同时amqqueue进程会周期性拉取内存使用量,当内存达到paging阈值时,触发amqqueue进程进行paging。paging发生后,amqqueue进程每收到一条新消息都会对内部队列进行page(每次page都会计算出一定数目的消息存盘)。
该过程可行的优化方案是:在amqqueue进程将大部分消息paging到磁盘后,显式调用GC,同时将memory_monitor周期设为0.5s、amqqueue拉取周期设为1s,这样就能够达到秒级恢复;去掉对每条消息执行paging的操作,用amqqueue周期性拉取内存使用量的操作来触发page,这样能够更快将消息paging到磁盘,而且保持这个周期内生产速度不下降。
具体修改可查看:
https://github.com/rabbitmq/rabbitmq-server/compare/stable...javaforfun:stable
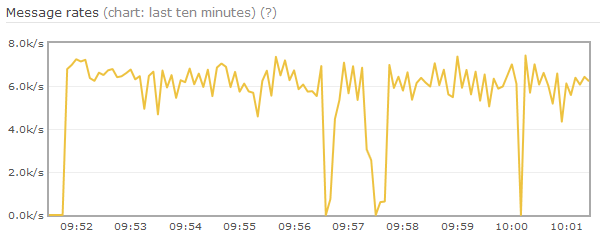
从修改后效果可以看出,三次paging都很快结束,前两次paging相邻较近是因为两个镜像节点分别执行了paging。
该问题已反馈至RabbitMQ社区:
从图5中还可以发现,在22:01时生产速度有一个明显的下降(此时未发生paging)。通过流控分析,链路被block在amqqueue进程;经观察发现节点内存使用下降了,说明该节点执行了GC。Erlang GC是按进程级别的标记-清扫模式,会将当前进程暂停,直至GC结束。由于在RabbitMQ中,一个队列只有一个amqqueue进程,该进程又会处理大量的消息,产生大量的垃圾。这就导致该进程GC较慢,进而流控block上游更长时间。
查看RabbitMQ代码发现,amqqueue进程的gen_server模型在正常的逻辑中调用了hibernate,该操作可能导致两次不必要的GC。优化掉hibernate对系统稳定性有一些帮助。
对流控可能比较好的优化方案是:用多个amqqueue进程来实现一个队列,这样可以降低rabbit_channel被单个amqqueue进程block的概率,同时在单队列的场景下也能更好利用多核的特性。不过该方案对RabbitMQ现有的架构改动很大,难度也很大。
四. 参数调优
RabbitMQ可优化的参数分为两个部分,Erlang部分和RabbitMQ自身。
IO_THREAD_POOL_SIZE:CPU大于或等于16核时,将Erlang异步线程池数目设为100左右,提高文件IO性能。
hipe_compile:开启Erlang HiPE编译选项(相当于Erlang的jit技术),能够提高性能20%-50%。在Erlang R17后HiPE已经相当稳定,RabbitMQ官方也建议开启此选项。
queue_index_embed_msgs_below:RabbitMQ 3.5版本引入了将小消息直接存入队列索引(queue_index)的优化,消息持久化直接在amqqueue进程中处理,不再通过msg_store进程。由于消息在5个内部队列中是有序的,所以不再需要额外的位置索引(msg_store_index)。该优化提高了系统性能10%左右。
vm_memory_high_watermark:用于配置内存阈值,建议小于0.5,因为Erlang GC在最坏情况下会消耗一倍的内存。
vm_memory_high_watermark_paging_ratio:用于配置paging阈值,该值为1时,直接触发内存满阈值,block生产者。
queue_index_max_journal_entries:journal文件是queue_index为避免过多磁盘寻址添加的一层缓冲(内存文件)。对于生产消费正常的情况,消息生产和消费的记录在journal文件中一致,则不用再保存;对于无消费者情况,该文件增加了一次多余的IO操作。
转载至:https://cloud.tencent.com/developer/article/1004383
作者:腾讯云社区
4. RabbitMQ服务端
4.1. 队列
概述
队列是一种具有两个主要操作的顺序数据结构:一个项目可以在尾部入队(添加)和从头部出队(消耗)。 队列在消息传递技术领域发挥着重要作用:许多消息传递协议和工具假设发布者和消费者使用类似队列的存储机制进行通信。 RabbitMQ 中的队列是 FIFO(“先进先出”)。 一些队列特征,即优先级和消费者重新排队,会影响消费者观察到的排序。
队列具有名称,以便应用程序可以引用它们。应用程序可以选择队列名称或要求代理为它们生成一个名称。队列名称最多可以是 255 个字节的 UTF-8 字符。以“amq”开头的队列名称。保留供经纪人内部使用。尝试使用违反此规则的名称声明队列将导致通道级异常,回复代码为 403 ( ACCESS_REFUSED )。
在使用队列之前,必须先声明它。如果队列不存在,则声明队列将导致它被创建。如果队列已经存在并且其属性与声明中的属性相同,则声明将不起作用。当现有队列属性与声明中的属性不同时,将引发代码为 406 ( PRECONDITION_FAILED )的通道级异常。
RabbitMQ队列结构
通常由以下两部分组成
rabbit_amqqueue_process:负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的 confirm 和消费端的 ack) 等。
backing_queue:是消息存储的具体形式和引擎,并向 rabbit amqqueue process提供相关的接口以供调用。
官方参考:https://www.rabbitmq.com/queues.html#exclusive-queues
特性
队列具有定义其行为方式的属性。有一组强制性属性和可选属性的映射:
- 名称
- 持久(队列将在代理重启后继续存在)
- 独占(仅由一个连接使用,该连接关闭时队列将被删除)
- 自动删除(当最后一个消费者取消订阅时,删除至少有一个消费者的队列)
- 参数(可选;由插件和特定于代理的功能使用,例如消息 TTL、队列长度限制等)
请注意,并非所有属性组合在实践中都有意义。例如,自动删除和独占队列应该是server-named。此类队列应该用于特定于客户端或特定于连接(会话)的数据。
当自动删除或独占队列使用众所周知的(静态)名称时,在客户端断开连接并立即重新连接的情况下,RabbitMQ 节点之间将存在自然竞争条件,这将删除此类队列并恢复将尝试重新声明它们的客户端. 这可能会导致客户端连接恢复失败或异常,并造成不必要的混乱或影响应用程序可用性。
消息排序
RabbitMQ 中的队列是消息的有序集合。 消息以先进先出的方式入队和出队(传递给消费者)。 优先级和分片队列不能保证 FIFO 排序。 排序也会受到多个竞争消费者的存在、消费者优先级、消息重新传递的影响。 这适用于任何类型的重新交付:在渠道关闭和消费者负面确认后自动交付。 应用程序可以假设在单个通道上发布的消息将按发布顺序排列在它们路由到的所有队列中。 当发布发生在多个连接或通道上时,它们的消息序列将被并发路由和交错。 消费应用程序可以假设对单个消费者的初始交付(重新交付属性设置为 false 的那些)按照与入队相同的 FIFO 顺序执行。 对于重复交付(redelivered 属性设置为 true),原始订购可能会受到消费者确认和重新交付时间的影响,因此无法保证。 在多个消费者的情况下,消息将按 FIFO 顺序出队交付,但实际交付将发生在多个消费者身上。 如果所有的消费者都有相同的优先级,他们将在循环的基础上被挑选出来。 只有未超过其预取值(未确认的未确认交付数量)的通道上的消费者才会被考虑。
如果需要为并行性(更好的 CPU 核心利用率)权衡消息排序,rabbitmq-sharding 提供了一种对客户端透明的自以为是的方法。
耐用性
队列可以是持久的或暂时的。 持久队列的元数据存储在磁盘上,而临时队列的元数据尽可能存储在内存中。 在某些协议(例如 AMQP 0-9-1 和 MQTT)中,在发布时对消息进行了相同的区分。 在持久性很重要的环境和用例中,应用程序必须使用持久队列并确保发布将发布的消息标记为持久化。 临时队列将在节点启动时被删除。 因此,按照设计,它们将无法在节点重启后幸存下来。 临时队列中的消息也将被丢弃。 持久队列将在节点启动时恢复,包括其中发布为持久性的消息。 发布为瞬态的消息将在恢复期间被丢弃,即使它们存储在持久队列中。
如何选择
在大多数其他情况下,推荐使用持久队列。 对于复制队列,唯一合理的选择是使用持久队列。 大多数情况下,队列的吞吐量和延迟不受队列是否持久的影响。 只有具有非常高的队列或绑定流失的环境(即,队列每秒被删除和重新声明数百次或更多次)才会看到某些操作(即绑定)的延迟改进。 因此,持久队列和瞬态队列之间的选择归结为用例的语义。 对于具有临时客户端的工作负载,临时队列可能是一个合理的选择,例如,用户界面中的临时 WebSocket 连接、移动应用程序和预计会脱机或使用交换机身份的设备。 此类客户端通常具有固有的瞬态状态,应在客户端重新连接时替换该状态。 某些队列类型不支持临时队列。 例如,由于底层复制协议的假设和要求,仲裁队列必须是持久的。
复制和分布式队列
队列可以复制到多个集群节点,并在松散耦合的节点或集群之间联合。 提供了两种复制队列类型:
仲裁队列
启用镜像的经典队列
仲裁队列指南中介绍了它们之间的区别。 仲裁队列是大多数工作负载和用例的推荐选项。 请注意,集群内复制和联合是正交特性,不应被视为直接替代方案。
**生存时间和长度限制 **
队列可以限制其长度。 队列和消息可以有一个 TTL。 这两个特性都可用于数据过期,并作为一种限制队列最多可以使用多少资源(RAM、磁盘空间)的方式,例如当消费者离线或他们的吞吐量落后于发布者时。
在内存和持久存储中
队列将消息保存在 RAM 和/或磁盘上。 在某些协议(例如 AMQP 0-9-1)中,这部分由客户端控制。 在 AMQP 0-9-1 中,这是通过消息属性(delivery_mode 或在某些客户端中,持久性)完成的。 将消息发布为瞬态表明 RabbitMQ 应该在 RAM 中保留尽可能多的消息。 然而,当队列发现自己处于内存压力下时,它们甚至会将临时消息分页到磁盘。 路由到持久队列的持久性消息会分批或经过一定时间(几分之一秒)后持久化。 延迟队列将页面消息更积极地排入磁盘,而不管它们的持久性如何。
优先事项
队列可以有 0 个或多个优先级。 此功能是可选的:只有通过可选参数配置了最大优先级数的队列才会进行优先级排序。 发布者使用消息属性中的优先级字段指定消息优先级。 如果需要优先级队列,我们建议使用 1 到 10。目前使用更多的优先级会消耗更多的资源(Erlang 进程)。
指标和监控
RabbitMQ 收集有关队列的多个指标。 它们中的大部分都可以通过 RabbitMQ HTTP API 和管理 UI 获得,后者专为监控而设计。 这包括队列长度、入口和出口速率、消费者数量、各种状态下的消息数量(例如准备交付或未确认)、RAM 中的消息数量与磁盘上的消息数量等。 rabbitmqctl 可以列出队列和一些基本指标。 可以使用 rabbitmq-top 插件和管理 UI 中的各个队列页面访问 VM 调度程序使用情况、队列 (Erlang) 进程 GC 活动、队列进程使用的 RAM 量、队列进程邮箱长度等运行时指标
消费者和确认
可以通过注册消费者(订阅)来消费消息,这意味着 RabbitMQ 会将消息推送到客户端,或者为支持此功能的协议(例如 basic.get AMQP 0-9-1 方法)单独获取消息,类似于 HTTP GET。 一旦将传递写入连接套接字,消费者就可以显式或自动确认传递的消息。 自动确认模式通常会提供更高的吞吐率并使用更少的网络带宽。 但是,它在失败时提供的保证最少。 根据经验,首先考虑使用手动确认模式。
预取和消费者过载
自动确认模式也可能使消费者不堪重负,因为它们无法像传递消息一样快速地处理消息。 这可能导致消费者进程的内存使用量和/或操作系统交换永久增长。 手动确认模式提供了一种设置未完成(未确认)交付数量限制的方法:通道 QoS(预取)。 使用更高(数千或更多)预取级别的消费者可能会遇到与使用自动确认的消费者相同的过载问题。 大量未确认的消息将导致代理使用更高的内存。
消息状态
因此,入队消息可以处于以下两种状态之一:
准备发货
已交付但尚未被消费者认可
可以在管理 UI 中找到按状态细分的消息。
确定队列长度
可以通过多种方式确定队列长度:
对于 AMQP 0-9-1,使用 queue.declare 方法响应 (queue.declare-ok) 上的属性。 字段名称是 message_count。 它的访问方式因客户端库而异。
使用 RabbitMQ HTTP API。
使用 rabbitmqctl list_queues 命令。
队列长度定义为准备发送的消息数。
队列长度限制
对于任何给定的队列,最大长度(任一类型)可以是 使用 定义 策略 (强烈推荐此选项) 或由客户端使用 队列的可选参数 。 如果有效队列策略和参数都指定了最大长度, 将使用两个值中的最小值。
可以通过提供最大消息数来设置 x-max-length 队列声明参数 非负整数值。
可以通过提供以字节为单位的最大长度 x-max-length-bytes 队列声明参数 非负整数值。
如果设置了两个参数,则两者都将适用; 以任何限制为准 首先被击中将被强制执行。
Java中的这个例子声明了一个最大长度的队列 共 10 条消息:
1 | Map<String, Object> args = new HashMap<String, Object>(); |
更多队列长度限制配置可以参考:https://www.rabbitmq.com/maxlength.html
4.1.1. 经典队列
一、概述
重要提示 :经典队列的镜像将 在的未来版本RabbitMQ 中删除 。 考虑改用 仲裁队列 或非复制经典队列。
默认情况下,RabbitMQ 集群中队列的内容位于 单个节点(队列所在的节点 声明)。 这与交换和绑定相反, 这总是可以被认为是在所有节点上。 队列 可以选择在其他集群节点上运行镜像(附加副本)。
每个镜像队列由一个 领导副本 和 一个或多个 镜像 (副本)。 领导者被托管在一个节点通常称为该队列的领导节点。 每个队列都有 它自己的领导节点。 首先应用给定队列的所有操作 在队列的领导节点上,然后传播到镜像。 这包括排队发布、向消费者传递消息、跟踪 消费者的认可等等。
队列镜像意味着节点集群。 因此不推荐使用 跨 WAN(当然,客户端仍然可以连接 从近处和远处根据需要)。
发布到队列的消息被复制到所有镜像。 消费者与领导者无关 他们连接到哪个节点,镜像丢弃消息 得到了领导的认可。 队列镜像提高了可用性,但不分发跨节点负载(所有参与节点都完成所有 工作)。
如果承载队列领导者的节点发生故障,只要同步,最早的镜像就会提升为新的领导者。 根据队列镜像参数,也可以提升未同步的镜像。
二、配置
镜像到所有节点是最保守的选择。 它会给所有集群节点带来额外的压力,包括网络 I/O、磁盘 I/O 和 磁盘空间使用情况。 在大多数情况下,不需要在每个节点上都有一个副本。
对于 3 个或更多节点的集群 建议复制到法定人数(大多数)节点, 例如,3 节点集群中的 2 个节点或 5 节点集群中的 3 个节点。
由于某些数据可能是固有的瞬态或对时间非常敏感, 使用较少数量的镜子是完全合理的 对于某些队列(甚至不使用任何镜像)。
要使队列成为镜像,您需要创建一个匹配它们并设置策略键 ha-mode 和(可选) ha-params 的策略 。 下表说明了这些键的选项:
| ha-mode | ha-params | 结果 |
|---|---|---|
| exactly | count | 集群中的队列副本(领导者加镜像)的数量。 计数值为 1 表示单个副本:只是队列领导者。 如果运行队列领导者的节点变得不可用,则行为取决于队列持久性。 计数值为 2 表示 2 个副本:1 个队列领导者和 1 个队列镜像。 换句话说:NumberOfQueueMirrors = NumberOfNodes - 1。 如果运行队列leader的节点不可用,队列镜像会根据配置的镜像提升策略自动提升为leader。 如果集群中的节点数少于 count 个,则将队列镜像到所有节点。 如果集群中有超过 count 个节点,并且一个包含镜像的节点宕机,那么将在另一个节点上创建一个新镜像。 使用带有 "ha-promote-on-shutdown": "always" 的 exactly 模式可能很危险,因为队列可以跨集群迁移,并在它关闭时变得不同步 |
| all | (none) | 队列跨集群中的所有节点进行镜像。 当一个新节点被添加到集群中时,队列将被镜像到该节点。 这个设置非常保守。 建议改为镜像到仲裁 (N/2 + 1) 个集群节点。 镜像到所有节点会给所有集群节点带来额外的压力,包括网络 I/O、磁盘 I/O 和磁盘空间使用 |
| nodes | node names | 队列被镜像到节点名称中列出的节点。 节点名称是出现在 rabbitmqctl cluster_status 中的 Erlang 节点名称; 它们通常具有“rabbit@hostname”的形式。 如果这些节点名称中的任何一个不属于集群的一部分,则这不构成错误。 如果在声明队列时列表中没有任何节点在线,则将在声明客户端连接到的节点上创建队列 |
每当队列的 HA 策略发生变化时,它都会努力 保持其现有的镜子尽可能适合新的 政策。
以下是名称以“two”开头的队列的策略。
1 | 镜像到集群中任意两个节点,自动同步: |
三、设计
RabbitMQ 中的每个队列都有一个主副本。 那个副本叫做 队列领导者 (最初是“队列主人”)。 所有队列操作都经过leader 先复制副本,然后再复制到追随者(镜像)。 这是必要的 保证消息的 FIFO 顺序。
避免集群中的某些节点托管大多数队列领导者 副本并因此处理大部分负载,队列领导者应该 合理均匀地分布在集群节点上。
队列领导者可以使用多个节点分布在节点之间 策略。 使用哪种策略由三种方式控制, 即,使用 x-queue-master-locator 可选队列参数 ,设置 queue-master-locator 策略键或通过定义 queue_master_locator 关键在 配置文件 。 以下是可能的策略以及如何设置它们:
- 选择承载最少领导者数量的节点: min-masters
- 选择声明队列的客户端所在的节点连接到: client-local
- 选择一个随机节点: random
请注意,设置或修改“节点”策略可能会导致 现有的领导者如果没有列在 新政策。 为了防止消息丢失,RabbitMQ 会 保留现有的领导者,直到至少另一个 镜像已同步(即使这是一个很长的 时间)。 但是,一旦发生同步,事情就会 就像节点失败一样继续:消费者将 与领导者断开连接,需要重新连接。
例如,如果队列在 [AB] (以 A 为首),然后你给它 一个 节点 策略告诉它开启 [CD] ,它最初会在 [ACD] 。 一旦队列同步到新的 镜像 [CD] , 上的领导者 A 将关闭。
独占队列将在连接时被删除 宣布他们已关闭。 为此,它没有用 用于要镜像的独占队列(或为此持久 问题)因为当托管它的节点出现故障时, 连接将关闭,需要删除队列 反正。
出于这个原因,独占队列永远不会被镜像(即使 如果它们符合规定它们应该符合的政策)。 他们 也永远不会持久(即使如此声明)。
本指南侧重于镜像队列,这很重要,但是相比之下,简要解释非镜像队列在集群中的行为方式。
如果队列的leader节点(运行队列leader的节点)可用, 所有队列操作(例如声明、绑定和消费者管理、消息路由 到队列)可以在任何节点上执行。 集群节点将路由 对领导节点的操作对客户端透明。
如果队列的领导节点 变得不可用,非镜像队列的行为 取决于它的耐用性。 持久队列将变成 在节点返回之前不可用。 领导节点不可用的持久队列上的所有操作将失败并在服务器日志中显示如下所示的消息:
1 | operation queue.declare caused a channel exception not_found: home node 'rabbit@hostname' of durable queue 'queue-name' in vhost '/' is down or inaccessible |
如果希望队列始终可用, 也可以将镜像配置为 即使不同步, 提升为领导者 。
镜像队列实现和语义
如前所述,对于每个镜像队列,有一个领导副本和多个镜像,每个镜像都位于不同的节点上。 镜像与领导者以完全相同的顺序将发生的操作应用于领导者,从而保持相同的状态。 除了发布之外的所有动作都只传递给领导者,然后领导者将动作的效果广播给镜像。 因此,从镜像队列消费的客户端实际上是从领导者消费。
如果镜像失败,除了一些记录之外别无他法:领导者仍然是领导者,客户端不需要采取任何行动或被告知失败。 请注意,可能无法立即检测到镜像故障,并且每个连接流控制机制的中断可能会延迟消息发布。 详细信息在节点间通信心跳指南中进行了描述。
如果领导者失败,那么其中一个镜像将被提升为 领导如下:
运行时间最长的镜像被提升为领导者,假设它最有可能与领导者完全同步。 如果没有与leader同步的镜像,那么只存在于leader上的消息就会丢失。
镜像认为所有先前的消费者都已突然断开连接。 它将所有已传递给客户端但等待确认的消息重新排队。 这可能包括客户端已发出确认的消息,例如,如果确认在到达托管队列领导者的节点之前在线上丢失,或者从领导者向镜像广播时丢失。 在任何一种情况下,新的领导者别无选择,只能将所有没有看到确认的消息重新排队。重复消费问题
已请求在队列故障转移时收到通知的消费者将收到取消通知。
作为重新排队的结果,从队列中重新消费的客户端必须意识到他们可能随后会收到他们已经收到的消息。
由于所选择的镜子成为领导者,因此在此期间发布到镜像队列的消息将不会丢失(禁止在升级节点上的后续故障)。发布到承载队列镜像的节点的消息将路由到队列领导者,然后复制到所有镜像。 如果领导者失败,消息会继续发送到镜像,并在镜像提升到领导者完成后添加到队列中。
即使领导者(或任何镜像)在发布消息和发布者收到确认之间失败,客户端使用发布者确认发布的消息仍将得到确认。 从发布者的角度来看,发布到镜像队列与发布到非镜像队列没有区别。
如果消费者使用 自动确认模式 ,那么消息可能会丢失。 这没有什么不同 来自非镜像队列,当然:代理考虑一条消息 承认 只要它已发送到自动应答模式下的消费。
如果客户端突然断开连接,则可能永远不会收到消息。 在一个 镜像队列,如果领导者死亡,正在传输的消息, 他们以自动确认模式发给消费者的方式可能永远不会被收到 由这些客户端,并且不会被新的领导者重新排队。 因为 消费客户端连接到节点的可能性 幸存下来, 消费者取消通知 有助于确定此类事件何时可能发生发生。 当然,在实践中,如果数据安全不那么重要相比吞吐量,自动确认模式是更好的模式。
1 | 针对rabbitMQ消费者重复消费问题,可以使用这样一个机制解决: |
发布者确认和交易
镜像队列支持发布者确认和交易。 选择的语义是,在确认和交易的情况下,操作跨越队列的所有镜像。 因此,在事务的情况下,只有当事务已应用于队列的所有镜像时,tx.commit-ok 才会返回给客户端。 同样,在发布者确认的情况下,只有在所有镜像都接受了消息后,才会向发布者确认消息。 将语义视为与被路由到多个普通队列的消息相同的语义是正确的,并且其中具有发布的事务被类似地路由到多个队列。
流量控制
RabbitMQ 使用基于信用的算法来限制消息发布的速率。 当发布者从队列的所有镜像中获得信用时,他们被允许发布。 在这种情况下,信用意味着发布许可。 无法获得信用的镜像可能会导致发布者停滞不前。 发布者将保持阻塞状态,直到所有镜像发出信用或直到其余节点认为镜像已与集群断开连接。 Erlang 通过定期向所有节点发送滴答来检测这种断开连接。 滴答间隔可以通过 net_ticktime 配置设置来控制。
领导者失败和消费者取消
从镜像队列消费的客户端可能希望知道他们一直消费的队列已经故障转移。 当镜像队列故障转移时,将丢失那些已发送到某个使用者的消息,因此所有未确认的消息都将使用重新传递标志集重新传递。 消费者可能希望知道这将会发生。 如果是这样,他们可以使用参数 x-cancel-on-ha-failover 设置为 true。 然后他们的消费将在故障转移时被取消,并发送一个消费者通知。 然后消费者有责任重新发布 basic.consume 以再次开始消费。
For example (in Java):
1 | Channel channel = ...; |
不同步的镜像
节点可以随时加入集群。 根据队列的配置,当节点加入集群时,队列可能会在新节点上添加镜像。 此时,新镜像将为空:它将不包含队列中的任何现有内容。 这样的镜像将接收发布到队列的新消息,因此随着时间的推移将准确地表示镜像队列的尾部。 随着消息从镜像队列中排出,新镜像缺少消息的队列头部的大小将缩小,直到最终镜像的内容与领导者的内容精确匹配。 在这一点上,镜像可以被认为是完全同步的,但重要的是要注意,这是由于客户端在排空队列的预先存在的头部方面的操作而发生的。 除非队列已显式同步,否则新添加的镜像不会提供添加镜像之前存在的队列内容的额外形式的冗余或可用性。 由于在显式同步发生时队列变得无响应,因此最好允许正在从中排出消息的活动队列自然同步,并且仅显式同步非活动队列。
启用自动队列镜像时,请考虑所涉及队列的预期磁盘数据集。 具有大量数据集(例如,数十 GB 或更多)的队列必须将其复制到新添加的镜像,这会给集群资源(如网络带宽和磁盘 I/O)带来巨大负载。 例如,这是延迟队列的常见场景。 要查看镜像状态(是否同步),请使用:
1 | $ rabbitmqctl list_queues name slave_pids synchronised_slave_pids |
可以手动同步队列:
1 | $ rabbitmqctl sync_queue {name} |
或者取消正在进行的同步:
1 | $ rabbitmqctl cancel_sync_queue {name} |
在失败时提升非同步镜像
默认情况下,如果队列的领导节点出现故障、失去与其对等方的连接或从集群中删除,则最早的镜像将被提升为新的领导者。 在某些情况下,此镜像可能不同步,这将导致数据丢失。 从 RabbitMQ 3.7.5 开始, ha-promote-on-failure 策略键控制是否允许非同步镜像提升。 当设置为 when-synced 时,它将确保不提升未同步的镜像。 。 应谨慎使用 when-synced 值。 它权衡了非同步镜像提升的安全性,以增加对队列领导者可用性的依赖。 有时队列可用性可能比一致性更重要。 when-synced 提升策略避免了由于提升非同步镜像而导致的数据丢失,但使队列可用性取决于其领导者的可用性。 在队列领导节点发生故障的情况下,队列将变得不可用,直到队列领导恢复。 如果队列领导者永久丢失,除非删除并重新声明队列,否则队列将不可用。 删除一个队列会删除它的所有内容,这意味着使用这种提升策略的领导者永久丢失等同于丢失所有队列内容。 使用 when-synced 提升策略的系统必须使用发布者确认以检测队列不可用和代理无法将消息入队。
停止节点和同步
如果您停止包含镜像队列领导者的 RabbitMQ 节点,其他节点上的某个镜像将被提升为领导者(假设有一个同步镜像;见下文)。 如果您继续停止节点,那么您将到达镜像队列没有更多镜像的点:它仅存在于一个节点上,该节点现在是其领导者。 如果镜像队列被声明为持久的,那么如果它的最后一个剩余节点关闭,队列中的持久消息将在该节点重新启动后继续存在。 通常,当您重新启动其他节点时,如果它们之前是镜像队列的一部分,那么它们将重新加入镜像队列。 然而,目前镜像没有办法知道它的队列内容是否与它重新加入的领导者有分歧(例如,这可能发生在网络分区期间)。 因此,当一个镜像重新加入一个镜像队列时,它会丢弃它已经拥有的任何持久的本地内容并开始为空。 此时它的行为与加入集群的新节点相同。
仅使用未同步的镜像停止托管队列领导者的节点
当您关闭领导节点时,所有可用镜像可能都不同步。 发生这种情况的一种常见情况是滚动集群升级。 默认情况下,RabbitMQ 将拒绝在受控leader关闭(即显式停止RabbitMQ服务或关闭OS)时提升未同步的镜像,以避免消息丢失; 相反,整个队列将关闭,就好像未同步的镜像不存在一样。 不受控制的领导者关闭(即服务器或节点崩溃,或网络中断)仍将触发未同步镜像的升级。 如果您希望在所有情况下都将队列领导者移动到未同步的镜像(即,您会选择队列的可用性而不是避免由于未同步的镜像提升而导致消息丢失),则将 ha-promote-on-shutdown 策略键设置为 always比它的同步时的默认值。 如果 ha-promote-on-failure 策略键设置为 when-synced,则即使 ha-promote-on-shutdown 键设置为 always 也不会提升未同步的镜像。 这意味着在队列领导节点发生故障的情况下,队列将变得不可用,直到领导者恢复。 如果队列领导者永久丢失,队列将不可用,除非它被删除(这也将删除其所有内容)并重新声明。 请注意, ha-promote-on-shutdown 和 ha-promote-on-failure 具有不同的默认行为。 ha-promote-on-shutdown 默认设置为 when-synced,而 ha-promote-on-failure 默认设置为 always。
所有镜像都停止时失去领导者
当队列的所有镜像都关闭时,可能会丢失队列的领导者。 在正常操作中,队列关闭的最后一个节点将成为领导者,我们希望该节点在再次启动时仍然是领导者(因为它可能收到了其他镜像没有看到的消息)。 但是,当您调用 rabbitmqctl Forgot_cluster_node 时,RabbitMQ 将尝试为每个队列找到一个当前停止的镜像,该镜像在我们忘记的节点上有其领导者,并在它再次启动时“提升”该镜像成为新的领导者。 如果有多个候选,将选择最近停止的镜像。 重要的是要了解 RabbitMQ 只能在 Forgot_cluster_node 期间提升已停止的镜像,因为任何再次启动的镜像都将清除其内容,如上面“停止节点和同步”中所述。 因此,在停止的集群中删除丢失的领导者时,您必须在再次启动镜像之前调用 rabbitmqctl forget_cluster_node。
批量同步
经典队列领导者批量执行同步。 批处理可以通过 ha-sync-batch-size 队列参数进行配置。 如果未设置任何值,则使用 mirroring_sync_batch_size 作为默认值。 早期版本(3.6.0 之前)默认一次同步 1 条消息。 通过批量同步消息,可以大大加快同步过程。 要为 ha-sync-batch-size 选择正确的值,您需要考虑:
平均消息大小
RabbitMQ 节点之间的网络吞吐量
net_ticktime 值
例如,如果您将 ha-sync-batch-size 设置为 50000 条消息,并且队列中的每条消息为 1KB,那么节点之间的每条同步消息将约为 49MB。 您需要确保队列镜像之间的网络可以容纳这种流量。 如果网络发送一批消息的时间比 net_ticktime 长,则集群中的节点可能认为它们存在网络分区。
配置同步
让我们从队列最重要的方面开始 同步: 当队列正在同步时,所有其他 队列操作将被阻塞 。 取决于多个 因素,队列可能会被同步阻塞很多 几分钟或几小时,在极端情况下甚至几天。
队列同步可以配置如下:
ha-sync-mode: 用于镜像节点代替宕机主节点并创建新节点以弥补缺失节点时,设置新节点上数据的同步策略。automatic指自动地将新主节点上数据全部同步给新节点,manual指不同步新主节点上的老数据,只同步新产生的数据。由于节点间数据同步需要耗费时间,长时间的数据同步可能会影响服务的稳定性,但通常情况下RabbitMQ的节点堆积的数据量并不大,因此RabbitMQ官方推荐使用Automatic进行数据同步。
Ha-sync-batch-size指节点间批量同步的数据量。
4.1.2. 临时队列
对于某些工作负载,队列应该是短暂的。 虽然客户可以 删除他们在断开连接之前声明的队列,这并不总是很方便。 最重要的是,客户端连接可能会失败,可能会导致未使用 资源(队列)落后。
有三种方法可以使队列自动删除:
- 独占队列(见下文)
- TTL(也在下面介绍)
- 自动删除队列
自动删除队列将在其最后一个消费者时被删除 被取消(例如,使用 basic.cancel 在AMQP 0-9-1) 或消失(关闭通道或连接,或与服务器的 TCP 连接丢失)。
如果队列从未有任何消费者,例如,当所有消费发生时 使用 basic.get 方法(“pull” API),它不会自动删除。 对于这种情况,请使用独占队列或队列 TTL。
4.1.3. 独占队列
我有许多可以执行某些操作的机器。要发起一个动作,我想发送一条消息到一个由机器ID命名的队列,例如“12345”。使用AMQP/RabbitMQ将消息发送到独占队列,为了避免其他人使用这些消息,我认为队列应该是排他性的。从我的控制器来看,如果队列在使用它的机器上声明为独占队列,我就无法声明这个队列。
只能使用独占队列(消耗、清除、删除等) 通过其声明的连接。 尝试使用排他队列 不同的连接将导致通道级异常 RESOURCE_LOCKED 带有一条错误消息,内容为无法获得对锁定队列的独占访问权 。
独占队列在声明连接关闭时被删除 或消失(例如,由于底层 TCP 连接丢失)。 他们因此 仅适用于客户端特定的瞬态。
对于使用者,当声明队列为“独占”时,当使用者根据文档断开连接时,队列将被删除。
假设队列中有等待处理的消息,并且使用者脱机,则删除队列后,此“专用”队列上的所有消息都将丢失。
4.1.4. 仲裁队列
一、概述
仲裁队列是 RabbitMQ 的一种现代队列类型,它基于 Raft 共识算法实现了一个持久的、复制的 FIFO 队列。 它从 RabbitMQ 3.8.0 开始可用。 仲裁队列类型是持久镜像队列的替代方案,专为数据安全是重中之重的一组用例而构建。 这在动机中有介绍。 它们应该被视为复制队列类型的默认选项。 与经典的镜像队列相比,仲裁队列在行为和一些限制方面也有重要差异,包括特定于工作负载的队列,例如,当消费者重复对同一消息重新排队时。 某些功能(例如有害消息处理)特定于仲裁队列。
仲裁队列旨在更安全,并提供更简单、定义明确的故障处理语义 用户在设计和操作他们的系统时应该更容易推理。
这些设计选择带有限制。 为了达到这个目标,仲裁队列采用了不同的复制 和共识协议,并放弃对某些“瞬态”性质的支持。 本指南稍后将介绍这些约束和限制。
Raft算法可以参考:https://docs.qq.com/doc/DY0VxSkVGWHFYSlZJ https://raft.github.io/
二、特征对比
| Feature | 经典队列 | 仲裁队列 |
|---|---|---|
| 持久队列性 | yes | no |
| 排他性 | yes | no |
| 消息持久性 | per message | always |
| 会员变动 | automatic | manual |
| 消息TTL | yes | no |
| 队列TTL | yes | yes |
| 队列长度 | yes | yes (除了x-overflow : reject-publish-dlx ) |
| 延迟行为 | yes | yes (通过 内存限制 功能 ) |
| 消息优先级 | yes | no |
| 消费者优先级 | yes | yes |
| 死信交换 | yes | yes |
| 遵守政策 | yes | yes (见下面的政策支持) |
| 内存报警 | yes | no |
| 有害信息处理 | no | yes |
| 全局 QoS 预取 | yes | no |
三、设计
持久队列性
常规队列可能是非持久的。 仲裁队列根据其假定的用例始终是持久的。
排他性
独占队列与其声明连接的生命周期相关联。 仲裁队列按设计是可复制且持久的,因此独占属性在其上下文中没有意义。 因此仲裁队列不能是独占的。 仲裁队列不能用作临时队列。
TTL
仲裁队列目前不支持消息 TTL,但它们支持队列 TTL。
长度限制
仲裁队列支持队列长度限制。 支持drop-head 和reject-publish 溢出行为,但它们不支持reject-publish-dlx 配置,因为Quorum 队列采用与经典队列不同的实现方法。 当仲裁队列达到最大长度限制并配置了拒绝发布时,它会通知每个发布通道,从那里谁将拒绝所有消息返回到客户端。 这意味着仲裁队列可能会因少量消息而超出其限制,因为在通知通道时可能有消息正在传输。 队列接受的附加消息的数量将根据当时正在传输的消息数量而有所不同。
死信
仲裁队列确实支持死信交换 (DLX)。
延迟模式
仲裁队列将它们的内容存储在磁盘(根据 Raft 要求)和内存中(最多配置的内存限制)。 延迟模式不适用于它们。 可以使用可以实现类似于延迟队列的行为的策略来限制仲裁队列在内存中保留的消息数量。
全球服务质量
仲裁队列不支持全局 QoS 预取,其中通道为使用该通道的所有使用者设置单个预取限制。 如果尝试从启用了全局 QoS 的通道的仲裁队列中消费,将返回通道错误。 使用每个消费者的 QoS 预取,这是几个流行客户端的默认设置。
优先事项
仲裁队列目前不支持优先级,包括消费者优先级。 要使用仲裁队列实现优先级处理,应改用多个队列; 每个优先级一个。
有害信息处理
仲裁队列通过重新传递限制支持有害消息处理。 此功能目前是 仲裁队列独有的。
政策支持
仲裁队列可以通过 RabbitMQ 策略进行配置。 下表总结了他们遵守的策略键。
| 定义键 | Type |
|---|---|
| max-length | Number |
| max-length-bytes | Number |
| overflow | “drop-head” or “reject-publish” |
| expires | Number (milliseconds) |
| dead-letter-exchange | String |
| dead-letter-routing-key | String |
| max-in-memory-length | Number |
| max-in-memory-bytes | Number |
| delivery-limit | Number |
四、用例
仲裁队列是专门设计的。 它们 并非 旨在用于解决所有问题。 它们的预期用途是用于队列存在很长时间并且对某些情况至关重要的拓扑 系统操作的各个方面,因此容错和数据安全比说, 尽可能低的延迟和高级队列功能。
示例是销售系统中的传入订单或 可能丢失消息的选举系统会产生重大影响 对系统正确性和功能的影响。
股票行情和即时通讯系统从中受益较少或根本没有法定人数队列。
发布者应该使用发布者确认,因为这是客户端可以与 法定人数队列共识系统。 发布者确认只会发出一次 已发布的消息已成功复制到法定节点,并被认为是“安全的” 在系统的上下文中。
消费者应该使用手动确认来确保消息不是 成功处理将返回到队列,以便 另一个消费者可以重新尝试处理。
何时不使用仲裁队列
在某些情况下,不应使用仲裁队列。 它们通常涉及:
- 队列的临时性质:临时或独占队列、高队列流失(声明和删除率)
- 尽可能低的延迟:底层共识算法由于其数据安全特性而具有固有的更高延迟
- 当数据安全不是优先事项时(例如,应用程序不使用 不使用手动确认并且 发布者确认)
- 非常长的队列积压(仲裁队列当前始终将所有消息都保存在内存中,最多可达 限制)
行为
仲裁队列依赖于称为 Raft 的共识协议来确保数据的一致性和安全性。
每个仲裁队列都有一个主副本( 的 领导者 Raft 术语中 )和零个或多个 次要副本(称为 追随者 )。
在集群首次形成时选举领导者,如果领导者随后 变得不可用。
有害信息处理
仲裁队列支持对有害消息的处理,即导致消费者重复重新排队传递的消息(可能是由于消费者失败),使得消息永远不会被完全消耗并得到肯定的确认,以便可以被 RabbitMQ 标记为删除. 仲裁队列会跟踪未成功传递尝试的次数,并将其公开在任何重新传递的邮件中包含的“x-delivery-count”标头中。 可以使用策略参数传递限制为队列设置传递限制。 当一条消息返回的次数超过限制时,该消息将被丢弃或死信(如果配置了 DLX)
重复重新排队
内部仲裁队列是使用日志实现的,其中所有操作包括 消息被持久化。 为了避免这个日志变得太大,它需要 定期截断。 能够截断日志的一部分所有消息 在该部分需要承认。 连续不断的使用模式 拒绝或取消将 相同的消息 requeue 标志设置为 true 来 可能导致日志以无限方式增长并最终填满 上磁盘。
具体使用方式可以参考官方文档:https://www.rabbitmq.com/quorum-queues.html
4.1.5. 延迟队列
概述
从 RabbitMQ 3.6.0 开始,broker 有了延迟队列的概念——队列尽可能早地将它们的内容移动到磁盘,并且只在消费者请求时才将它们加载到 RAM 中。 延迟队列的主要目标之一是能够支持非常长的队列(数百万条消息)。 由于各种原因,队列可能会变得很长:
消费者离线/崩溃/停机维护
消息入口突然激增,生产者超过消费者
消费者比平时慢
默认情况下,队列保留消息的内存缓存,当消息发布到 RabbitMQ 时,该缓存已填满。 这种缓存的想法是能够尽可能快地将消息传递给消费者。 请注意,持久消息可以在进入代理时写入磁盘并同时保存在 RAM 中。
每当代理认为它需要释放内存时,来自该缓存的消息将被分页到磁盘。 将一批消息分页到磁盘需要时间并阻塞队列进程,使其在分页时无法接收新消息。 尽管 RabbitMQ 的最新版本改进了分页算法,但对于队列中可能需要调出数百万条消息的用例,这种情况仍然不理想。 延迟队列尝试尽可能早地将消息移动到磁盘。 这意味着在正常操作的大多数情况下,RAM 中保留的消息要少得多。 这是以增加磁盘 I/O 为代价的。
设置延迟队列
可以通过以下方式使队列以 默认 模式或延迟模式运行:
- 通过设置模式 queue.declare 参数
- 应用队列策略
当 策略 和队列参数都指定队列模式时,队列参数的优先级高于策略值。
如果在声明时通过可选参数设置队列模式, 只能通过删除队列并稍后使用不同的参数重新声明来更改它。
队列模式可以通过提供带有指定所需模式的字符串的 x-queue-mode 队列声明参数来设置。 有效模式是:
- “default”
- “lazy”
如果在声明期间未指定模式,则假定为“默认”。 默认模式是 3.6.0 之前版本的代理中已经存在的行为,因此在这方面没有重大更改。 这个 Java 示例声明了一个队列模式设置为“lazy”的队列:
1 | Map<String, Object> args = new HashMap<String, Object>(); |
使用策略 要使用策略指定队列模式,请将键 queue-mode 添加到策略定义中,例如:
| rabbitmqctl | rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues |
|---|
磁盘利用率
延迟队列会尽快将其消息移动到磁盘,即使消息已发布由出版商暂时性的。 这通常会导致更高的磁盘 I/O 利用率。
常规队列将 消息在内存中保留更长时间。 这将导致延迟的磁盘 I/O 更不均匀(有更多的尖峰) 因为需要一次将更多数据写入磁盘。
内存利用率
虽然不可能每次使用都提供准确的数字 案例,这是一个简单的测试,展示了 RAM 的差异 常规队列和延迟队列之间的利用率:
| 消息数 | 消息体大小 | 消息类型 | 生产者 | 消费者 |
|---|---|---|---|---|
| 1,000,000 | 1,000 字节 | 执着的 | 1 | 0 |
,默认队列和惰性队列的 RAM 利用率 后 摄取上述消息 :
| 队列模式 | 队列进程内存 | 内存中的消息 | 消息使用的内存 | 节点内存 |
|---|---|---|---|---|
| 默认 | 257 MB | 386,307 | 368 MB | 734 MB |
| 延迟 | 159 KB | 0 | 0 | 117 MB |
两个队列都保留了 1,000,000 条消息并使用了 1.2 GB 的磁盘空间。
当优先考虑保持节点内存使用率低时,延迟队列是合适的 更高的磁盘 I/O 和磁盘利用率是可以接受的。 延迟队列还有其他方面 应该考虑到这一点。
具有混合消息大小的延迟队列
如果前 消息中的所有消息 10,000 条 都低于 queue_index_embed_msgs_below 值,其余都在这个之上的值,只有前 10,000 个 将加载到节点上的内存中启动。
当一个节点正在运行并处于正常运行状态时,延迟队列会将所有消息保存在磁盘上, 唯一的例外是传输中的消息。
当 RabbitMQ 节点启动时,所有队列(包括延迟队列)将最多将 加载 16,384 条 消息 到 RAM 中。 如果 队列索引嵌入 启用了 ( queue_index_embed_msgs_below 配置参数大于 0), 这些消息的有效载荷也将加载到 RAM 中。
例如,一个有 的惰性队列 20,000 条 消息( 4,000 每条 字节) 会将 加载 16,384 条 消息 到内存中。 这些消息将使用 63MB 的系统内存。 队列进程将使用另外 8.4MB 的系统内存,使总数刚刚超过 70MB 。
这是容量规划的一个重要考虑因素,如果 RabbitMQ 节点内存受限,或者是否有很多惰性队列 托管在节点上。
重要的是要记住,在内存或磁盘空间方面配置不足的 RabbitMQ 节点将无法启动。
更多详细介绍可以参考官方文档:https://www.rabbitmq.com/lazy-queues.html
4.1.6. 死信队列
概述
死信队列介绍:
- 死信队列:DLX,
dead-letter-exchange - 利用DLX,当消息在一个队列中变成死信
(dead message)之后,它能被重新publish到另一个Exchange,这个Exchange就是DLX
消息变成死信有以下几种情况:
该消息被否定确认,由消费者使用 basic.reject 或 basic.nack 与 requeue 参数设置为 false 。
由于消息过期每条消息的TTL
消息被丢弃因为其队列超出了长度限制
请注意,队列的到期不会成为死信其中的消息。
死信处理过程:
- DLX也是一个正常的Exchange,和一般的Exchange没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。
- 当这个队列中有死信时,RabbitMQ就会自动的将这个消息重新发布到设置的Exchange上去,进而被路由到另一个队列。
- 可以监听这个队列中的消息做相应的处理。
配置
对于任何给定的队列,客户端可以使用队列的参数 ,或在服务器中使用策略 。 在里面策略和参数都指定 DLX 的情况, 参数中指定的参数会否决策略中指定的参数。 建议使用策略进行配置,因为它允许 DLX 不涉及应用程序重新部署的重新配置。
要使用策略指定 DLX,请添加键“死信交换” 到政策定义。 例如:
| rabbitmqctl | rabbitmqctl set_policy DLX ".*" '{"dead-letter-exchange":"my-dlx"}' --apply-to queues |
|---|
上述策略将 DLX“my-dlx”应用于所有队列。 这只是一个例子,在实践中不同的队列集可能会使用不同的死字设置(或根本没有) 。类似地,可以通过添加来指定显式路由键 策略的关键“死信路由密钥”。
也可以使用管理插件定义策略,请参阅 该 政策文件 的更多细节。
使用可选队列参数的配置要为队列设置死信交换,请指定 可选的 x-dead-letter-exchange 参数,当 声明队列。 该值必须是交换名称 同一个虚拟主机:
1 | channel.exchangeDeclare("some.exchange.name", "direct"); |
上面的代码声明了一个名为的新交换 some.exchange.name 并设置这个新的交换 作为新创建队列的死信交换。 请注意,在以下情况下不必声明交换队列,但到时它应该存在消息需要是死信; 如果它不见了,那么消息将被悄悄丢弃。
您还可以指定要在以下情况下使用的路由键死信消息。 如果未设置,则将使用消息自己的路由密钥。
1 | args.put("x-dead-letter-routing-key", "some-routing-key"); |
当指定了死信交换时,除了 通常配置声明队列的权限,用户 需要对该队列具有读取权限并写入 死信交换的权限。 权限是 在排队申报时验证。
运行说明:
启动消费端,此时查看管控台,新增了两个Exchange,两个Queue。在test_dlx_queue上我们设置了DLX,也就代表死信消息会发送到指定的Exchange上,最终其实会路由到dlx.queue上。这里的dlx.queue就是上面的some.exchange.name
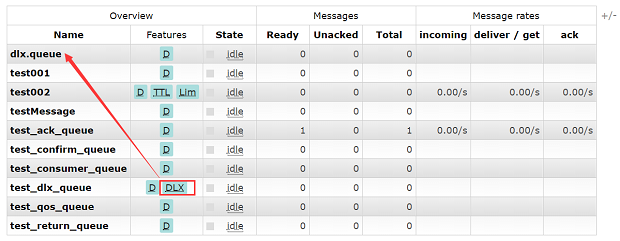
此时关闭消费端,然后启动生产端,查看管控台队列的消息情况,test_dlx_queue的值为1,而dlx_queue的值为0。
10s后的队列结果如图,由于生产端发送消息时指定了消息的过期时间为10s,而此时没有消费端进行消费,消息便被路由到死信队列中。
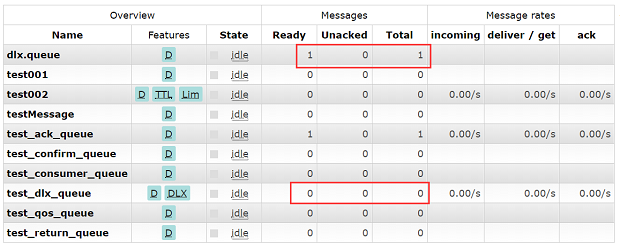
实际环境我们还需要对死信队列进行一个监听和处理,当然具体的处理逻辑和业务相关,这里只是简单演示死信队列是否生效。
作者:渃汐湲 部分转载于:https://www.jianshu.com/p/986ee5eb78bc
更多详细信息可以参考官方文档:https://www.rabbitmq.com/dlx.html
4.1.7. 优先级队列
概述
从版本 RabbitMQ 在核心中具有优先队列实现 3.5.0 开始, 。 任何队列都可以使用客户端提供的 变成优先队列 可选参数 (但是,与使用可选参数而非策略的其他功能不同)。 该实现支持有限数量的优先级:255。建议使用 1 到 10 之间的值。
要声明优先级队列,请使用 x-max-priority 可选队列参数。 这个参数应该是一个介于 1 到 255 之间的正整数, 指示队列应支持的最大优先级。 例如, 使用 Java 客户端:
1 | Channel ch = ...; |
每个优先级都有一些内存和磁盘成本 每个队列, 还有额外的 CPU 成本,尤其是消费时,因此您可能不希望大量创建。没有消息优先级属性的被视为优先级为0。具有优先级的消息是 高于队列的最大值被视为以最高优先级发布。
与其他功能的交互
一般来说,优先级队列具有标准队列的所有特征 RabbitMQ 队列:它们支持持久性、分页、镜像、 等等。 开发人员应该进行一些交互 意识到。 应该过期的消息 仍然会 只从队列的头部过期。 这意味着不像对于普通队列,即使是每个队列的 TTL 也会导致过期 低优先级的消息卡在未过期的后面 更高优先级的。 这些消息永远不会被传递, 但它们会出现在队列统计中。 设置了最大长度的队列 队列 将像往常一样从的头部丢弃消息排队强制执行限制。 这意味着更高的优先级消息可能会被丢弃,以让位于较低优先级的消息这可能不是您所期望的。
更多详细介绍可以查看官方文档:https://www.rabbitmq.com/priority.html
4.2. 可靠性交付
4.2.1. 概述
什么会失败?
基于消息传递的系统根据定义是分布式的,并且可能会失败 不同的,有时是微妙的方式。 网络连接问题和拥塞可能是最常见的故障类别。 不仅网络会出现故障, 防火墙还会中断连接 他们认为是空闲的,网络故障需要时间来检测 。 除了连接失败,服务器和客户端 应用程序可能会遇到硬件故障(或软件可能会崩溃) 随时。 此外,即使客户端应用程序继续运行, 逻辑错误会导致通道或连接错误 ,从而迫使客户端建立新的通道或连接并从问题。 当然,这个失败的清单并不详尽。 它不包括更细微的故障 例如遗漏失败(未能在可预测的时间内做出响应), 性能下降、耗尽系统资源的恶意或有缺陷的应用程序 等等。
连接失败
在客户端和RabbitMQ节点之间的网络连接失败的情况下, 客户端将需要与代理建立新连接。 上打开的任何频道 以前的连接将自动关闭,这些将 也需要重新开放。 一般来说,当连接失败时,客户端会收到通知 连接抛出异常(或类似的语言结构)。 大多数客户端库都提供了自动从连接中恢复的功能失败。 对于这种固执的恢复不适合的情况,应用 开发者可以通过定义连接失败来实现自己的恢复 事件处理程序。 请参阅客户端文档,例如 Java 和 .NET 客户端指南 ,了解更多信息。
致谢和确认
当连接失败时,消息可能在客户端和 服务器 - 它们可能正在任何一侧被解码或编码, 坐在 TCP 堆栈缓冲区中,或者在线上传输。 在此类事件中传输中的消息不会被传递——它们会 需要重传。
确认让服务器和 客户知道何时执行此操作。 确认可以双向使用 - 允许消费者 向服务器表明它已收到和/或处理了交付 并允许服务器向 出版商。 它们被称为消费者确认和发布者确认。 而 TCP 确保数据包已被传送到连接对等方,并且将 重传直到它们是,只处理网络上的故障层。 确认和确认表明消息已被由对等应用程序接收并执行 。 确认既表示收到消息,也表示所有权转移,其中 接收方对此承担全部责任。 因此,确认具有语义。 一个消费应用不应该确认消息,直到它完成了它需要的任何事情 处理它们:将它们记录在数据存储中、转发它们或执行任何其他操作。 一旦这样做,经纪人是免费的 标记要删除的交付。 同样,broker 会在收到消息后确认消息对他们负责。 使用确认保证至少一次交货。 没有确认,消息丢失是可能在发布和消费操作期间,以及只最多一次保证交货。
用心跳检测死 TCP 连接
在某些类型的网络故障中,丢包可能意味着 中断的 TCP 连接需要相当长的时间(大约 11 例如,Linux 上默认配置的分钟数)为 被操作系统检测到。 AMQP 0-9-1 提供了一个 心跳功能 保证应用层 及时发现连接中断(以及 完全没有反应的同行)。 心跳也可以防御 某些可能终止“空闲” TCP 的网络设备 连接。 有关 请参阅 心跳指南 详细信息, 。
Broker端的数据安全
为了避免在broker中丢失消息,队列和消息必须能够应对代理重启,代理硬件故障, 在极端 甚至 情况下 经纪人崩溃。
为了确保消息和代理定义在重启后仍然存在,我们 需要确保它们在磁盘上。 AMQP标准有一个概念 交换、队列和持久消息的持久性, 要求持久对象或持久消息将在 重新开始。 有关与耐久性有关的特定标志的更多详细信息 和坚持可以在 队列指南 。
集群和消息复制
节点集群 提供冗余并且可以容忍单个节点的故障。 在 RabbitMQ 集群中,所有定义(交换、绑定、用户等)都在整个集群中复制 簇。 队列的行为不同,默认情况下仅驻留在 单个节点,但可以配置为跨多个复制(镜像) 节点。 队列保持可见并可从所有节点访问 他们的领导副本位于哪个节点。
镜像队列跨多个配置的集群复制它们的内容 节点。 当一个节点发生故障时,该节点上托管有领导副本的队列会进行提升 (新领导人选举)。 此场景中的关键可靠性标准是是否有副本(队列镜像) 有资格晋升 。
独占队列与其连接的生命周期相关,因此永远不会被镜像 根据定义,节点重启后将无法生存。
连接到故障节点的消费者必须像往常一样恢复。 曾经的消费者 当一个新的leader副本连接到不同的节点时,RabbitMQ会自动重新注册 因为队列被选举了。 那些消费者不需要执行恢复 (例如重新连接或重新订阅)。
发布方的数据安全
使用确认时,生产者从通道或连接中恢复失败应该重传任何没有收到经纪人的需要确认的消息。 有一种可能这里的消息重复,因为代理可能发送了一个从未到达生产者的确认(由于网络故障, 等等)。 因此消费者应用程序需要执行 重复数据删除或以幂等方式处理传入消息。
1 | 简单说说幂等性 |
确保消息被路由
在某些情况下,生产者必须确保 他们的消息被路由到队列(虽然不总是 - 在 在发布订阅系统的情况下,生产者只会发布,如果没有消费者有兴趣删除消息是正确的)。
为了确保消息被路由到单个已知队列,生产者可以只声明一个目标队列并直接发布到它。 如果消息可能以更复杂的方式路由,但生产者仍然 需要知道他们是否到达至少一个队列,它可以设置强制上的标志 basic.publish ,确保 那一个 basic.return (包含一个回复代码和一些 文本解释)如果没有队列,将被发送回客户端 适当绑定。 有关 请参阅 发布者指南 详细信息, 。
生产者还应该注意,在发布到集群节点时,如果绑定到交换的一个或多个目标队列具有集群中的镜像,可能会导致延迟由于副本之间的流量控制,节点之间的网络故障和队列领导者副本。 见 节点间心跳导向 为 更多细节。
消费者侧的数据安全
在网络故障(或节点故障)的情况下,消息可以重新交付 ,消费者必须准备好处理他们过去消费过的交付。 建议消费者实施 被设计为幂等的而不是明确的执行重复数据删除。 如果消息被传递给消费者然后重新排队,要么自动 由 RabbitMQ的或相同或不同的消费者,RabbitMQ的将设置 重新传递 的标志 当它再次交付时。 这是消费者 的提示可能已经看到这个消息之前。 这不能保证,因为原始交付可能没有送达任何消费者 由于网络或消费者应用程序故障。 如果重新传递未设置标志,则不能保证看到之前的消息。 因此,如果消费者发现重复数据删除的成本更高 消息或以幂等方式处理它们,它只能这样做对于消息重新传递设置了标志的 。
无法处理的交货
如果消费者确定它无法处理消息,那么它可以使用拒绝它 basic.reject 或 basic.nack 方法 ,或者要求服务器重新排队,在这种情况下,服务器可能配置为死信队列)。
消费者取消通知
当消费者正在消费的队列被删除时,RabbitMQ 将通知消费者 。 这样的消费者必须采取行动来恢复,无论是从不同的队列消费还是重新声明,它最初在安全和适当的时候使用的那个。
更多可靠性交付可以参考官网:https://www.rabbitmq.com/reliability.html
4.2.2. 消费者和生产者确认
使用消息代理(如 RabbitMQ)的系统由 定义分布。 由于协议方法(消息)发送 不能保证到达对等方或被成功处理 通过它,发布者和消费者都需要一种机制 交货和处理确认。 几个消息 RabbitMQ 支持的协议提供了这样的特性。
交货标识符:交货标签
在我们继续讨论其他主题之前,重要的是 解释如何识别交付(和确认表明他们各自的交付)。 当一个消费者 (订阅)已注册,消息将被传递 (推送)由 RabbitMQ 使用 basic.deliver 方法。 该方法带有一个 交付标签 ,它是唯一标识通道上的交付。
交付标签正单调增长 整数并由客户端库提供。 确认交付的客户端库方法采用交付标签 作为论据。
由于交付标签的范围是每个渠道,交付必须是在收到它们的同一频道上确认。 承认 在不同的频道上将导致“未知的交付标签”协议 异常并关闭通道。
最大交付标签
Delivery tag 是一个 64 位长的值,因此它的最大值 是 9223372036854775807 。 由于交付标签的范围是每个渠道, 发布者或消费者不太可能会遇到这种情况 实践中的价值。
更多详细介绍可以参考官方文档:https://www.rabbitmq.com/confirms.html
否定确认和重新排队交货
有时消费者无法立即处理交付,但其他实例可能 能够。 在这种情况下,可能需要重新排队并让另一个消费者接收 并处理它。 basic.reject 和 basic.nack 是两个协议 用于此的方法。
这些方法通常用于否定确认交付。 这样的交付可以 被经纪人丢弃或重新排队。 此行为由 控制 requeue 字段 。 当该字段设置为 true 时 ,经纪人将重新排队交货(或多个 交货,正如稍后将解释的)具有指定的交货标签。
当消息重新排队时,它将被放置到其原始位置 如果可能,在其队列中的位置。 如果不是(由于并发 来自其他消费者的交付和确认 多个消费者共享一个队列),消息将被重新排队 到更靠近队列头的位置。
生产者事务
RabbitMQ通过生产者事务和生产者确认两个方法解决Server产生的数据不可靠问题。 生产者事务的基本原理是采用select和commit指令包裹publish,在消息生产者publish数据之前执行select操作,相当于begin transaction事务开始,在执行若干个publish操作后,再执行commit操作,相当于提交事务。根据tcp包的有序性,commit包成功接收意味着commit包之前的包也成功接收。因此,收到从Client Publisher传递过来的commit包意味着该commit包之前的所有publish包都已成功接收,即所有消息都成功接收。然而,commit包只有等到Server端的fsync操作执行完毕时才返回,因此生产者事务的效率较低,通常只在有批量publish操作时才使用生产者事务模式。也就是说,客户端将消息累计起来批量发送,以降低fsync操作带来的性能损失。此外,在进程中累计消息也存在风险,累计的消息可能由于进程挂掉而丢失。总的来说,生产者事务由于性能缺点不被RabbitMQ官方推荐。
Broker何时会确认发布的消息?
对于不可路由的消息,broker 会发出一个确认 一旦交换验证消息将不会路由到任何队列 (返回一个空的队列列表)。 如果消息也是发布为强制性, basic.return 被发送 在 之前给客户端 basic.ack 。 相同对于否定确认( 也是如此 basic.nack ) 。 对于可路由的消息, basic.ack 在 消息已被所有队列接受。 对于坚持消息路由到持久队列,这 意味着持久化到磁盘 。 对于镜像队列,这意味着所有 镜子已经接受了这个消息。
持久消息的确认延迟
basic.ack 用于路由到一个持久消息 持久化队列将在持久化消息后发送到 盘。 RabbitMQ 消息存储将消息持久化到磁盘 间隔(几百毫秒)后分批, 尽量减少 fsync(2) 调用的次数,或者当队列空闲时。 这意味着在恒定负载下,延迟为 basic.ack 可以达到几百毫秒。 至 提高吞吐量,强烈建议应用程序 异步处理确认(作为流)或发布 批量消息并等待未完成的确认。 最正确 用于此的 API 因客户端库而异。
备用路由
有时希望让客户端处理消息 交易所无法路由(即要么是因为 没有绑定队列或没有匹配 绑定)。 这方面的典型例子是:
检测客户端何时意外或恶意发布无法路由的消息
“或者其他”路由语义,其中一些消息是专门处理的,其余的由通用处理程序处理
备用交换(“AE”)是解决这些用例的功能。
这是定义替代交换的推荐方法。
要使用策略指定 AE,请添加键“alternate-exchange” 到策略定义并确保该策略与交易所匹配 需要定义的AE。 例如:
1 | rabbitmqctl set_policy AE "^my-direct$" '{"alternate-exchange":"my-ae"}' |
每当与配置的 AE 交换无法路由消息到任何队列,它将消息发布到指定的 AE 反而。 如果该 AE 不存在,则会记录警告。 如果 AE 不能路由消息,它反过来发布消息到它的 AE,如果它配置了一个。 这个过程继续 直到消息被成功路由,结束 到达 AE 链,或遇到 AE 已经尝试路由消息。
例如,如果我们向“my-direct”发布一条消息 ‘key1’ 的路由键然后该消息被路由到 ‘routed’ 队列,符合标准 AMQP 行为。 但是,当发布消息到 ‘my-direct’ 路由键为 ‘key2’,被丢弃的消息通过我们配置的路由 AE 到“备用路由”队列。
AE 的行为纯粹与路由有关。 如果一条消息通过 AE 路由,出于以下目的,它仍然算作路由 ‘mandatory’ 标志,消息不变。
mandatory和immediate是AMQP协议中basic.publish方法中的两个标识位,它们都有当消息传递过程中不可达目的地时将消息返回给生产者的功能。对于刚开始接触RabbitMQ的朋友特别容易被这两个参数搞混,这里博主整理了写资料,简单讲解下这两个标识位。
mandatory 当mandatory标志位设置为true时,如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue,那么会调用basic.return方法将消息返回给生产者(Basic.Return + Content-Header + Content-Body);当mandatory设置为false时,出现上述情形broker会直接将消息扔掉。
immediate 当immediate标志位设置为true时,如果exchange在将消息路由到queue(s)时发现对于的queue上没有消费者,那么这条消息不会放入队列中。当与消息routeKey关联的所有queue(一个或者多个)都没有消费者时,该消息会通过basic.return方法返还给生产者。
概括来说,mandatory标志告诉服务器至少将该消息route到一个队列中,否则将消息返还给生产者;immediate标志告诉服务器如果该消息关联的queue上有消费者,则马上将消息投递给它,如果所有queue都没有消费者,直接把消息返还给生产者,不用将消息入队列等待消费者了。
网络异常、机器异常、程序异常等多种情况都可能导致业务丢失消息。对消息进行确认可以解决消息的丢失问题,确认成功意味着消息已被验证并正确处理。
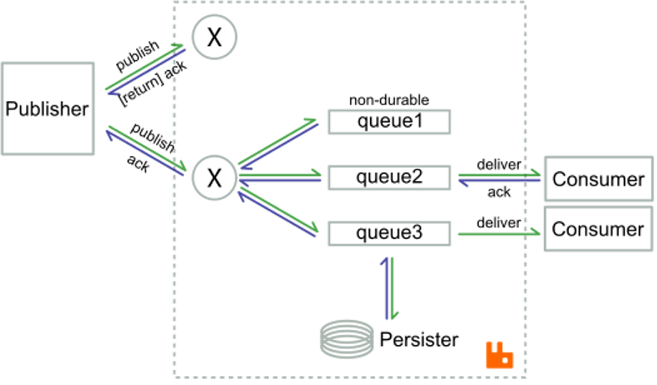
RabbitMQ 使用生产消息确认、消费者确认机制来提供可靠交付功能。
- 生产消息确认:生产者向MQ发送消息后,等待 MQ 回复确认成功;否则生产者向 MQ 重发该消息。此过程可以异步进行,生产者持续发送消息,MQ 将消息批量处理后再回复确认;生产者通过识别确认返回中的 ID 来确定哪些消息被成功处理。
- 消费者确认:MQ 向消费者投递消息后,等待消费者回复确认成功;否则 MQ 重新向消费者投递该消息。该过程同样可以异步处理,MQ 持续投递消息,消费者批量处理完后回复确认。
可以看出 RabbitMQ/AMQP 提供的是“至少一次交付”(at-least-once delivery),异常情况下,消息会被重复投递或消费。
为提高消息的可靠性,保证在 RabbitMQ 重启服务不可用时,要对收到的消息持久化写入磁盘。在收到消息时 RabbitMQ 将消息写入文件中,当写入达到一定数量或一定时间周期后 RabbitMQ 将文件落盘存储。
生产消息确认就是在消息落盘存储后,MQ向生产者回复已落盘存储的消息 ID。
4.3. 生产者消费者
生产者消息运转
1.Producer先连接到Broker,建立连接Connection,开启一个信道(Channel)。
2.Producer声明一个交换器并设置好相关属性。
3.Producer声明一个队列并设置好相关属性。
4.Producer通过路由键将交换器和队列绑定起来。
5.Producer发送消息到Broker,其中包含路由键、交换器等信息。
6.相应的交换器根据接收到的路由键查找匹配的队列。
7.如果找到,将消息存入对应的队列,如果没有找到,会根据生产者的配置丢弃或者退回给生产者。
8.关闭信道。
9.关闭连接。
消费者接收消息过程
1.Producer先连接到Broker,建立连接Connection,开启一个信道(Channel)。
2.向Broker请求消费响应的队列中消息,可能会设置响应的回调函数。
3.等待Broker回应并投递相应队列中的消息,接收消息。
4.消费者确认收到的消息,ack。
5.RabbitMq从队列中删除已经确定的消息。
6.关闭信道。
7.关闭连接。
信道预取设置 (QoS)
因为消息被发送(推送)给客户端 异步地,通常有不止一条消息“在 传输”在任何给定时刻的频道上。此外, 来自客户的手动确认本质上也是异步的。 所以有一个滑动窗口 未确认的交付标签。 开发商会 通常喜欢限制此窗口的大小以避免 消费者端的无界缓冲问题。 这个完成了 通过使用设置“预取计数”值 basic.qos 方法。 该值定义了最大值 允许的未确认交付的数量 渠道。 一旦数量达到配置的数量, RabbitMQ 将停止在通道上传递更多消息 除非至少有一个消费完成。 (值 0 被视为无限,允许任何数字 未确认的消息。)
值得重申的是,交付流程和 手动客户确认完全是异步。 因此,如果在传输中更改预取值时,待交付的消息可能暂时超过 预取计数通道上未确认的消息。
确认模式和 QoS 预取值具有重要意义 对消费者吞吐量的影响。 一般来说,增加 预取将提高消息传递到 消费者。 自动确认模式产生最佳效果 可能的交货率。 然而,在这两种情况下,数量 已发送但尚未处理的消息也将 增加,从而增加消费者 RAM 消耗。
应谨慎使用自动确认模式或无限预取的手动确认模式。 消费大量消息而不确认的消费者将导致 它们所连接的节点上的内存消耗增长。 寻找 一个合适的预取值是一个反复试验的问题,并且会有所不同 工作量到工作量。 100 到 300 范围内的值通常提供最佳吞吐量,并且不会冒使消费者不知所措的重大风险。 较高的值通常会 遇到收益递减规律。
**共享限制的多个消费者 **
AMQP 0-9-1 规范没有解释如果你 调用 basic.qos 用不同的方法多次 全球 价值观。 RabbitMQ 将此解释为含义 两个预取限制应该独立于 彼此; 消费者只会在两者都没有时才会收到新消息 已达到未确认消息的限制。
例如:
1 | Channel channel = ...; |
这两个消费者永远只有 15 个未被确认 它们之间的消息,每个最多 10 条消息 消费者。 这将比上面的例子慢,因为 通道和通道之间协调的额外开销 强制执行全局限制的队列。
消费者优先事项
消费者优先级允许您确保高优先级 消费者在活动时接收消息,带有消息 只有在高优先级时才会去低优先级消费者 消费者消费。
4.4. 集群
4.4.1. 概述
RabbitMQ 集群是一个或多个逻辑分组几个节点,每个节点共享用户,虚拟主机, 队列、交换、绑定、运行时参数和其他分布式状态。
集群的组成可以动态改变。 所有 RabbitMQ 代理开始时都运行在一个 节点。 这些节点可以加入集群,并且 随后又变回个人经纪人。
RabbitMQ 节点使用域名相互寻址,无论是短域名还是标准域名 (FQDN)。 因此,所有集群成员的主机名必须可从所有集群节点以及可能使用 rabbitmqctl 等命令行工具的机器解析。
主机名解析可以使用任何标准操作系统提供的 方法:
- DNS记录
- 本地主机文件(例如 /etc/hosts )
RabbitMQ 运行所需的所有数据/状态代理在所有节点上复制。一些分布式系统 有领导者和追随者节点。对于 RabbitMQ 来说,通常不是这样的。 RabbitMQ 集群中的所有节点都是对等的:RabbitMQ 核心中没有特殊节点。
RabbitMQ 节点和 CLI 工具(例如 rabbitmqctl )使用 cookie 来确定他们是否被允许与 彼此。 要使两个节点能够通信,它们必须具有 相同的共享秘密称为 Erlang cookie。 饼干是 只是一串最多 255 个字符的字母数字字符。 它通常存储在本地文件中。 该文件必须仅 所有者可以访问(例如具有 UNIX 权限 600 或类似的 )。 每个集群节点必须具有相同的 cookie。 如果文件不存在,Erlang VM 会尝试创建 一个随机生成的值,当 RabbitMQ 服务器 启动。 在开发中使用此类生成的 cookie 文件是合适的 仅环境。 由于每个节点都会独立生成自己的值, 这种策略在 并不真正可行 集群环境中 。
假设所有集群成员可用,客户端可以连接到任何节点和 执行任何操作。 节点将操作路由到仲裁队列领导者或队列领导者副本对客户透明。 使用所有支持的消息传递协议,一个客户端只连接到一个节点 一次。 如果节点出现故障,客户端应该能够重新连接到不同的节点,恢复它们的拓扑结构并继续操作。 为了因此,大多数客户端库都接受端点列表(主机名或 IP 地址) 作为连接选项。 主机列表将在初始连接期间使用 以及连接恢复(如果客户端支持)。
这种“集群范围”的命令通常会联系一个节点 。首先,发现集群成员并联系他们检索并组合它们各自的状态。 例如, rabbitmqctl list_connections 将联系所有 节点,检索它们的 AMQP 0-9-1 和 AMQP 1.0 连接, 并将它们全部显示给用户。 用户没有 手动联系所有节点。 假设不变 集群的状态(例如没有连接被关闭或 打开),两个 CLI 命令针对两个不同的 一个接一个的节点会产生相同的或 语义相同的结果。 但是,“节点本地”命令不会产生 相同的结果,因为两个节点很少有相同的状态:至少他们的 节点名称会有所不同!
RabbitMQ brokers 容忍个别失败节点。 节点可以随意启动和停止, 只要他们可以联系一个集群成员节点 停机时已知。
每个节点都存储和聚合自己的指标和统计数据,并提供 API 其他节点访问它。 一些统计数据是集群范围的,其他统计数据特定于单个节点。
在节点名称或主机名更改后重新加入的节点可以作为 启动 空白节点 如果它的数据目录路径因此而改变。 此类节点将无法重新加入集群。 当节点离线时,它的对等节点可以被重置或使用空白数据目录启动。 在这种情况下,恢复节点也将无法重新加入其对等节点,因为内部数据存储集群 身份将不再匹配。
RabbitMQ集群方案
RabbitMQ的Cluster模式分为两种:
- 普通模式
- 镜像模式
Cluster普通模式:
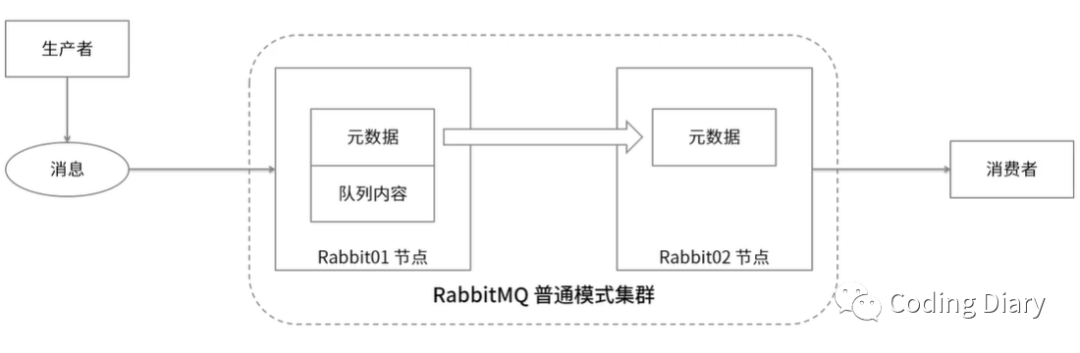
元数据包含以下内容:
- 队列元数据:队列的名称及属性
- 交换器:交换器的名称及属性
- 绑定关系元数据:交换器与队列或者交换器与交换器
- vhost元数据:为vhost内的队列,交换器和绑定提供命名空间及安全属性之间的绑定关系
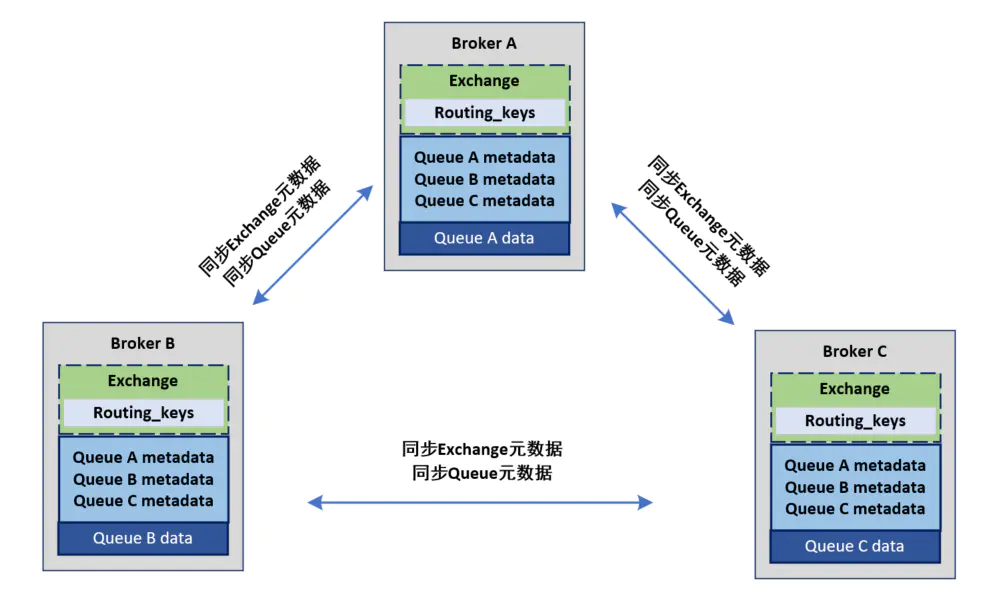
对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
队列所在的节点称为宿主节点。
队列创建时,只会在宿主节点创建队列的进程,宿主节点包含完整的队列信息,包括元数据、状态、内容等等。因此,只有队列的宿主节点才能知道队列的所有信息。
队列创建后,集群只会同步队列和交换器的元数据到集群中的其他节点,并不会同步队列本身,因此非宿主节点就只知道队列的元数据和指向该队列宿主节点的指针。
假如现在一个客户端需要对Queue A进行发布或者订阅,发起与集群的连接,有两种可能的场景:
- 如果客户端连接至Broker A,Broker A是Queue A的宿主节点,那么此时的集群中的消息收发只与Broker A相关。
- 如果客户端连接至Broker B或Broker C,不是Queue A的宿主节点,那么此时的Broker主要起了一个路由转发作用,根据这两个节点上的元数据转发至Broker A上。
由于节点之间存在路由转发的情况,对延迟非常敏感,应当只在本地局域网内使用,在广域网中不应该使用集群,而应该用Federation或者Shovel代替。
但该方案也有显著的缺陷,那就是不能保证消息不会丢失。当集群中某一节点崩溃时,崩溃节点所在的队列进程和关联的绑定都会消失,附加在那些队列上的消费者也会丢失其订阅信息,匹配该队列的新消息也会丢失。比如A为宿主节点,当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,然后就没有然后了……
Cluster多机多节点部署:多机多节点是指在每台机器中部署一个RabbitMQ服务节点,进而由多个机器组成一个RabbitMQ集群
Cluster单机多节点部署:由于某些因素的限制,有时候不得不在单台物理机器上去创建一个多RabbitMQ服务节点的集群。或者只想要实验性的验证集群的某些特性,也不需要浪费过多的物理机器去实现。需要为每个RabbitMQ服务节点设置不同的端口号和节点名称来启动相应的服务。
Cluster镜像模式:
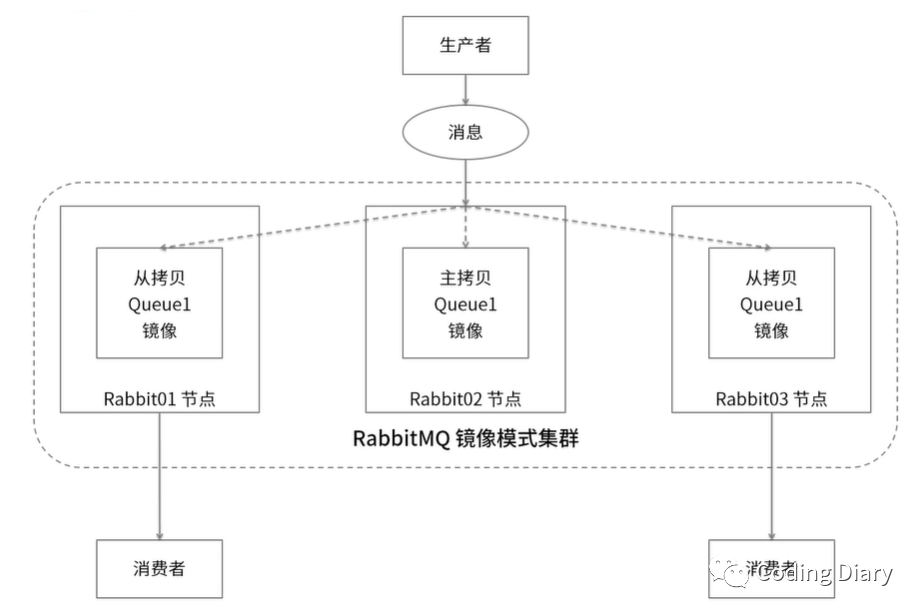
镜像模式的集群是在普通模式的基础上,通过policy来实现,使用镜像模式可以实现RabbitMQ的高可用方案
镜像模式队列由两部分组成:一部分是AMQQueue,负责AMQP协议相关的消息处理,即接收生产者发布的消息、向消费者投递消息、处理消息confirm、acknowledge等等;另一部分是BackingQueue,它提供了相关的接口供AMQQueue调用,完成消息的存储以及可能的持久化工作等。
镜像队列基本上就是一个特殊的BackingQueue(备份队列),它内部包裹了一个普通的BackingQueue做本地消息持久化处理,在此基础上增加了将消息和ack复制到所有镜像的功能。所有对mirror_queue_master的操作,会通过组播GM(下面会讲到)的方式同步到各slave节点。GM负责消息的广播,mirror_queue_slave负责回调处理,而master上的回调处理是由coordinator负责完成。mirror_queue_slave中包含了普通的BackingQueue进行消息的存储,master节点中BackingQueue包含在mirror_queue_master中由AMQQueue进行调用。
消息的发布(除了Basic.Publish之外)与消费都是通过master节点完成。master节点对消息进行处理的同时将消息的处理动作通过GM广播给所有的slave节点,slave节点的GM收到消息后,通过回调交由mirror_queue_slave进行实际的处理。
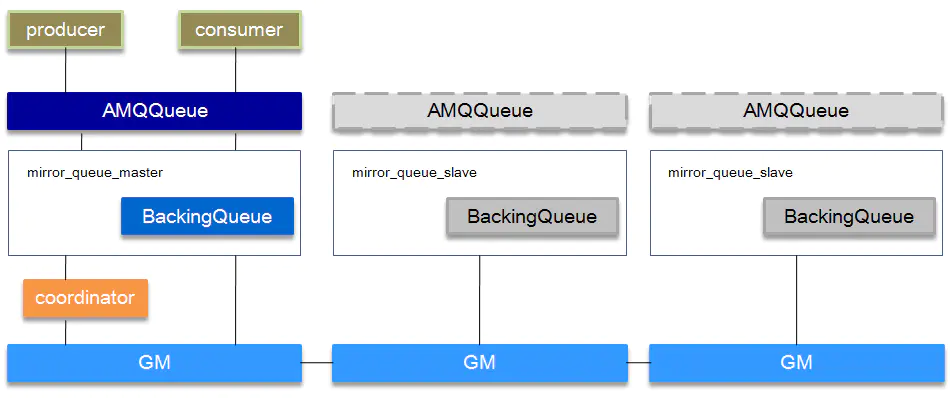
**GM(Guarenteed Multicast)**是一种可靠的组播通讯协议,该协议能够保证组播消息的原子性,即保证组中活着的节点要么都收到消息要么都收不到。它的实现大致如下:
将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上;当有节点失效时,相邻的节点会接管保证本次广播的消息会复制到所有的节点。在master节点和slave节点上的这些gm形成一个group,group(gm_group)的信息会记录在mnesia中。不同的镜像队列形成不同的group。消息从master节点对于的gm发出后,顺着链表依次传送到所有的节点,由于所有节点组成一个循环链表,master节点对应的gm最终会收到自己发送的消息,这个时候master节点就知道消息已经复制到所有的slave节点了。
转载至:https://cloud.tencent.com/developer/article/1631148
作者:CodingDiray
转载至:https://www.jianshu.com/p/f64b7acd1b4b
作者:冰河winner
客户端连接到集群
客户端可以正常连接到一个节点内的任何节点簇。 如果该节点发生故障,其余的 集群存活,那么客户端应该注意到关闭的 连接,并且应该能够重新连接到某些 幸存的集群成员。
许多客户端支持将按顺序尝试的主机名列表 在连接时。
通常不建议将 IP 地址硬编码到 客户端应用程序:这引入了不灵活性并且将 要求对客户端应用程序进行编辑、重新编译和 如果集群的配置发生变化或 集群中的节点数量发生变化。
相反,考虑一种更抽象的方法:这可能是一个 TTL 非常短的动态 DNS 服务 配置,或普通 TCP 负载平衡器,或它们的组合。
一般来说,这方面的管理 与集群内节点的连接超出了范围 本指南,我们建议使用其他 专门为解决这些问题而设计的技术。
4.4.2. 网络分区
集群可用于实现不同的目标:增加通过复制提高数据安全性,提高可用性客户端操作、更高的整体吞吐量等。 不同的配置对于不同的目的是最佳的。
检测网络分区 如果另一个节点在一分钟(或者一个net_ticktime时间)内不能连接上一个节点,那么Mnesia通常任务这个节点已经挂了。就算之后两个节点连通(译者注:应该是指网络上的可连通),但是这两个节点都认为对方已经挂了,Mnesia此时认定发送了网络分区的情况。这些会被记录在RabbitMQ的日志中,如下所示:
1 | =ERROR REPORT==== 15-Oct-2012::18:02:30 === |
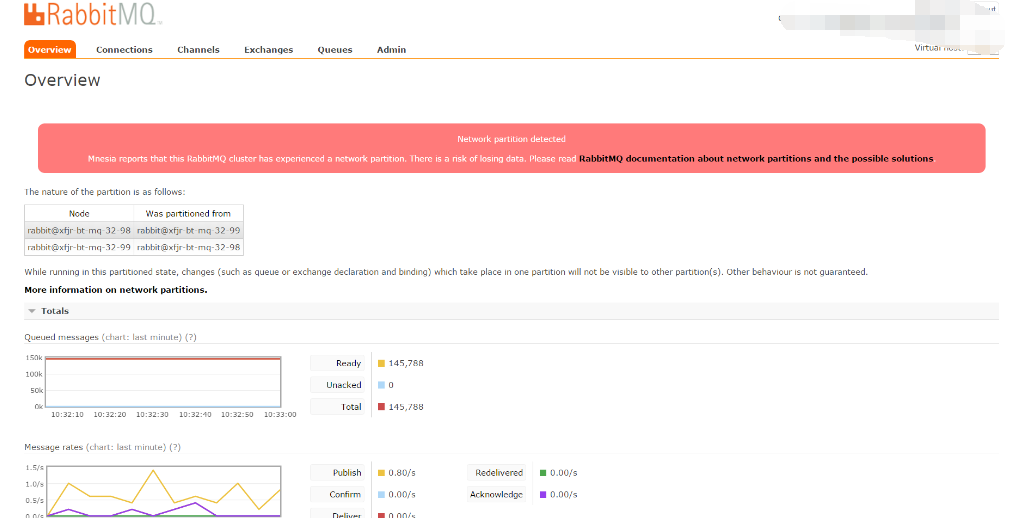
当一个节点起来的时候,RabbitMQ会记录是否发生了网络分区,你可以通过rabbitmqctl cluster_status这个命令或者管理插件看到相关信息。正常情况下,通过rabbitmqctl cluster_status命令查看到的信息中partitions那一项是空的,就像这样:
1 | rabbitmqctl cluster_status |
然而当网络分区发生时,会变成这样:
1 | rabbitmqctl cluster_status |
通过管理插件的API(under partitions in /api/nodes)可以获取到在各个节点的分区信息.
通过Web UI可以在Overview这一页看到一个大的红色的告警窗口,就像这样:

网络分区期间 当一个集群发生网络分区时,这个集群会分成两部分(或者更多),它们各自为政,互相都认为对方分区内的节点已经挂了, 包括queues, bindings, exchanges这些信息的创建和销毁都处于自身分区内,与其他分区无关。如果原集群中配置了镜像队列,而这个镜像队列又牵涉到两个(或者多个)网络分区的节点时,每一个网络分区中都会出现一个master节点(译者注:如果rabbitmq版本较新,分区节点个数充足,也会出现新的slave节点。),对于各个网络分区,此队列都是互相独立的。当然也会有一些其他未知的、怪异的事情发生。
当网络(这里只网络连通性,network connectivity)恢复时,网络分区的状态还是会保持,除非你采取了一些措施去解决他。
挂起/恢复导致的分区 当我们涉及到“网络分区”时,当集群中的不同的节点发生交互失败中断(communication interrupted)等,但是又没有节点挂掉这种情况下,才是发生了分区。然而除了网络失败(network failures)原因,操作系统的挂起或者恢复也会导致集群内节点的网络分区。因为发生挂起的节点不会认为自身已经失败或者停止工作,但是集群内的其他节点会这么认为。
如果一个集群中的一个节点运行在一台笔记本上,然后你合上了笔记本,这样这个节点就挂起了。或者说一种更常见的现象,节点运行在某台虚拟机上,然后虚拟机的管理程序挂起了这个虚拟机节点,这样也可能发生挂起。
由于挂起/恢复导致的分区并不对称——挂起的节点将看不到其他节点是否消失,但是集群中剩余的节点可以观察到,这一点貌似暗示了pause_minority这种模式(下面会涉及到)。
从网络分区中恢复 未来从网络分区中恢复,首先需要挑选一个信任的分区,这个分区才有决定Mnesia内容的权限,发生在其他分区的改变将不被记录到Mnesia中而直接丢弃。
停止(stop)其他分区的节点,然后启动(start)这些节点,之后重新将这些节点加入到当前信任的分区之中。
最后,你应该重启(restart)信任的分区中所有的节点,以去除告警。
你也可以简单的关闭整个集群的节点,然后再启动每一个节点,当然,你要确保你启动的第一个节点在你所信任的分区之中。
分区处理策略
RabbitMQ提供了三种方法自动的解决网络分区:pause-minority mode, pause-if-all-down mode以及autoheal mode。(默认的是ignore模式)
在pause-minority mode下,顾名思义,当发生网络分区时,集群中的节点在观察到某些节点“丢失”时,会自动检测其自身是否处于少数派(小于或者等于集群中一半的节点数),RabbitMQ会自动关闭这些节点的运作。根据CAP原理来说,这里保障了P,即分区耐受性(partition tolerance)。这样确保了在发生网络分区的情况下,大多数节点(当然这些节点在同一个分区中)可以继续运行。“少数派”中的节点在分区发生时会关闭,当分区结束时又会启动。
在pause-if-all-down mode下,RabbitMQ在集群中的节点不能和list中的任何节点交互时才会关闭集群的节点({pause_if_all_down, [nodes], ignore | autoheal},list即[nodes]中的节点)。也就是说,只有在list中所有的节点失败时才会关闭集群的节点。这个模式和pause-minority mode有点相似,但是,这个模式允许管理员的任命而挑选信任的节点,而不是根据上下文关系。举个案例,一个集群,有四个节点,2个节点在A机架上,另2个节点在B机架上,此时A机架和B机架的连接丢失,那么根据pause-minority mode所有的节点都将被关闭。
在autoheal mode下,当认为发生网络分区时,RabbitMQ会自动决定一个获胜(winning)的分区,然后重启不在这个分区中的节点。
一个获胜的分区(a winning partition)是指客户端连接最多的一个分区。(如果产生一个平局,即有两个(或多个)分区的客户端连接数一样多,那么节点数最多的一个分区就是a winning partition. 如果此时节点数也一样多,将会以一个未知的方式挑选winning partition.)
你可以通过在RabbitMQ配置文件中设置cluster_partition_handling参数使下面任何一种模式生效:
- pause_minority
- {pause_if_all_down, [nodes], ignore | autoheal}
- autoheal
选择哪种模式
有一点必须要清楚,允许RabbitMQ能够自动的处理网络分区并不一定会有正面的成效,也有能会带来更多的问题。网络分区会导致RabbitMQ集群产生众多的问题,你需要对你所遇到的问题作出一定的选择。就像本文开篇所说的,如果你置RabbitMQ集群于一个不可靠的网络环境下,你需要使用federation或者shovel插件。
你可能选择如下的恢复模式:
- ignore: 你的网络很可靠,所有的节点都在一个机架上,连接在同一个交换机上,这个交换机也连接在WAN上,你不需要冒险而关闭部分节点。(或者适合只有两个节点的集群。)
- pause_minority: 你的网络相对没有那么的可靠。比如你在EC2上建立了三个节点的集群,假设其中一个节点宕了,在这种策略下,剩余的两个节点还可以继续工作,失败的节点可以在恢复之后重新加入集群
- autoheal: 你的网络非常不可靠,你更关心服务的连续性而不是数据的完整性。适合有两个节点的集群。
有关pause-minority模式的更多信息 关闭的RabbitMQ节点所在主机上的Erlang虚拟机还是在正常运行,但是此节点并不会监听任何端口也不会执行其他任务。这些节点每秒会检测一次剩下的集群节点是否会再次出现,如果出现,就启动自己继续运行。
注意上面所说的“关闭的RabbitMQ节点”并不会在启动时就进入关闭状态,即使它们在“少数派(minority)”。这些“少数派”可能在“剩余的集群节点”没有启动好之前就启动了。
同样需要注意的是RabbitMQ也会关闭不是严格意义上的“大多数(majority)”——数量超过集群的一半。因此在一个集群只有两个节点的时候并不适合采用pause-minority模式,因为由于其中任何一个节点失败而发生网络分区时,两个节点都会被关闭。然而如果集群中的节点个数远大于两个时,pause_minority模式比ignore模式更加的可靠,特别是网络分区通常是由于单个节点掉出网络。
最后,需要注意的是pause_minority模式将不会防止由于集群节点被挂起而导致的分区。这是因为挂起的节点将永远不会看到集群的其余部分的消失,因此将没有触发器将其从集群中断开。
下面下面就是出现网络分区:
这是由于网络问题导致集群出现了脑裂临时解决办法:
在 相对不怎么信任的分区里,对那个分区的节点实行
在出现问题的节点上执行: sbin/rabbitmqctl stop_app 在出现问题的节点上执行: sbin/rabbitmqctl start_app
注意:mq集群不能采用kill -9 杀死进程,否则生产者和消费者不能及时识别mq的断连,会影响生产者和消费者正常的业务处理。
Rabbitmq network partition的判定及恢复策略的选择
网络分区转载于:https://www.cnblogs.com/liyongsan/p/9640361.html
作者:李永三
4.4.3. Federation插件
Federation插件的设计目标是使RabbitMQ在不同Broker节点之间进行消息传递而无需建立集群,该功能在以下场景下非常有用:
- 各个节点运行在不同版本的Erlang和RabbitMQ上
- 网络环境不稳定,如广域网当中
Federation的作用:
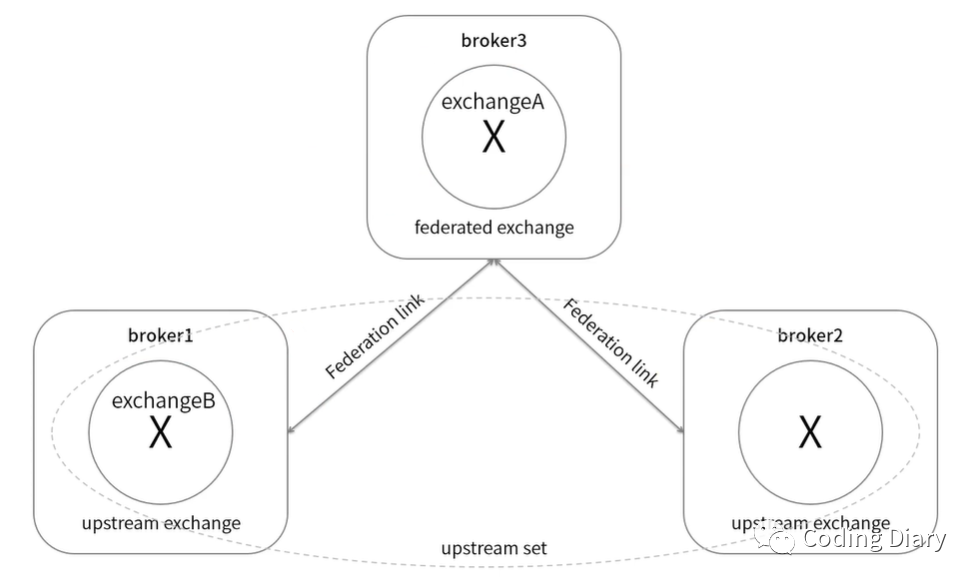
Federation直译过来是联邦,它的设计目标是使 RabbitMQ 在不同的 Broker 节点之间进行消息传递而无须建 立集群。具有以下特点:
- 支持不同管理域(不同的用户和vhost、不同版本的RabbitMQ)中的Broker或集群间传递消息
- 基于AMQP 0-9-1协议在不同的Broker之间通信,能容忍不稳定的网络连接情况
那么它到底有什么用呢?我们可以从一个实际场景入手:
有两个服务分别部署在国内和海外,它们之间需要通过消息队列来通讯。
很明显无论RabbitMQ部署在海外还是国内,另一方一定得忍受连接上的延迟。因此我们可以在海外和国内各部署一个MQ,这样一来海外连接海外的MQ,国内连接国内,就不会有连接上的延迟了。
但这样还会有问题,假设某生产者将消息存入海外MQ中的某个队列 queueB , 在国内的服务想要消费 queueB 消息,消息的流转及确认必然要忍受较大的网络延迟 ,内部编码逻辑也会因这一因素变得更加复杂。
此外,服务可能得维护两个MQ的配置,比如国内服务在生产消息时得使用国内MQ,消费消息时得监听海外MQ的队列,降低了系统的维护性。
可能有人想到可以用集群,但是RabbitMQ的集群对延迟非常敏感,一般部署在局域网内,如果部署在广域网可能会产生网络分区等等问题。
这时候,Federation就派上用场了。它被设计成能够容忍不稳定的网络连接情况,完全能够满足这样的场景。
联邦交换器
那使用Federation之后是怎样的业务流程呢?
首先我们在海外MQ上定义exchangeA,它通过路由键“rkA”绑定着queueA。然后用Federation在exchangeA上建立一条单向连接到国内RabbitMQ,Federation则自动会在国内RabbitMQ建立一个exchangeA交换器(默认同名)。
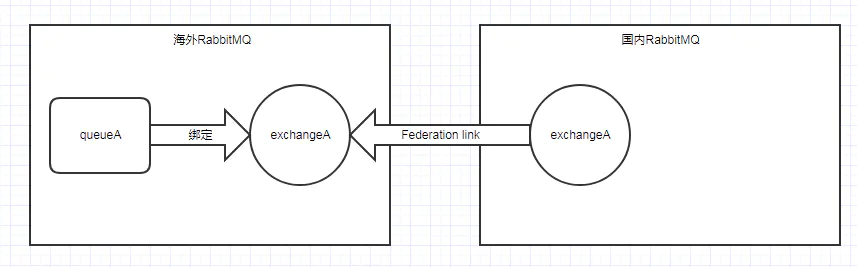
这时候,如果部署在国内的client C在国内MQ上publish了一条消息,这条消息会通过 Federation link 转发到海外MQ的交换器exchangeA中,最终消息会存入与 exchangeA 绑定的队列 queueA 中,而client C也能立即得到返回。
实际上,Federation插件还会在国内MQ建立一个内部的交换器:exchangeA→ broker3 B(broker3是集群名),并通过路由键 “rkA”将它和国内MQ的exchangeA绑定起来。接下来还会在国内MQ上建立一个内部队列federation: exchangeA->broker3 B,并与内部exchange绑定。这些操作都是内部的,对客户端来说是透明的。
值得一提的是,Federation的连接是单向的,如果是在海外MQ的exchangeA上发送消息是不会转到国内的。
这种在exchange上建立连接进行联邦的,就叫做联邦交换器。一个联邦交换器接收上游(upstream)的信息,这里的上游指的是其他的MQ节点。
对比前面举的例子,国内MQ就是上游,联邦交换器能够将原本发送给上游交换器的消息路由到本地的某个队列中。
联邦队列
有联邦交换器自然也有联播队列,联邦队列则允许一个本地消费者接收到来自上游队列的消息。
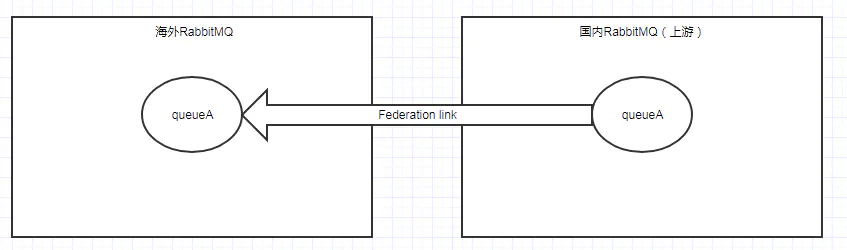
如图,海外MQ有队列A,给其设置一条链接,Federation则自动会在国内RabbitMQ建立一个队列A(默认同名)。
当有消费者 ClinetA连接海外MQ并消费 queueA 中的消息时,如果队列 queueA中本身有若干消息堆积,那么 ClientA直接消费这些消息,此时海外MQ中的queueA并不会拉取国内中的 queueA 的消息;如果队列 queueA中没有消息堆积或者消息被消费完了,那么它会通过 Federation link 拉取上游队列 queueA 中的消息(如果有消息),然后存储到本地,之后再被消费者 ClientA进行消费 。
使用
首先开启Federation 功能:
1 | #启用插件 |
值得注意的是,当需要在集群中使用 Federation 功能的时候,集群中所有的节点都应该开启 Federation 插件。
接下来我们要配置两个东西:upstreams和Policies。
每个 upstream 用于定义与其他 Broker 建立连接的信息。
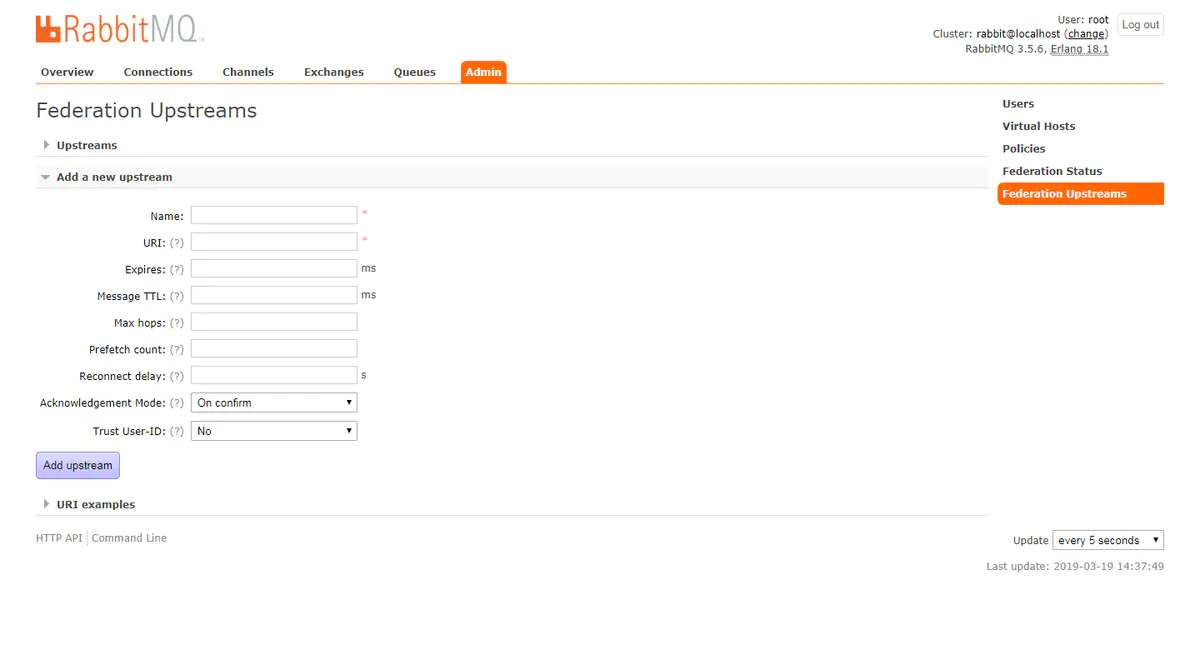
通用参数如下:
name: 定义这个upstreams的名称URI: 定义 upstreams的 AMQP 连接。例如amqp://username:password@server-name/my-vhostPrefetch count: 定义 Federation 内部缓存的消息条数,即在收到上游消息之后且在发送到下游之前缓存的消息条数。Reconnect delay: Federation link 由于某种原因断开之后,需要等待多少秒开始重新建立连接。Acknowledgement Mode: 定义 Federation link 的消息确认方式 。其有 3 种: on-confirm、 on-publish 、 no-acko 默认为 on-confirm,表示在接收到下游的确认消息之后再向上游发送消息确认,这个选项可以确保网络失败或者 Broker 密机时不会丢失消息,但也是处理速度最慢的选项。如果设置为 on-publish ,则表示消息发送到下游后(井需要等待下游的 Basic . Ack)再向上游发送消息确认,这个选项可以确保在网络失败的情况下不会丢失消息,但不能确保 Broker 岩机时不会丢失消息。 no-ack 表示无须进行消息确认,这个选项处理速度最快,但也最容易丢失消息。Expires:连接断开后,上游队列的超时时间,默认为none,表示不删除,单位为ms。相当于设置队列的x-expires参数,设置该值可以避免连接断开后,生产者一直向上游队列发送消息,造成上游大量消息堆积。
然后定义一个 Policy, 用于匹配交换器:
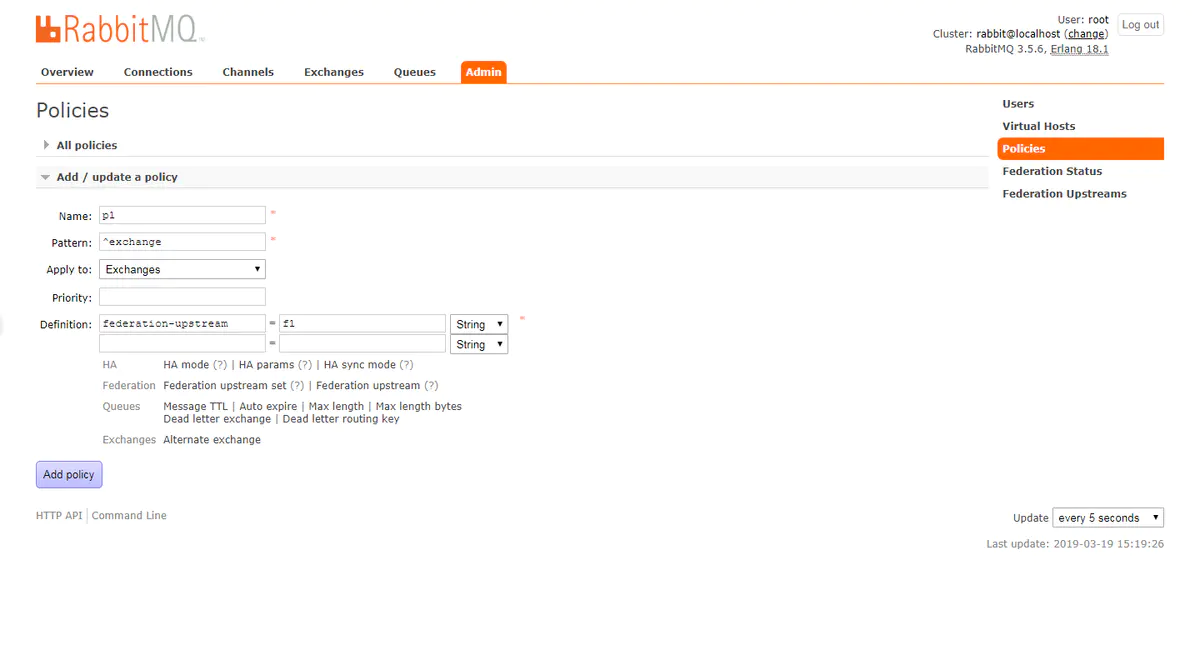
^exchange意思是将匹配所有以exchange名字开头的交换器,为它们在上游创建连接。这样就创建了一个 Federation link。
4.4.4. Shovel插件
Shovel与Federation具备的数据转发功能类似。Shovel能够可靠,持续的从一个Broker中的队列(作为源端,即source)拉取数据并转发至另一个Broker的交换器(作为目的端,即destination)
Shovel的主要优势: 松耦合,shovel可以移动位于不同管理域中的Broker或者集群上的消息,这些Broker或者集群可以包含不同的用户和vhost,也可以使用不同的RabbitMQ和Erlang版本 支持广域网,Shovel插件同样基于AMQP协议在Broker之间进行通信,被设计成可以容忍时断时续的连通情形,并且能够保证消息的可靠性 高度定制,当Shovel成功连接后,可以对其进行配置以执行相关的AMQP命令
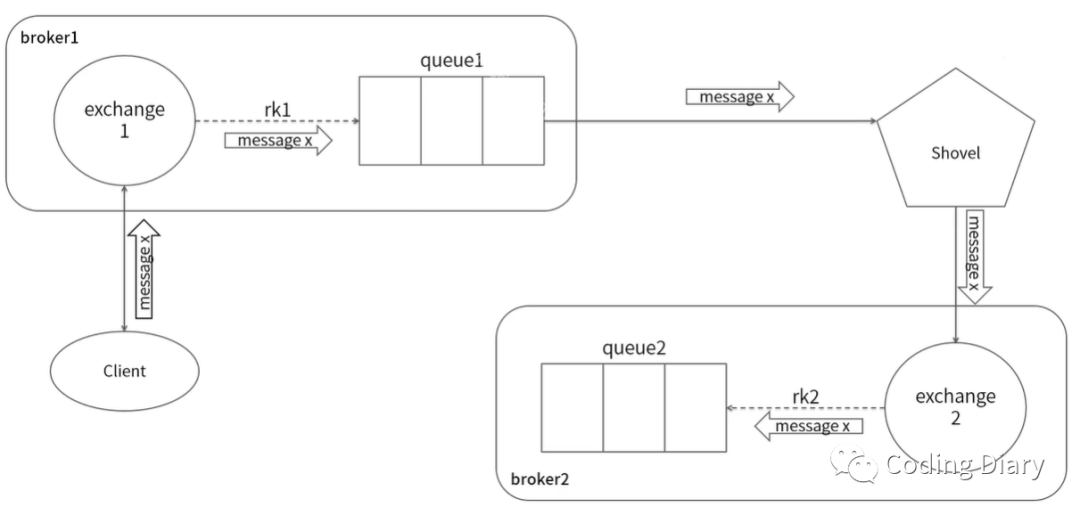
Federation/Shovel与Cluster的区别与联系
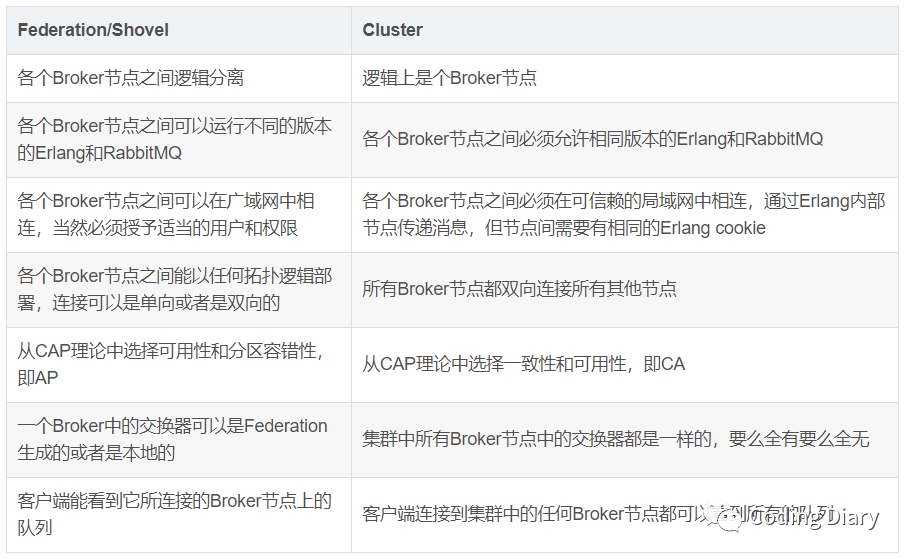
Shovel是RabbitMQ的一个插件, 能够可靠、持续地从一个Broker 中的队列(作为源端,即source )拉取数据并转发至另一个Broker 中的交换器(作为目的端,即destination )。作为源端的队列和作为目的端的交换器可以同时位于同一个 Broker 上,也可以位于不同的 Broker 上。
使用Shovel有以下优势:
- 松耦合,解决不同Broker、集群、用户、vhost、MQ和Erlang版本之间的消息移动
- 支持广域网,基于 AMQP 0-9-1 协议实现,可以容忍糟糕的网络,允许连接断开的同时不丢失消息
- 高度定制,当Shovel成功连接后,可以配置
使用Shovel时,通常源为队列,目的为交换器:
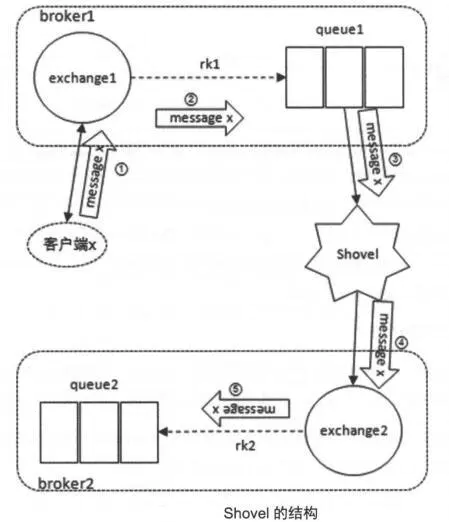
但是,也可以源为队列,目的为队列。实际也是由交换器转发,只不过这个交换器是默认交换器。配置交换器做为源也是可行的。实际上会在源端自动新建一个队列,消息先存在这个队列,再被Shovel移走。
使用Shovel插件命令:
1 | #启用插件 |
Shovel 既可以部署在源端,也可以部署在目的端。有两种方式可以部署 Shovel:
- 静态方式:在
rabbitmq.config配置文件中设置 - 动态方式:通过 Runtime Parameter 设置
其主要差异如下:
| Static Shovels | Dynamic Shovels |
|---|---|
| 基于 broker 的配置文件进行定义 | 基于 broker 的 parameter 参数进行定义 |
| 需要重启宿主 broker 以便配置生效 | 可以在任意时间进行创建和删除,直接生效 |
| 更加通用:任何 queue 、exchange 或 binding 关系均可在启动时手动声明 | 更具有目标性:被 shovel 所使用的 queue 、exchange 和 binding 关系能够自动被声明 |
来看一个使用Shovel治理消息堆积的案例。
当某个队列中的消息堆积严重时,比如超过某个设定的阈值,就可以通过 Shovel 将队列中的消息移交给另一个集群。

情形 1:当检测到当前运行集群 cluster1 中的队列 queue1 中有严重消息堆积,比如超过2 千万或者消息占用大小(messages bytes) 超过10GB 时,就启用 shovel1 将队列 queue1 中的消息转发至备份集群 cluster2 中的队列queue2 。
情形 2 :紧随情形1,当检测到队列queue1 中的消息个数低于1 百万或者消息占用大小低于1GB 时就停止shovel1 ,然后让原本队列 queue1 中的消费者慢慢处理剩余的堆积。
情形 3:当检测到队列 queue1 中的消息个数低于10 万或者消息占用大小低于100MB时,就开启 shovel2 将队列 queue2 中暂存的消息返还给队列queue1 。
情形 4:紧随情形3 ,当检测到队列queuel 中的消息个数超过 1百万或者消息占用大小高于1GB 时就将shovel2 停掉。
作者:冰河winner 链接:https://www.jianshu.com/p/f64b7acd1b4b
作者:CodingDiray
转载于:https://cloud.tencent.com/developer/article/1631148
4.4.5. 节点间通信心跳
概述
集群中的每对节点都由传输层连接。在所有节点对之间交换周期性滴答消息以维持连接并检测断开连接。否则,网络中断可能会在相当长的一段时间内未被检测到(取决于传输和操作系统内核设置,例如 TCP)。从根本上说,这与心跳在消息传递协议中寻求解决的问题相同,只是在不同的对等点之间:RabbitMQ 集群节点和 CLI 工具。
节点和连接的 CLI 工具定期相互发送小数据帧。如果在给定时间段内未从对等方接收到数据,则认为该对等方不可用(“关闭”)。
当一个 RabbitMQ 节点确定另一个节点出现故障时,它会记录一条消息,给出另一个节点的名称和原因,例如:
1 | 2018-11-22 10:44:33.654 [info] node rabbit@peer-hostname down: net_tick_timeout |
在这种情况下, net_tick_timeout 事件告诉我们由于心跳时间,另一个节点被检测为超时关闭。 另一个常见的原因是 connection_closed ,意味着连接在TCP级别明确关闭。
心跳频率
心跳消息和故障检测的频率由 net_ticktime 配置设置控制。 通常每 net_ticktime 秒在一对节点之间交换四个心跳声。 如果在 net_ticktime (± 25% for ) 秒内没有收到来自节点的通信,则认为该节点已关闭并且不再是集群的成员。 增加集群中所有节点的 net_ticktime 将使集群对短暂的网络中断更有弹性,但剩余节点需要更长的时间才能检测到崩溃的节点。 相反,减少集群中所有节点的 net_ticktime 将减少检测延迟,但会增加检测虚假分区的风险。 应仔细考虑更改默认 net_ticktime 的影响。 集群中的所有节点必须使用相同的 net_ticktime。 以下示例 advanced.config 配置演示了将默认 net_ticktime 从 60 秒加倍到 120 秒:
1 | [ |
对HTTP API的影响
HTTP API 通常需要执行集群范围的查询 这会导致 UI 可能会出现无响应,直到 分区被检测和处理。 降低 net_ticktime 可以帮助提高此类事件期间的响应能力,但任何 决定更改 net_ticktime 应谨慎 如上所述。
官网地址:https://www.rabbitmq.com/nettick.html
4.4.6. 使用 TLS (SSL) 保护集群(节点间)和 CLI 工具通信
概述
主要的 TLS 和 故障排除 TLS 指南解释 如何使用 TLS 保护客户端连接。 可能需要添加一层加密和额外的 对另外两种连接进行认证层。 本指南解释了如何做到这一点。
切换节点间和 CLI 工具通信需要配置一些 运行时 标志。 它们为节点提供 CA 证书包和证书/密钥对 。 还必须将 CLI 工具配置为使用证书/密钥对作为启用 TLS 的节点 不会接受来自 CLI 工具和对等方的未加密连接。
假设您已经有一个 CA 证书包和为每个生成的证书/密钥对。 集群节点和每个主机的 CLI 工具都将被使用。 在生产环境中,这些证书 通常由运营商或部署工具产生。 对于开发和实验, 有一种 的 生成它们 快速方法 使用 OpenSSL 和 Python。
本指南将引用三个文件:
- ca_certificate.pem :证书颁发机构包
- server_certificate.pem :配置节点(和/或 CLI 工具)将使用的证书(公钥)
- server_key.pem :配置节点(和/或 CLI 工具)将使用的私钥
将节点配置为通过启用 TLS 的连接进行通信涉及一些脚步。 对于 受支持的 Erlang 版本,有两种方法可以做到。
策略一包括以下步骤:
- 使用运行时标志告诉节点使用加密的节点间连接 -proto_dist inet_tls
- 将节点要使用的公钥和私钥合并到一个文件中
- 使用另一个运行时标志告诉节点在哪里可以找到其证书和私钥 -ssl_dist_opt server_certfile
- 使用其他告诉节点所需的任何其他 TLS 设置, -ssl_dist_opt 选项 例如: -ssl_dist_opt server_secure_renegotiate true client_secure_renegotiate true 以启用 安全重新协商
策略二非常相似,但不是指定一组运行时标志,而是可以指定这些选项 在类似于 RabbitMQ 的 advanced.config 文件 文件中和运行时的 将指向该文件。 因此步骤如下:
- 使用运行时标志 告诉节点使用加密的节点间连接 -proto_dist inet_tls
- 部署一个节点间 TLS 设置文件,其中包含有关证书/密钥对位置、CA 包位置、 使用的 TLS 设置等
- 使用另一个运行时标志 告诉节点在哪里可以找到它的节点间 TLS 设置文件 -ssl_dist_optfile
使用这两个选项,环境变量用于将这些选项传递给运行时。 这是最好的使用 rabbitmq-env.conf 完成, 如 配置指南中所述。
部署节点间TLS
一旦节点配置了 TLS 的节点间连接,CLI 工具如 rabbitmqctl 和 rabbitmq-diagnostics 还必须使用 TLS 与节点通信。 普通 TCP 连接将失败。
一旦证书/密钥对文件和配置就位,就可以启动新节点。 请注意,可能需要先停止节点,然后部署文件和配置,最后启动节点。 这是因为配置为使用 TLS的CLI 工具将无法连接到 不期望启用 TLS 的 CLI 工具连接。
对于节点和 CLI 工具成功执行 TLS 握手和对等验证, 同样的 对等认证例如,其他节点和 CLI 使用的证书/密钥对 工具必须由与初始节点相同的证书颁发机构签名或 在所有集群节点上受信任的不同 CA。
这与方式没有什么不同对等验证对客户端和插件 TLS 连接的工作。
可以为所有节点和CLI 工具重复使用单个证书/密钥对。 证书还可以使用通配符主题备用名称 (SAN) 或通用名称 (CN),例如 *.rabbitmq.example.local 这将匹配集群中的每个主机名。
具体部署流程可以参考官方文档:https://www.rabbitmq.com/clustering-ssl.html
TLS连接进行故障排除可以参考官方文档:https://www.rabbitmq.com/troubleshooting-ssl.html
4.4.7. 节点间和CLI流量压缩
RabbitMQ 节点使用专用 TCP 连接与其对等节点和 CLI 工具进行通信, 可选择 使用 TLS 保护 。 在重载系统中,节点间流量可能很大,接近 甚至使网络链接提供的带宽饱和。 压缩此流量 有助于减少可用带宽的负载,最高可达 96%,具体取决于工作量。
节点间流量压缩在 VMware Tanzu RabbitMQ中开箱即用: 如果两个 RabbitMQ节点组成一个集群,它们会尝试使用压缩。
对于要压缩的数据,必须满足以下条件:
- 两个 RabbitMQ 节点都必须支持节点间流量压缩。 其他 也就是说,两个节点都必须运行 VMware Tanzu RabbitMQ。 开源版本 不支持此功能 。
- 两个节点必须共享至少一种共同的压缩算法。
RabbitMQ 节点第一次尝试联系另一个节点时,它将执行 以下事项:
- TCP 连接打开后,首先不会使用压缩。
- 发起连接的节点 检测远程peer是否有Erlang 分布压缩支持 。 如果没有,则连接 保持未压缩状态,并跳过以下步骤。
- 一旦节点确定远程节点支持压缩,它就会 协商 要使用的压缩算法 。 要启动此过程,它会向 远程节点并指定它支持的算法列表。
- 远程节点将接收到的算法列表与其自己的列表进行比较。 远程节点的列表按偏好排序。 选择的算法是 远程节点列表中的第一个也受 发起节点。 如果没有共同的算法,则连接保持 未压缩并跳过以下步骤。
- 选择算法后,远程节点 将消息发送回 发起节点通知它它的决定 。
- 两个节点同步 开始 压缩 对现有 TCP 进行联系

节点间流量 不能同时使用 压缩和TLS :目前它们是相互排斥的。
这是因为 RabbitMQ 节点配置了特定的 随 VMware Tanzu RabbitMQ 提供的分发模块,加上一个小的 用于处理算法协商的附加组件。 分布 模块是默认模块( inet_tcp_dist )或 启用 TLS 的一个 ( inet_tls_dist )。 不可能使用两个模块 同时地。
在 VMware Tanzu RabbitMQ 中,压缩代码依赖于原生库。仅支持 Linux/amd64** 现有包装中 。 我们可能 将来编译更多平台。
4.4.8. 客户端查找队列主节点
RabbitMQ 实现镜像队列的方式比较特别。这篇文章进行了深入的阐述。假设有如下的配置:
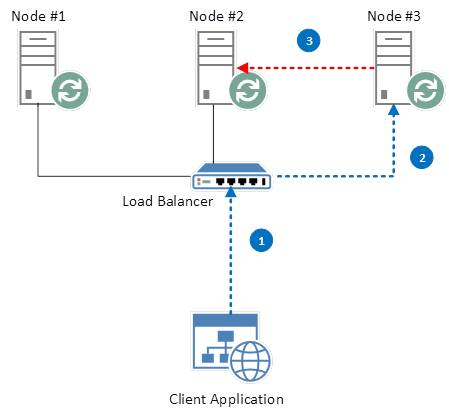
创建 queue 的过程:
- LB 将 client request 分发到 node 2,client 创建队列 “NewQueue”,然后开始向其中放入 message。
- 最终,后端服务会对 node 2 上的 “NewQueue” 创建一个快照,并在一段时间内将其拷贝到node 1 和 3 上。这时候,node2 上的队列是 master Queue,node 1 和 3 上的队列是 slave queue。
假如现在 node2 宕机了:
- node 2 不再响应心跳,它会被认为已经被从集群中移出了
- node 2 上的 master queue 不再可用
- RabbitMQ 将 node 1 或者 3 上的 salve instance 升级为 master instance
假设 master queue 还在 node 2 上,客户端通过 LB 访问该队列:
- 客户端连接到集群,要访问 “NewQueue” 队列
- LB 根据配置的轮询算法将请求分发到一个节点上
- 假设客户端请求被转到 node 3 上
- RabbitMQ 发现 “NewQueue” master node 是 node 2
- RabbitMQ 将消息转到 node 2 上
- 最终客户端成功连接到 node 2 上的 master 队列
可见,这种配置下,2/3 的客户端请求需要重定向,这会造成大概率的访问延迟,但是终究访问还是会成功的。要优化的话,总共有两种方式:
- 直接连到 master queue 所在的节点,这样就不需要重定向了。但是对这种方式,需要提前计算,然后告诉客户端哪个节点上有 master queue。
- 尽可能地在所有节点间平均分布队列,减少重定向概率
但我们仍然面临同样的问题; 我们的客户端应用程序需要知道我们的队列所在的位置。 所以让我们看看进一步推进解决方案,这样我们就可以避免这个缺点。
首先,我们需要提供描述我们的 RabbitMQ 基础设施的映射元数据。 具体来说,队列所在的位置。 这应该是一个弹性数据源,例如数据库或缓存,而不是像平面文件这样的东西,因为多个源(至少 2 个)可以同时访问这些数据。
现在引入一个永远在线的服务来轮询 RabbitMQ,以确定节点是否处于活动状态。 新队列也应该注册到这个服务,它应该保持一个最新的注册表,提供关于节点及其队列的元数据:
带监控服务的RabbitMQ集群
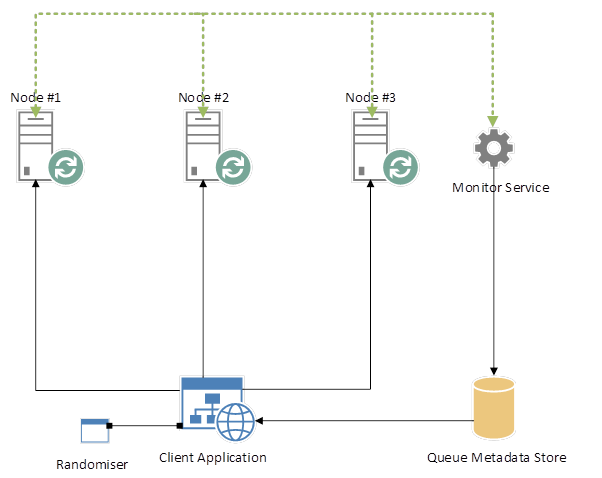 我们的客户端应用程序,在初始加载时,应该轮询这个服务并检索 RabbitMQ 元数据,然后应该为传入的请求保留这些元数据。 如果请求因节点受到威胁而失败,客户端应用程序可以轮询队列元数据存储,返回最新的 RabbitMQ 元数据,并将消息重新路由到工作节点。
我们的客户端应用程序,在初始加载时,应该轮询这个服务并检索 RabbitMQ 元数据,然后应该为传入的请求保留这些元数据。 如果请求因节点受到威胁而失败,客户端应用程序可以轮询队列元数据存储,返回最新的 RabbitMQ 元数据,并将消息重新路由到工作节点。
您必须存储 Queue 元数据 - 即,将每个 Queue 与特定节点相关联的索引,该节点可在您的客户端应用程序访问的某处进行。 这个概念在上面标记为“带有监控服务的 RabbitMQ 集群”。 在上述情况下,队列元数据离线存储在一个名为“队列元数据存储”的小型存储库中,可供客户端访问。
这种方法是我已经取得一些成功的设计。 从概念的角度来看,它构成了整个微服务 一小部分 架构的 ,我将在以后的文章中讨论。
转载至:https://insidethecpu.com/2014/11/17/load-balancing-a-rabbitmq-cluster/
作者:**Paul Mooney**
4.5. 报警
4.5.1. 内存和磁盘报警
概述
在运行过程中,RabbitMQ 节点会消耗不同数量的 内存和磁盘 基于工作负载的空间。 当使用量激增时,内存和可用磁盘空间都可以达到 潜在危险水平。 在内存的情况下,节点可以被杀死 通过操作系统的低内存进程终止机制 (例如,在 Linux 上被称为“OOM 杀手”)。 在可用磁盘空间的情况下, 节点可能会耗尽内存,这意味着它将无法执行 许多内部操作。
为了减少这些场景的可能性,RabbitMQ 有两个可配置的资源 水印。 当它们到达时,RabbitMQ 将阻止发布消息的连接。
更具体地说,RabbitMQ 将阻止连接 发布消息以避免被杀死 操作系统(内存不足杀手)或耗尽所有可用磁盘空间:
- 当 内存使用超过配置的水印(限制)时
- 当 可用磁盘空间低于配置的水印(限制)时
节点将暂时阻止发布连接 通过暂停从读取客户端连接。 仅用于 连接 消费 消息的 不会被阻止。
连接心跳监控也将被禁用。 所有网络连接都将显示在 rabbitmqctl 和 管理 UI 作为 阻塞 ,这意味着它们 尚未尝试发布并因此可以继续,或 被屏蔽 ,意味着他们已经发布并且现在 暂停。 将 兼容的客户通知当他们被阻止时。
只消耗的连接不会被资源告警阻塞; 交货他们照常继续。
集群中的警报
在集群中运行RabbitMQ时,内存和磁盘告警 是集群范围的; 如果一个节点超过限制,则所有节点 将阻止连接。
这里的目的是阻止生产者但让消费者继续 不受影响。 然而,由于该协议允许生产者和消费者 在同一频道上操作,并在一个的不同频道上操作 单连接,这个逻辑必然不完善。 在 对大多数应用程序不会造成任何问题的实践 因为节流仅作为 延迟。 然而,在其他设计考虑允许的情况下,它 建议只使用单独的连接 生产或消费。
对数据安全的影响
当警报生效时,发布连接将被 TCP 背压阻塞。 在实践中,这意味着发布操作最终将彻底超时。 应用程序开发人员必须准备好处理此类故障并使用 发布者确认跟踪 RabbitMQ 已成功处理和处理了哪些消息。
文件描述符用完
当服务器接近使用所有文件描述符时 操作系统已提供给它,它将拒绝客户端连接。
瞬态流量控制
当客户端尝试以比服务器更快的速度发布时 接受他们的消息,他们进入瞬态 流量控制 。
4.5.2. 流量控制
本指南涵盖了 RabbitMQ 节点应用的背压机制 发布连接以避免失控的 内存使用量增长。 这是必要的,因为节点中的某些组件可能会落后于特别快的发布者 因为他们必须做比发布客户端更多的工作(例如将数据复制到 N 对等节点或将其存储在磁盘上)。
RabbitMQ 会降低发布太快的连接速度,队列跟不上。
流控连接会显示状态 流 在 rabbitmqctl 中 ,管理 UI 和 HTTP API 响应。 这意味着连接正在经历 每秒多次阻塞和解除阻塞,以保持消息入口在服务器的其余部分(例如,将这些消息路由到的队列)可以处理。
通常,处于流量控制中的连接不应该看到与正常运行的任何差异; 在流动状态 有没有通知系统管理员发布率是 受限制,但从客户的角度来看,它应该只是 看起来服务器的网络带宽比实际低。
连接以外的其他组件可以在 流动 状态。 通道、队列和系统的其他部分 可以应用最终传播回发布连接的流控制。
找出消费者和 预取设置 可能是关键的限制因素, 请查看相关指标 。 请参阅 监控和健康检查 指南以了解更多信息。
4.5.3. 可用磁盘空间警报
当可用磁盘空间低于配置的限制(默认为 50 MB)时, 将触发警报并阻止所有生产者。
目标是避免填满整个磁盘,这将导致所有 节点上的写操作失败并可能导致 RabbitMQ 终止。
为了降低磁盘填满的风险,所有传入的消息都是 阻止。 通常不会持久化的瞬态消息仍会被调出 在内存压力下时写入磁盘,并且会耗尽已经有限的 磁盘空间。
如果磁盘警报设置得太低并且消息被快速调出, 可能会耗尽磁盘空间并在磁盘之间使 RabbitMQ 崩溃 空格检查(至少间隔 10 秒)。 更保守的方法 将限制设置为与安装的内存量相同 在系统上
如果可用磁盘空间量不足,则会触发警报 低于配置的限制。
代理数据库使用的驱动器或分区的可用空间 将至少每 10 秒监控一次以确定磁盘是否 应发出或清除警报。
详细可以参考官方文档:https://www.rabbitmq.com/disk-alarms.html
4.5.4. 内存使用
RabbitMQ 可以使用不同的策略来计算一个节点使用了多少内存。
产生内存使用故障可以通过HTTP API 通过向 发出 GET 请求 /api/nodes/{node}/memory 端点查看使用详情。也可以使用管理 UI 内存分解图。
这包括客户端连接使用的内存(包括 铲子和 联合链接) 和通道,以及传出的(Shovels 和 Federation 上游链接)。 大部分内存通常由 TCP 缓冲区使用,它在 Linux 上默认自动调整到大约 100 kB 的大小。 TCP 缓冲区大小可以以连接吞吐量成比例减少为代价来减少。
通道也消耗 RAM。 通过优化应用程序使用的通道数量,该数量 可以减少。 可以使用以下方法限制连接上的最大通道数 所述 channel_max 配置设置:
1 | 通道最大值 = 16 |
一条消息有多个占用内存的部分:
- 有效负载:>= 1 字节,大小可变,通常为几百字节到几百千字节
- 协议属性:>= 0 字节,大小可变,包含标题、优先级、时间戳、回复等。
- RabbitMQ 元数据:>= 720 字节,大小可变,包含交换、路由键、消息属性、持久性、重新传递状态等。
- RabbitMQ 消息排序结构:16 字节
一旦将属性和元数据考虑在内,具有 1KB 有效负载的消息将占用 2KB 的内存。
某些消息可以存储在磁盘上,但仍将其元数据保存在内存中。
一条消息有多个占用内存的部分。 每个队列都由一个 Erlang 进程支持。 如果队列被镜像,则每个镜像都是一个单独的 Erlang 进程。
由于队列的每个副本,无论是领导者还是追随者,都是单个 Erlang 进程,因此可以保证消息排序。 多个队列意味着多个 Erlang 进程可以获得均匀的 CPU 时间。 这确保没有队列可以阻塞其他队列。
Erlang 使用分 代垃圾收集 对每个 Erlang 进程 。 垃圾收集是按队列完成的,独立于所有其他 Erlang 进程。
当垃圾收集运行时,它会在释放未使用的内存之前复制已使用的进程内存。 这可能导致队列进程在垃圾回收期间使用多达两倍的内存,如下所示(队列包含大量消息):
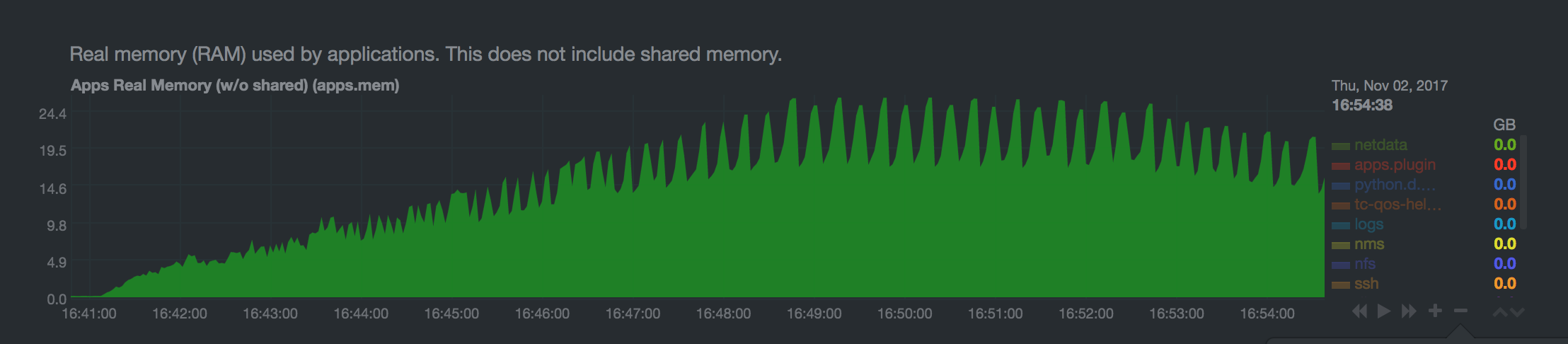
如果 Erlang VM 尝试分配比可用内存更多的内存,则 VM 本身将崩溃或被 OOM 杀手杀死。 当 Erlang VM 崩溃时,RabbitMQ 将丢失所有非持久性数据。
高内存水印会阻止发布者并防止新消息进入队列。 由于垃圾收集可以使队列使用的内存加倍,因此将高内存水位设置为0.5以上是不安全 。 默认的高内存水印设置为 0.4, 因为这更安全,因为并非所有内存都被队列使用。 这完全是特定于工作负载的,这在 RabbitMQ 部署中有所不同。
我们推荐使用多个队列,以便内存分配/垃圾收集分布在多个 Erlang 进程中。
如果队列中的消息占用大量内存,我们建议使用惰性队列,以便将它们存储在磁盘上 尽可能快地保存在内存中的时间不要超过必要的时间。
kubernetes报警部署使用可以参考这篇博客:https://blog.rabbitmq.com/posts/2021/05/alerting/
报警中的kubernetes可以参考这一篇官方文档:https://kubernetes.io/docs/reference/kubectl/overview/
RabbitMQ部署kubernetes可以参考:https://blog.rabbitmq.com/posts/2020/08/deploying-rabbitmq-to-kubernetes-whats-involved/
4.6. Stream
RabbitMQ 3.9 引入了一种新型数据结构: Stream
RabbitMQ Streams 在以下用例中大放异彩:
- 大扇出 :许多应用程序需要读取相同的消息 (对于传统队列,这将需要为每个应用程序声明一个队列并将相同消息的副本传递给每个应用程序)
- 大积压 :流将消息存储在磁盘上,而不是内存中,因此唯一的限制是磁盘容量
- 重放和时间旅行 :消费者可以使用绝对偏移量或时间戳附加流中的任何位置,并且他们可以读取和重新读取相同的数据
- 高吞吐量 :与传统队列相比,流速度超快,快几个数量级
由于流在执行任何操作之前将所有数据保存到磁盘,因此建议 尽可能使用最快的磁盘。
由于流的磁盘 I/O 密集型特性,它们的吞吐量会降低 随着消息大小的增加。
就像仲裁队列一样,流也受集群大小的影响。 流的副本越多,其吞吐量通常就越低 因为需要做更多的工作来复制数据并达成共识。
其实可以看出RabbitMQ Stream有点像kafka设计模式,可以参考官方地址:https://www.rabbitmq.com/streams.html
4.7. RabbitMQ网络
概述
客户端通过网络与 RabbitMQ 通信。 全部代理支持的协议是基于 TCP 的。 两个都 RabbitMQ 和操作系统提供了一些可以调整的旋钮。 其中一些是直接 与 TCP 和 IP 操作相关,其他则 应用层协议,如 TLS。
从 RabbitMQ 3.8.8 开始, 客户端可以连接侦听器 暂停 以防止新客户端 连接被接受。 现有连接不会受到任何影响。
什么是 EPMD,它是如何使用的?
epmd (用于 Erlang 端口映射守护进程) 是一个额外的小守护进程,与每个 RabbitMQ 节点一起运行,并由 在 运行时 ,发现一个特定节点上监听的端口 节点间通信。 该端口随后由对等节点和 CLI 工具使用 。
epmd 默认情况下, 将侦听所有接口。 它可以 被限制为使用 的多个接口 ERL_EPMD_ADDRESS 环境变量。
节点间通信缓冲区大小限制
节点间连接为待发送的数据使用缓冲区。 暂时的 当缓冲区达到最大允许值时,会应用对节点间流量的限制 容量。 限制通过 RABBITMQ_DISTRIBUTION_BUFFER_SIZE 环境变量控制 以千字节为单位。 默认值为 128 MB ( 128000 kB)。
在节点间流量较大的集群中,增加此值可能会 对吞吐量有积极影响。 低于 64 MB 的值不是 受到推崇的。
调整大量连接
一些工作负载,通常被称为“互联网 事情”,假设每个客户端有大量的连接 节点,并且来自每个节点的流量相对较低。 其中一种工作负载是传感器网络:可能有数百个 部署了数千或数百万个传感器,每个传感器发出 每隔几分钟的数据。 最大化优化 并发客户端的数量可能比 for 总吞吐量。
有几个因素可以限制单个节点可以支持的并发连接数:
- 最大 打开文件句柄数(包括套接字)以及其他内核强制资源限制
- 每个连接使用 RAM的大小
- 每个连接使用的 CPU 资源量
- 虚拟机配置允许的最大 Erlang 进程数。
打开文件句柄限制
大多数操作系统限制文件句柄的数量 可以同时打开。 当一个 OS 进程(比如 RabbitMQ 的 Erlang VM)到达 限制,它将无法打开任何新文件或接受更多 TCP 连接。
在优化并发连接数时, 确保你的系统有足够的文件描述符 不仅支持客户端连接,还支持文件节点 可以使用。 要计算棒球场限制,请乘以数字 每个节点的连接数减少 1.5。 例如,要支持 100,000 连接数,将限制设置为 150,000。
增加限制会略微增加 RAM空闲机器使用,但这是一个合理的权衡。
**每个连接内存消耗:TCP 缓冲区大小 **
降低 TCP 缓冲区大小将导致成比例的吞吐量下降, 所以吞吐量和每个连接的 RAM 使用之间的最佳值需要是 为每个工作负载找到。
将发送和接收缓冲区大小设置为不同的值是危险的 并且不推荐。 不建议使用低于 8 KiB 的值。
**减少统计数据排放的 CPU 占用空间 **
大量的并发连接会产生大量的metric(stats)发射事件。 即使连接大部分处于空闲状态,这也会增加 CPU 消耗。 为了减少这种足迹, 使用 增加统计信息收集间隔 collect_statistics_interval 键。默认值为 5 秒(5000 毫秒)。
将间隔值增加到 30-60 秒将减少 CPU 占用空间和峰值内存消耗。 这有一个缺点:使用上面示例中的值,所述实体的度量 将每 60 秒刷新一次。
这在 是完全合理的 外部监控的生产系统中 但会使操作员使用管理 UI 不太方便。
限制连接上的通道数
通道也消耗 RAM。 通过优化应用程序使用的通道数量,该数量 可以减少。 可以使用以下方法限制连接上的最大通道数 所述 channel_max 配置设置:
1 | channel_max = 16 |
请注意,一些构建在 RabbitMQ 客户端之上的库和工具可能隐式需要 一定数量的频道。 很少需要高于 200 的值。 寻找最佳值通常是一个反复试验的问题。
Nagle 算法(“nodelay”)
禁用 Nagle 的 算法 主要用于减少延迟,但 还可以提高吞吐量。 kernel.inet_default_connect_options 和 kernel.inet_default_listen_options 必须 包括 {nodelay, true} 以禁用 Nagle 的节点间连接算法。
Erlang VM I/O 线程池调优
在为大量的线程进行调优时,足够的 Erlang VM I/O 线程池大小也很重要。 并发连接。 请参阅上面的部分。
连接积压
客户端数量少,新连接率分布极不均匀 但也足够小,不会产生太大影响。 当数量达到数万时 或者更重要的是,确保服务器可以接受入站连接。 未接受的 TCP 连接被放入一个有界长度的队列中。 这个长度必须是 足以说明高峰负载时间和可能的峰值,例如,当许多客户端 由于网络中断而断开连接或选择重新连接。 这是使用 配置的 tcp_listen_options.backlog 选项。默认值是 128。当挂起的连接队列长度超过这个值时, 操作系统将拒绝连接。 另见 net.core.somaxconn 在内核调整部分。
为什么高连接流失有问题?
具有高连接流失率(打开和关闭连接的高速率)的工作负载将需要 TCP 设置调整最大文件句柄数以避免耗尽某些资源, RabbitMQ 节点上的 Erlang 进程,内核的临时端口范围(对于 打开 大量 连接,包括 联邦 链接和 铲子 连接)等。 耗尽这些资源的节点 将无法接受新连接 , 这将对整体系统可用性产生负面影响。 由于某些 TCP 功能的组合 和大多数现代 Linux 发行版的默认设置,关闭连接后可以检测到 一段很长的时间。 这在 心跳指南中有介绍 。 这可能是连接建立的一个促成因素。 另一个是 TIME_WAIT TCP 连接状态。 该状态的存在主要是为了确保从关闭的重传段 连接不会在具有相同客户端主机和端口的不同(较新)连接上“重新出现”。 根据操作系统和 TCP 堆栈配置,连接可能会在此状态下花费数分钟, 这在繁忙的系统上肯定会导致连接建立。
**TCP 保活 **
TCP 包含一个类似于心跳的机制 (又名keepalive)消息协议和网络心跳中的一个 上面涵盖的超时:TCP keepalive。 由于不足 默认情况下,TCP keepalive 通常无法正常工作 应该:需要很长时间(例如,一个小时或更长时间) 检测死对等体。 但是,通过调整,他们可以服务 与心跳相同的目的并清理陈旧的 TCP 连接 例如,对于故意或选择不使用心跳的客户端 。 TCP keepalives 是一种有用的额外防御机制 在 RabbitMQ 操作员无法控制的环境中 使用的应用程序设置或客户端库。
连接握手超时
RabbitMQ 有连接握手超时,10 秒 默认。 当客户端在严重受限的环境中运行时, 可能需要增加超时时间。
客户端执行
如果客户端库配置为连接到主机名,它会执行 主机名解析。 取决于 DNS 和本地解析器 ( /etc/hosts 和类似)配置,这可能需要一些时间。 配置不正确 可能会导致解析超时,例如在尝试解析本地主机名时 例如 my-dev-machine ,通过 DNS。 结果,客户端连接 可能需要很长时间(从几十秒到几分钟)。
更多配置信息和网络故障排除可以参考官方文档:https://www.rabbitmq.com/networking.html
4.8. RabbitMQ虚拟主机
逻辑和物理分离
虚拟主机提供逻辑分组和分离 资源。 物理资源的分离不是主机虚拟化的目标,应该被视为一个实现细节。
比如 资源权限 是 RabbitMQ中的 每个虚拟主机的范围。 用户没有全局权限,只有 一个或多个虚拟主机中的权限。 可以考虑用户标签 全局权限,但它们是规则的例外。
因此,在谈论用户权限时非常重要 阐明它们适用于哪些虚拟主机。
虚拟主机和客户端连接
虚拟主机有一个名字。 当 AMQP 0-9-1 客户端连接到 RabbitMQ,它指定要连接的虚拟主机名。 如果认证 成功和提供的用户名被 授予的权限给 vhost,连接建立。
与虚拟主机的连接只能对交换器、队列、绑定等进行操作 那个虚拟主机。 例如队列和不同虚拟主机中的交换的“互连”是唯一可能的 当应用程序同时连接到两个虚拟主机时。 例如,一个 应用程序可以从一个虚拟主机消费,然后重新发布到另一个。 这个场景 可能涉及不同集群或同一集群(或单个节点)中的 vhost。 RabbitMQ Shovel 插件 就是此类应用程序的一个示例。
更多虚拟主机的配置和使用可以参考官方文档:https://www.rabbitmq.com/vhosts.html
4.9. 高可用性
集群可用性
集群可用性(availability)指集群正常运行时间的百分比,业界用 N 个9 来量化可用性,最常说的就是类似“4个9(也就是99.99%)”的可用性。
| 描述 | 通俗叫法 | 可用性级别 | 年度停机时间 |
|---|---|---|---|
| 基本可用性 | 2个9 | 99% | 87.6小时 |
| 较高可用性 | 3个9 | 99.9% | 8.8小时 |
| 具有故障自动恢复能力的可用性 | 4个9 | 99.99% | 52分钟 |
| 极高可用性 | 5个9 | 99.999% | 5分钟 |
RabbitMQ本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。
我们把部署RabbitMQ的机器称为节点,也就是broker。broker有2种类型节点:磁盘节点和内存节点。顾名思义,磁盘节点的broker把元数据存储在磁盘中,内存节点把元数据存储在内存中,很明显,磁盘节点的broker在重启后元数据可以通过读取磁盘进行重建,保证了元数据不丢失,内存节点的broker可以获得更高的性能,但在重启后元数据就都丢了。
元数据包含以下内容:
- queue元数据:queue名称、属性
- exchange:exchange名称、属性
- binding元数据:exchange和queue之间、exchange和exchange之间的绑定关系
- vhost元数据:vhost内部的命名空间、安全属性数据等
单节点系统必须是磁盘节点,否则每次你重启RabbitMQ之后所有的系统配置信息都会丢失。
集群中至少有一个磁盘节点,当节点加入和离开集群时,必须通知磁盘 节点。
如果集群中的唯一一个磁盘节点,结果这个磁盘节点还崩溃了,那会发生什么情况?集群依然可以继续路由消息(因为其他节点元数据在还存在),但无法做以下操作:
- 创建队列、交换器、绑定
- 添加用户
- 更改权限
- 添加、删除集群节点
也就是说,如果唯一磁盘的磁盘节点崩溃,集群是可以保持运行的,但不能更改任何东西。为了增加可靠性,一般会在集群中设置两个磁盘节点,只要任何一个处于工作状态,就可以保障集群的正常服务。
HA 将服务分为两类:
- 有状态服务:后续对服务的请求依赖于之前对服务的请求。
- 无状态服务:对服务的请求之间没有依赖关系,是完全独立的。
HA 需要使用冗余的服务器组成集群来运行负载,包括应用和服务。这种冗余性也可以将 HA 分为两类:
- Active/Passive HA:集群只包括两个节点简称主备。在这种配置下,系统采用主和备用机器来提供服务,系统只在主设备上提供服务。在主设备故障时,备设备上的服务被启动来替代主设备提供的服务。典型地,可以采用 CRM 软件比如 Pacemaker 来控制主备设备之间的切换,并提供一个虚机 IP 来提供服务。
- Active/Active HA:集群只包括两个节点时简称双活,包括多节点时成为多主(Multi-master)。在这种配置下,系统在集群内所有服务器上运行同样的负载。以数据库为例,对一个实例的更新,会被同步到所有实例上。这种配置下往往采用负载均衡软件比如 HAProxy 来提供服务的虚拟 IP。
要实现 OpenStack HA,一个最基本的要求是这些节点都是冗余的。根据每个节点上部署的软件特点和要求,每个节点可以采用不同的 HA 模式。但是,选择 HA 模式有个基本的原则:
- 能 A/A 尽量 A/A,不能的话则 A/P (RedHat 认为 A/P HA 是 No HA)
- 有原生(内在实现的)HA方案尽量选用原生方案,没有的话则使用额外的HA 软件比如 Pacemaker 等
- 需要考虑负载均衡
- 方案尽可能简单,不要太复杂
云环境的 HA 将包括:
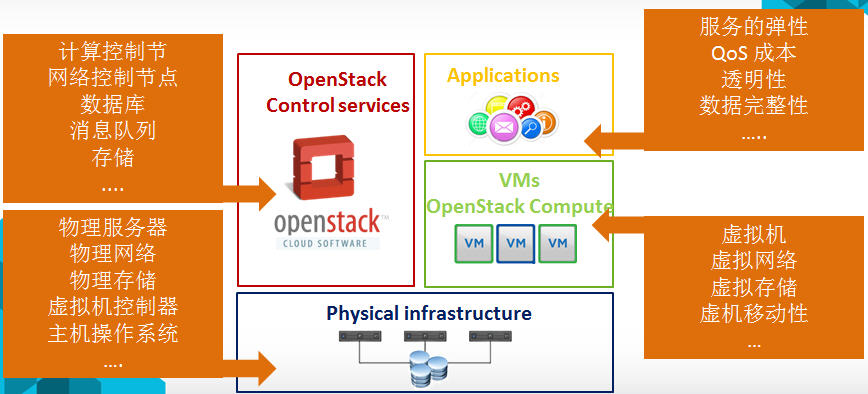
- 应用的 HA
- 虚机的 HA
- 云控制服务的 HA
- 物理IT层:包括网络设备比如交换机和路由器,存储设备等
- 基础设施,比如电力、空调和防火设施等
这里重点是讨论 OpenStack 作为 IaaS 的 HA。
OpenStack 官方认为,在满足其 HA 要求的情况下,可以实现 IaaS 的 99.99% HA,但是,这不包括单个客户机的 HA。
RabbitMQ A/P HA 官方方案 是采用 Pacemaker + (DRBD 或者其它可靠的共享 NAS/SNA 存储) + (CoroSync 或者 Heartbeat 或者 OpenAIS)组合来实现的。需要注意的是 CoroSync 需要使用多播,而多播在某些云环境中是被禁用的,这时候可以改为使用 Heartbeat,它采用单播。其架构为:
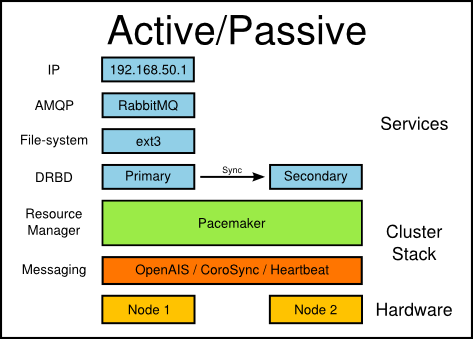
实现 HA 的原理:
- RabbitMQ 将数据库文件和持久性消息保存在 DRBD 挂载点上。注意,在 failover 时,非持久性消息会丢失。
- DRBD 要求在某一时刻,只能有一个 node (primary)能够访问其共享存储,因此,不会有多个node 同时写一块数据的风险。这要求必须依赖 Pacemaker 来控制使用 DRBD 共享存储的 node。Pacemaker 使得在某一时刻,只有 active node 来访问 DRBD 共享存储。在 failover 时,Pacemaker 会卸载当前 active node 上的 DRBD 共享存储,并在新的 active node (原 secondary node)上挂载 DRBD 共享存储。
- 在 node 启动时,不会自动启动 RabbitMQ。Pacemaker 会在 active node 启动 RabbitMQ。
- RabbitMQ HA 只会提供一个访问 RabbitMQ 的 虚拟IP 地址。该方案依赖 Pacemaker 来保证 VIP 的切换。
转载至:https://www.cnblogs.com/sammyliu/p/4730517.html
作者:SammyLIu
具体配置方式可以参考官网:https://www.rabbitmq.com/pacemaker.html
4.9.1. DRBD
DRBD 是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。您可以把它看作是一种网络RAID。
DRBD负责接收数据,把数据写到本地磁盘,然后发送给另一个主机。另一个主机再将数据存到自己的磁盘中。其他所需的组件有集群成员服务,如TurboHA 或 心跳连接,以及一些能在块设备上运行的应用程序。例如:裸I/O、文件系统及fsck、具有恢复能力的数据库。
下面是DRBD的系统结构图:
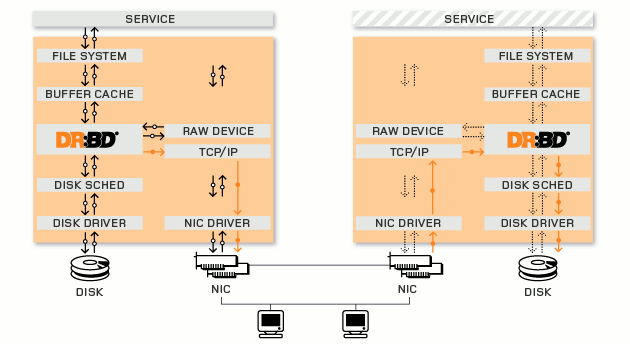
上图假设左节点为活动节点(实箭头),右节点为备用节点。左节点接收到数据发往内核的数据通路,DRBD在数据通路中注册钩子检查数据(类似ipvs),当发现接收到的数据是发往到自己管理的存储位置,就复制另一份,一份存储到本机的DRBD存储设备,另一份就发给TCP/IP协议栈,通过网卡网络传输到另一节点主机的网上TCP/IP协议栈;而另一节点运行的DRBD模块同样在数据通路上检查数据,当发现传输过来的数据时,就存储到DRBD存储设备对应的位置。
如果左节点宕机,右节点可以在高可用集群中成为活动节点,当接收到数据先存储到本地,当左节点恢复上线时,再把宕机后右节点变动的数据镜像到左节点。
镜像过程完成后还需要返回成功/失败的回应消息,这个回应消息可以在传输过程中的不同位置返回,如图上的A/B/C标识位置,可以分为三种复制模式:
A:Async, 异步,本地写成功后立即返回,数据放在发送buffer中,可能丢失,但传输性能好;
B:semi sync, 半同步;
C:sync, 同步,本地和对方写成功确认后返回,数据可靠性高,一般都用这种;
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在DRBD设备内创建文件系统。
DRBD所支持的底层设备有这些类别:磁盘,或者是磁盘的某一个分区;soft raid 设备;LVM的逻辑卷;EVMS(Enterprise Volume Management System,企业卷管理系统)的卷;或其他任何的块设备。
DRBD资源为DRBD管理的存储空间及相关信息,主要配置四个选项:
资源名称:可以是除了空白字符外的任意ACSII码字符;
DRBD设备:在双方节点上,此DRBD设备的设备文件;一般为/dev/drbdN,其主设备号147
磁盘:在双方节点上,各自提供的存储设备;
网络配置:双方数据同步时所使用的网络属性;
RAID1也是实现不同存储设备间的数据镜像备份的,不同的是RAID1各存储设备是连接一个RAID控制器接入到一台主机上的,而DRBD是通过网络实现不同节点主机存储设备数据的镜像备份。
作者:尐譽 原文链接:https://blog.csdn.net/tjiyu/article/details/52723125
4.10. 身份验证、授权和访问控制
术语和定义
认证和授权经常混淆或使用 可互换。 这是错误的,在 RabbitMQ 中,两者是 分开了。 为了简单起见,我们将定义 身份验证为“识别用户是谁”和 授权为“确定用户可以做什么和不允许做什么”。
身份验证:你说你是谁?
在应用程序连接到 RabbitMQ 之后,在它可以执行操作之前,它必须 认证,即呈现并证明其身份。 有了这个身份,RabbitMQ 节点就可以 查找其权限并 授权 访问资源 比如 虚拟主机 、队列、交换机等等。
验证客户端的两种主要方式是 用户名/密码对 和 X.509 证书 。
用户名/密码对 可以与各种 的 一起使用 身份验证后端 验证凭据 。 验证失败的连接将被关闭,并在 显示一条错误消息 服务器日志中 。
要使用内置插件 X.509 证书对客户端连接进行身份验证, rabbitmq-auth-mechanism-ssl , 必须启用并且客户端必须 配置为使用 EXTERNAL 机制 。 使用这种机制,任何客户端提供的密码都将被忽略。
授权:权限如何工作
当 RabbitMQ 客户端建立到一个服务器和 身份验证 ,它指定一个虚拟主机,它打算在其中 操作。 第一级访问控制在 此时,随着服务器检查用户是否有访问虚拟主机的任何权限,并拒绝 否则连接尝试。
资源,即交换器和队列,是命名实体 在特定的虚拟主机内; 同名表示一个每个虚拟主机中的不同资源。 第二级 当某些操作被强制执行时访问控制对资源执行。
RabbitMQ 区分 configure , 写 和 读 对 a 的 操作 资源。 在 配置 操作或创建 破坏资源,或改变它们的行为。 这 写 操作将消息注入到 资源。 而 读 操作检索邮件 从一个资源。
为了对资源执行操作,用户必须 已被授予适当的权限。 这 下表显示了对什么类型的什么权限 所有 AMQP 命令都需要资源 执行权限检查。
除了上述权限之外,用户还可以拥有标签 与他们有关。 目前只有管理 UI 访问由用户标签控制。
从 3.7.0 版本开始,RabbitMQ 支持主题交换的主题授权。 消息的路由键 发布到主题交换时会考虑 强制发布授权(例如在 RabbitMQ 默认授权后端, 路由键与正则表达式匹配以决定消息是否可以 是否路由到下游)。 主题授权针对 STOMP 和 MQTT 等协议,这些协议是结构化的 围绕主题并在幕后使用主题交换。
认证机制
RabbitMQ 支持多重 SASL 认证 机制。 内置了三种这样的机制 服务器: PLAIN , AMQPLAIN , 和 RABBIT-CR-DEMO ,还有一个 — EXTERNAL — 可作为插件使用。
**内置身份验证机制 **
内置机制是:
| 机制 | 描述 |
|---|---|
| PLAIN | SASL PLAIN 认证。 这在 RabbitMQ 服务器和客户端中默认启用,并且是大多数其他客户端的默认设置。 |
| AMQPLAIN | 保留非标准版本的 PLAIN 以实现向后兼容。 这在 RabbitMQ 服务器中默认启用。 |
| EXTERNAL | 使用带外机制进行身份验证,例如 x509 证书对等验证、客户端 IP 地址范围或类似机制。 这种机制通常由 RabbitMQ 插件提供。 |
| RABBIT-CR-DEMO | 演示质询-响应身份验证的非标准机制。 该机制具有等同于 PLAIN 的安全性,并且在 RabbitMQ 服务器中默认不启用。 |
认证和权限的具体配置方式可以参考官方文档:https://www.rabbitmq.com/access-control.html
LDAP 支持
RabbitMQ 可以使用 LDAP 进行 身份验证和 授权 通过遵循外部 LDAP 进行 服务器。 此功能由一个 RabbitMQ 附带但 插件 必须启用的 。 认证和授权操作是 转换为 LDAP 查询 用户配置的 。
一些基本 LDAP 术语。
| 学期 | 描述 |
|---|---|
| 绑定 | LDAP 代表“身份验证请求”。 |
| 专有名称 (DN) | 专有名称是 LDAP 目录(树)中标识对象的唯一键 (如用户或组)。 该插件会将客户端提供的用户名转换为 身份验证阶段的专有名称(见下文)。 一种思考方式 DN 是文件系统中的绝对文件路径。 |
| 通用名称 (CN) | 树中对象的简短标识符。 这个标识符会有所不同 LDAP 数据库中的对象类(类型)。 例如,一个人的常用名 将是她的全名。 组的通用名称将是该组的名称。 考虑 CN 的一种方式是文件系统中的文件名。 |
| 属性 | 对象的属性(键值对)。 把它想象成一个对象的字段 一种面向对象的编程语言。 |
| 项目等级 | 一组预定义的属性。 将其视为面向对象语言中的类型(类)。 |
| 入口 | 一个 LDAP 数据库实体,例如一个人或一个 团体。 它有一个与之关联的对象类,并且 一个或多个属性,包括一个通用名称。 由于实体位于 LDAP 中的某处 数据库树它也必须有一个专有名称 唯一标识它。 条目是什么 LDAP 插件查询使用(查找,检查成员资格, 比较属性等等)。 LDAP 数据库 必须有一些条目(通常是用户、组) 为了对RabbitMQ实际有用 身份验证和授权。 |
LDAP配置使用方式可以参考官网:https://www.rabbitmq.com/ldap.html
4.11. Firehose消息跟踪
有时,在开发或调试过程中, 能够看到发布的每条消息,以及每一条 传递的消息。 RabbitMQ 有一个“消息管道” 功能,管理员可以在其中启用(在每个节点上, 每个虚拟主机的基础)一个交换,发布和 交货通知应抄送。
这些通知与 线 - 例如,您将看到未确认的消息。
当它打开时,性能会下降。因为在某种程度上是由于生成了额外的消息和路由。
1 | 启用消息跟踪 |
Firehose 事件消息格式
firehose 将消息发布到主题交换 amq.rabbitmq.trace 。 在本节中,我们指的是消费和检查的消息 通过 Firehose 机制作为“跟踪消息”。
跟踪的消息路由键将是“ publish.{exchangename} ”(对于消息 进入节点),或“ deliver.{queuename} ”(用于传递给消费者的消息)。
包含有关原始消息的元数据的跟踪消息标头:
| Header | Type | Description |
|---|---|---|
| exchange_name | longstr | 消息发布到exchange的名称 |
| routing_keys | array | routing key密钥加上 CC 和 BCC 标头的内容 |
| properties | table | 内容属性 |
| node | longstr | 生成跟踪消息的 Erlang 节点 |
| redelivered | signedint | 消息是否设置了重新传递标志(仅离开代理的消息) |
4.12. rabbitmqctl命令参数
rabbitmqctl参数作用详细介绍可以参考官方文档:https://www.rabbitmq.com/rabbitmqctl.8.html
rabbitmq-diagnostics诊断、监控和健康检查工具命令可以参考:https://www.rabbitmq.com/rabbitmq-diagnostics.8.html
rabbitmq-plugins插件管理命令:https://www.rabbitmq.com/rabbitmq-plugins.8.html
rabbitmq-upgrade — RabbitMQ安装升级工具:https://www.rabbitmq.com/rabbitmq-upgrade.8.html
rabbitmq-queues — RabbitMQ 队列管理工具:https://www.rabbitmq.com/rabbitmq-queues.8.html
rabbitmq-server 命令:https://www.rabbitmq.com/rabbitmq-server.8.html
rabbitmq-env.conf — RabbitMQ 服务器使用的环境变量:https://www.rabbitmq.com/rabbitmq-env.conf.5.html
4.13. AMQP 0-9-1快速参考
AMQP是什么?
RabbitMQ就是 AMQP 协议的 Erlang 的实现(当然 RabbitMQ 还支持 STOMP2、 MQTT3 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。
RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
AMQP协议3层
Module Layer:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
Session Layer:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
TransportLayer:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
AMQP模型的几大组件
- 交换器 (Exchange):消息代理服务器中用于把消息路由到队列的组件。
- 队列 (Queue):用来存储消息的数据结构,位于硬盘或内存中。
- 绑定 (Binding):一套规则,告知交换器消息应该将消息投递给哪个队列。
主要讲解消息、channel、exchange、queue、事务参数说明:
https://www.rabbitmq.com/amqp-0-9-1-quickref.html
5. RabbitMQ客户端
基础使用可以参考官网教程,非常详细,有python,java,go等版本
https://www.rabbitmq.com/getstarted.html
6. RabbitMQ安装部署
6.1. docker 安装
1 | for RabbitMQ 3.8 |
6.2. Linux下安装 CentOS 7
1 | yum update -y |
1 | In /etc/yum.repos.d/rabbitmq_erlang.repo |
1 | 安装依赖 |
1 | In /etc/yum.repos.d/rabbitmq.repo |
1 | 安装完成,启动服务 |
6.3. 集群搭建
以下部署流程基本都是使用默认配置,生产环境请根据实际需求调整
官方文档:https://www.rabbitmq.com/clustering.html
一、如果使用阿里云等服务器首先记得开放访问端口,这几个端口需要开一下:25672,4369,5672,15672
然后我们可以先查看一下集群状况
1 | 第一步 是在所有节点上以正常方式启动RabbitMQ: |
二、使DNS对等方式:
1 | vi /etc/rabbitmq/rabbitmq.conf |
1 | cluster_formation.peer_discovery_backend = classic_config |
三、hostname可以通过在linux服务器上输入env hostname查看
RabbitMQ 节点使用域名相互寻址, 简短或完全限定 (FQDN)。 所以 所有集群成员的主机名 必须可从所有集群节点解析,以及 作为使用 等命令行工具的 rabbitmqctl 机器 可能会被使用。
接下来需要在/etc/hosts中配置你的hostname对应的ip地址
1 | vi /etc/hosts |
1 | xx.xx.xx.xx s-redis |
四、RabbitMQ 节点和 CLI 工具(例如 rabbitmqctl )使用 cookie 来确定他们是否被允许与 彼此。 要使两个节点能够通信,它们必须具有 相同的共享秘密称为 Erlang cookie。
1 | 先查看cookies文件位置: |
然后可以自己编写.erlang.cookie,再覆盖/var/lib/rabbitmq/.erlang.cookie
1 | vi .erlang.cookie |
所有集群节点cookies需要一致
五、接下来重启和重置你的rabbitmq节点服务
1 | /sbin/service rabbitmq-server restart |
六、最后查看你的集群连接状态,上图
1 | rabbitmqctl cluster_status |
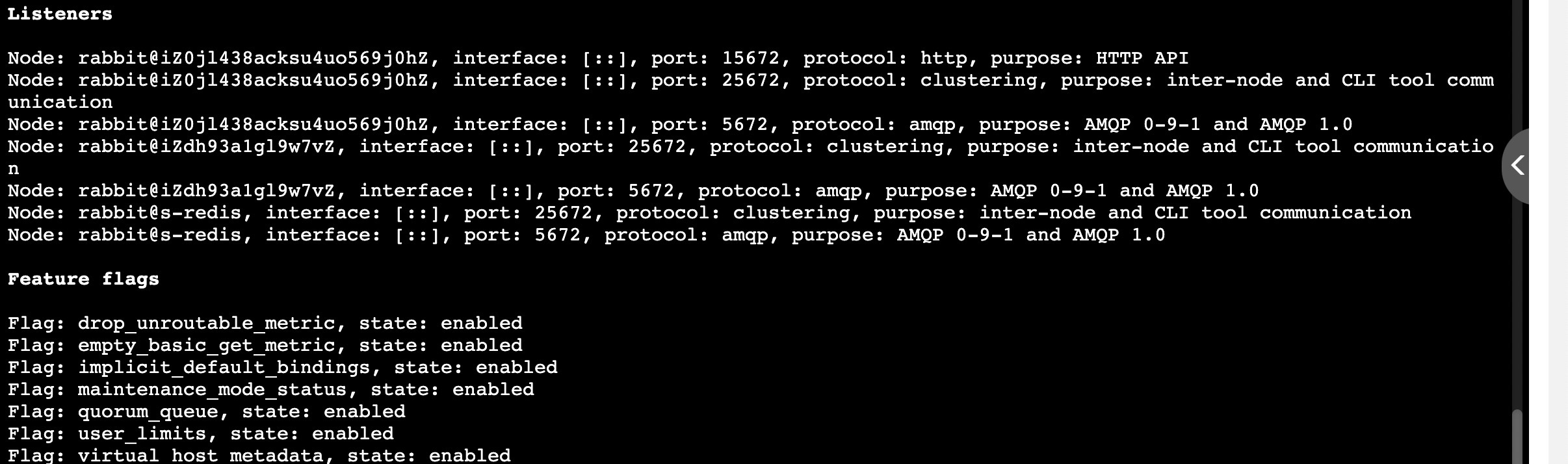
七、集群新增节点
1 | 第一步先修改/etc/hosts |
八、集群删除节点
1 | 在想删除的节点停止就可以了 |
九、其他对等发现
要形成集群,新的(“空白”)节点需要能够发现 他们的同龄人。 这可以使用各种机制(后端)来完成。 一些机制假设所有集群成员都是提前知道的(例如,列出 在配置文件中),其他是动态的(节点可以来来去去)。
所有对等发现机制都假设新加入的节点能够 联系他们在集群中的对等方并成功地与他们进行身份验证。 依赖外部服务(例如 DNS 或 Consul)或 API(例如 AWS 或 Kubernetes)的机制 要求服务或 API 在其标准端口上可用且可访问。 无法访问服务将导致节点无法加入集群。
默认情况下,对等发现将使用私有 DNS 主机名来计算节点名称。 这个选项最方便, 强烈推荐 。
除了上述的DNS对等,还有AWS对等、Kubernetes对等、Consul对等、Etcd对等。
这几个对等发现都是使用插件的形式,需要一些依赖,可以参考官方文档:
https://www.rabbitmq.com/cluster-formation.html
6.4. 集群迁移
节点和集群存储可以被认为是模式、元数据或拓扑的信息。 用户、虚拟主机、队列、交换器、绑定、运行时参数都属于这一类。 此元数据 称为 定义 在 RabbitMQ 中 。
定义可以 导出 到一个文件,然后 导入 到另一个集群或 用于模式 备份 或数据播种。
定义存储在内部数据库中并在所有集群节点之间复制。 集群中的每个节点都有自己所有定义的副本。 当部分定义发生变化时, 更新在单个事务中的所有节点上执行。 这意味着 实际上,定义可以从任何集群节点导出,结果相同。
VMware Tanzu RabbitMQ 支持将 架构定义连续复制 到远程集群, 这使得运行热备集群进行灾难恢复变得容易。
节点启动时的定义导入是 的推荐方式 在部署时预配置节点 。
原数据导出
1 | 不需要启用管理插件,RabbitMQ 3.8.2 新增 |
原数据导入
1 | 不需要启用管理插件,RabbitMQ 3.8.2 新增 |
详细迁移文档可以参考官网:https://www.rabbitmq.com/definitions.html
通过连续定义复制实现热备
VMware Tanzu RabbitMQ 支持连续模式定义复制到远程集群,可以轻松运行热备集群进行容灾。
该插件的复制模型有许多特性和限制:
- 它传输定义(模式)但 不传输入队消息
- 同步会定期发生,因此对于易变的拓扑,追随者将始终 落后于领导者。 同步间隔为 30 秒时,延迟通常为 一分钟内。
- 跟随者端的模式(虚拟主机、用户、队列等)被替换为 在领导者方面
- 双方之间的所有通信都是完全异步的,避免引入集群相互依赖
- 除初始导入外,定义以增量方式传输和导入
- 定义以压缩的二进制格式传输以减少带宽使用
- 到其他集群的链接很容易配置和推理,特别是在灾难恢复事件期间
如果发生灾难事件,恢复过程包括几个步骤:
- 一个备用集群将被提升为运营商
- 应用程序将被重新部署或重新配置以连接到新提升的集群
- 其他备用集群必须重新配置以跟随新提升的集群
正如本指南后面所解释的,升级和重新配置是即时发生的, 并且 不涉及 RabbitMQ 节点重启 或重新部署。
与任何其他 RabbitMQ 插件一样 , rabbitmq_schema_definition_sync 必须 使用前必须启用。 通常这个插件应该是 预先配置 或启用为 –offline 在节点启动之前 :
1 | $ rabbitmq-plugins enable rabbitmq_schema_definition_sync --offline |
该插件在模式复制链接(连接)上有两个方面:
- 源集群,又名“原点”,又名 上游 (借用联邦插件中的一个术语)
- 目标集群,又名跟随者,又名 下游
一个上游可以有多个下游; 本文件主要讨论 为简单起见,单个上游,单个下游场景。
下游连接到上游并定期启动同步操作。 这些 操作将下游侧的模式与上游的模式同步, 具有一些安全机制(本指南稍后介绍)。
在下游模式下运行的节点(跟随者)可以 转换为上游 (领导者) 在飞行中。 这将使它与原始来源断开连接,因此停止所有 同步。 然后该节点将继续作为独立集群的成员运行, 不再与其原始上游相关联。
这种转换称为 升级 ,应在发生灾难时执行 恢复事件。
同步操作是一个请求/响应序列,涉及:
- 下游发送的同步请求
- 上游发回的同步响应
同步请求携带一个有效载荷,允许上游计算之间的增量 模式。 同步响应携带增量加上所有定义 存在于上游或冲突。 下游将使用此信息 应用定义。 任何 仅存在于下游的实体都将被删除 。 这是为了确保下游与上游的架构一样紧密可能,但有一些实际限制(在本指南中进一步讨论)。
下游使用 AMQP 1.0 连接到上游。 这有几个好处:
- 所有通信都是异步的,没有耦合,一个备用就可以运行RabbitMQ 的不同(例如更新)版本
- 身份验证与应用程序的身份验证相同
- 不需要打开额外的端口
上游和它的跟随者(下游)是松散连接的。 如果模式复制连接的一端出现故障,集群模式之间的增量将 增长,但不会以任何其他方式受到影响。 如果上游低于 服务定义请求的负载过多或同步插件是无意的 禁用,下游根本不会收到同步请求的响应 一段时间。
如果下游未能应用定义,则上游不受影响,也不受影响 其下游同行。 因此双方同步的可用性 链接不依赖于另一端的链接。
当多个下游从共享上游同步时,它们不会干扰 或相互协调。 双方都需要做更多的工作。 上 在上游,该负载由所有集群节点分担。 在下游 一边,假设应用了同步操作,实践中的负载应该是最小的 成功,因此增量不会累积。
拥有一个具有同步虚拟主机、用户、权限、拓扑的备用集群等等只有在它发生灾害事件可以变成一个新的主集群时才有用。 在本指南中,我们将提及此类事件作为下游推广 。
一个提升的下游变成一个“常规”集群,如果需要,它可以自己服务作为上游。 它不会从其原始上游同步,但可以提供同步 操作请求。
下游推广涉及下游的几个步骤:
- 复制已停止
- 执行上游设置
- 节点模式切换到上游
- 复制已恢复
所有这些步骤都是使用 CLI 工具执行的,不需要节点 重新开始
更多同步配置可以参考官方文档:https://www.rabbitmq.com/definitions-standby.html
集群备份还原可以参考:https://www.rabbitmq.com/backup.html
warren和Shovel:故障转移和复制
看了一篇博客感觉还不错,后面遇到的话自己再去证实一下吧。
7. RabbitMQ管理界面
概述
RabbitMQ 管理插件提供了一个基于 HTTP 的 API 来管理和监控 RabbitMQ 节点和集群,以及一个基于浏览器的 UI 和一个命令行工具 rabbitmqadmin。 它定期收集和汇总有关系统许多方面的数据。 这些指标在 UI 和监控系统中向操作员公开,用于长期存储、警报、可视化、图表分析等。 该插件可以配置为使用 HTTPS、OAuth 2、非标准端口、路径前缀、HTTP 服务器选项、自定义严格传输安全设置、跨源资源共享等。
用法
管理插件包含在 RabbitMQ 发行版中。 像任何其他插件一样,它必须先启用才能使用。 这是使用rabbitmq-plugins完成的:
1 | rabbitmq-plugins enable rabbitmq_management |
可以使用 Web 浏览器在 访问管理 UI http:// {node-hostname} :15672/
访问和权限
管理 UI 需要 身份验证和授权,很像 RabbitMQ 需要 它来自连接客户端。 除了成功的身份验证之外,管理 UI 访问还由用户标签控制。 标签使用进行管理 rabbitmqctl。 默认情况下,新创建的用户没有设置任何标签。
以下示例创建了一个对管理 UI/HTTP API(如所有虚拟主机和管理功能)具有完全访问权限的用户:
1 | 创建一个用户 full_access用户名, s3crEt密码 |
管理插件可以配置为使用 HTTPS。 请参阅 的指南 有关 TLS 了解有关证书颁发机构、证书和私钥文件的更多信息。
1 | management.ssl.port = 15671 |
统计区间
默认情况下,服务器将每隔 5 秒( 5000 毫秒)。 管理中显示的消息速率值 插件是在此期间计算的。
增加此值将减少 CPU 资源消耗 在有大量统计数据的环境中收集统计数据 实体如 连接 、 通道 、 队列 。
为此,请设置 的值 collect_statistics_interval 配置键 到所需的时间间隔(以毫秒为单位)并重新启动节点:
1 | # 15s |
样本(数据点)保留
管理插件会保留一些数据的样本 例如消息速率和队列长度。 取决于多长时间数据被保留,一段时间 UI 图表上的范围选项可能不完整或不可用。
共有三项政策:
- global :概述和虚拟主机页面的数据保留多长时间
- basic :单个连接、通道、交换和队列的数据保留多长时间
- detailed:连接、通道、交换和队列对之间的消息速率数据保留多长时间(如“消息速率细分”所示)
下面是一个配置示例:
1 | management.sample_retention_policies.global.minute = 5 |
放几张管理界面的图片

更多管理界面配置可以参考官网地址:https://www.rabbitmq.com/management.html
8. RabbitMQ监控
定义
在本指南中,我们将监控定义为一个过程 随着时间的推移,通过健康检查和指标捕获系统的行为。 这有助于检测异常:当系统不可用、遇到异常负载时, 耗尽某些资源或以其他方式在其正常范围内运行 (预期)参数。 监控涉及长期收集和存储指标, 这对于异常检测更重要 还有根本原因分析、趋势检测和容量规划。
监控系统通常与警报系统集成。 当监控系统检测到异常时,通常会发出某种警报 传递给警报系统,该系统通知相关方,例如技术运营团队。
监控到位意味着系统行为的重要偏差, 从某些地区的服务降级到完全不可用,更容易 检测和根本原因需要更少的时间来找到。 在没有监控数据的情况下运行分布式系统有点像试图走出森林 没有 GPS 导航设备或指南针。 无论多么聪明或经验丰富 这个人是,拥有相关信息对于 一个好的结果。
基础设施和内核指标
迈向有用监控系统的第一步始于基础设施和 内核指标。 其中有很多,但有些比其他更重要。 在运行 RabbitMQ 节点或应用程序的所有主机上收集以下指标:
- CPU 统计信息(用户、系统、iowait 和空闲百分比)
- 内存使用(已用、缓冲、缓存和空闲百分比)
- 虚拟内存 统计信息(脏页刷新、回写量)
- 磁盘 I/O(操作和每单位时间传输的数据量、服务操作的时间)
- 用于 的挂载上的可用磁盘空间 节点数据目录
- 使用的 beam.smp 文件描述符 与 最大系统限制
- TCP 连接状态( ESTABLISHED , CLOSE_WAIT , TIME_WAIT )
- 网络吞吐量(接收的字节数、发送的字节数)和最大网络吞吐量
- 网络延迟(集群中所有 RabbitMQ 节点之间以及与客户端之间的延迟)
不乏收集基础设施的现有工具(例如 Prometheus 或 Datadog) 和内核指标,在一段时间内存储和可视化它们。
管理 UI 和外部监控系统
RabbitMQ 带有一个 管理 UI 和 HTTP API ,它公开了许多 RabbitMQ 指标 用于节点、连接、队列、消息速率等。 这是一个方便的开发选项 在难以或不可能引入外部监控的环境中。
但是,管理 UI 有许多限制:
- 监控系统与被监控系统交织在一起
- 一定的开销
- 它只存储最近的数据(想想几小时,而不是几天或几个月)
- 它有一个基本的用户界面
- 其设计 强调易用性而非最佳可用性 。
- 管理 UI 访问通过 RabbitMQ 权限标签系统进行控制 (或 JWT 令牌范围的约定)
等长期指标存储和可视化服务 Prometheus 和 Grafana 或 ELK 堆栈 更适合生产系统。 他们提供:
- 监控系统与被监控系统的解耦
- 降低开销
- 长期指标存储
- 访问其他相关指标,如 Erlang运行 的人
- 更强大和可定制的用户界面
- 易于共享指标数据:指标状态和仪表板
- 指标访问权限并非特定于 RabbitMQ
- 收集和聚合特定于节点的指标,对单个节点故障更具弹性
集群范围的指标
集群范围的指标提供集群状态的高级视图。 其中一些描述了交互 节点之间。 此类指标的示例是集群链接流量和检测到的网络分区。 其他人将所有集群成员的指标结合起来。 到所有节点的完整连接列表将 成为一个例子。 这两种类型都是对基础设施和节点指标的补充。
GET /api/overview 是 的 HTTP API 返回集群范围指标 端点。
GET /api/nodes/{node} 返回单个节点的统计信息
基于命令行的观察者工具
rabbitmq-diagnostics observer 是一个类似于 的命令行工具 top 、 htop 、 vmstat 。 这是一个命令行 替代品 Erlang 的 Observer 应用程序的 。 它提供 访问许多指标,包括各个 详细状态 运行时 进程的 :
- 运行时版本信息
- CPU 和计划统计信息
- 内存分配和使用统计
- 按 CPU(减少)和内存使用情况划分的顶级进程
- 网络链接统计
- 详细的进程信息,例如基本的 TCP 套接字统计信息
监测频率
许多监控系统定期轮询它们的监控服务。 完成的频率因工具而异,但通常可由操作员配置。 非常频繁的轮询会对受监控的系统产生负面影响。 例如,打开与节点的测试 TCP 连接的过多负载均衡器检查会导致高连接流失。 RabbitMQ 中对通道和队列的过多检查会增加其 CPU 消耗。 当一个节点上有很多(例如,数千个)它们时,差异可能会很大。 建议的指标收集间隔为 15 秒。 要以更接近实时的时间间隔收集,请使用 5 秒 - 但不能更低。 对于速率指标,请使用跨越 4 个指标收集间隔的时间范围,以便它可以容忍竞争条件并能够灵活应对抓取失败。 对于生产系统,建议收集间隔为 30 甚至 60 秒。 Prometheus 导出器 API 旨在每 15 秒抓取一次,包括生产系统。
更多监控说明可以参考官方文档:https://www.rabbitmq.com/monitoring.html
9. RabbitMQ插件
RabbitMQ 支持插件。 插件以多种方式扩展核心代理功能:支持 更多协议,系统状态 监控,额外的 AMQP 0-9-1 交换类型, 节点 联合等等。 许多功能是作为插件实现的。
下表列出了 RabbitMQ 附带的第 1 层(核心)插件。
| 插件名称 | 描述 |
|---|---|
| rabbitmq_amqp1_0 | AMQP 1.0 协议支持。 这个插件有几年了,中等 成熟。 它可能有一定的局限性 架构,但大多数主要的 AMQP 1.0 功能应该在 地方。 |
| rabbitmq_auth_backend_ldap | 使用外部的身份验证和授权插件LDAP 服务器。 |
| rabbitmq_auth_backend_http | 使用外部 HTTP API 的身份验证和授权插件。 |
| rabbitmq_auth_mechanism_ssl | 使用 SASL EXTERNAL 进行身份验证的身份验证机制插件 使用 TLS (x509) 客户端证书。 |
| rabbitmq_consistent_hash_exchange | 一致的哈希交换。 |
| rabbitmq_federation | 跨 WAN 和管理的可扩展消息传递域。 |
| rabbitmq_federation_management | 在管理 API 和 UI 中显示联合状态。 仅有的结合使用 rabbitmq_federation 时的使用 rabbitmq_management 。 在异构集群中,这 应该安装在与 rabbitmq_management 相同的节点上。 |
| rabbitmq_management | 基于 HTTP 的管理/监控 API,以及基于浏览器的用户界面。 |
| rabbitmq_management_agent | 在 安装管理插件时, 某些设备集群中的节点, rabbitmq_management_agent 必须在所有设备上启用,在 所有 集群节点节点上,否则某些节点的统计信息不会被收集。 |
| rabbitmq_mqtt | MQTT 3.1.1 支持。 |
| rabbitmq_prometheus | Prometheus 监控支持。 |
| rabbitmq_shovel | RabbitMQ 的一个插件,用于从队列中铲出消息 一个经纪人到另一个经纪人的交易所。 |
| rabbitmq_shovel_management | 显示 Shovel 在管理 API 和 UI 中 状态。 使用时,只使用 rabbitmq_shovel 在 与 结合使用 rabbitmq_management 。 在一个 异构集群,这应该安装在同一个 节点作为 RabbitMQ 管理插件 。 |
| rabbitmq_stomp | 提供 STOMP 协议 在 RabbitMQ 中 支持。 |
| rabbitmq_tracing | 向管理插件添加消息跟踪。 日志从消息流水中几种格式。 |
| rabbitmq_trust_store | 提供客户端 x509 证书信任库。 |
| rabbitmq_web_stomp | STOMP-over-WebSockets:将 暴露 的桥梁 rabbitmq_stomp 给网络 使用 WebSockets 的浏览器。 |
| rabbitmq_web_mqtt | MQTT-over-WebSockets:一个将 暴露 的桥梁 rabbitmq_mqtt 给 Web 使用 WebSocket 的浏览器。 |
| rabbitmq_web_stomp_examples | 添加一些基本示例 rabbitmq_web_stomp :一个简单的“回声”服务 和一个基本的基于画布的协作工具。 |
| rabbitmq_web_mqtt_examples | 添加一些基本示例 rabbitmq_web_mqtt :一个简单的“回声”服务 和一个基本的基于画布的协作工具。 |
rabbitmq-plugins插件管理命令:https://www.rabbitmq.com/rabbitmq-plugins.8.html
插件基本介绍:https://www.rabbitmq.com/plugins.html
每个插件详细介绍可以进入基本介绍下的对应插件介绍。
10. RabbitMQ基准测试
10.1. RabbitMQ 如何测试
您已经通过 RabbitMQ 集群每秒路由 X 条消息并得出结论,您已达到峰值吞吐量,但您是否考虑过:
- 您的 CPU 在那一点上已达到最大值,并且无法应对高于该负载的任何峰值
- 您已接近网络带宽、磁盘 IOP 等,并且无法应对该负载之上的任何峰值
- 您的端到端延迟以分钟为单位,而不是毫秒
- 你丢失了数千条消息,因为你没有使用确认或确认,同时给经纪人和网络带来了巨大的压力。
您必须能够看到的不仅仅是吞吐量数字。
从 3.8.0 开始,我们提供了 rabbitmq_prometheus 插件。 了解如何 让 Grafana、Prometheus 和 RabbitMQ 协同工作并深入了解您的 RabbitMQ 实例。
查看我们 发布的 Grafana 仪表板 幕后 ,不仅可以深入了解队列数、连接数、消息速率等,还可以从 Erlang 的角度深入了解 发生的事情。 您还可以安装无数系统指标仪表板和代理,以查看系统指标,例如 CPU、RAM、网络和磁盘 IO。 例如,查看 node_exporter ,它可以深入了解硬件和操作系统行为。
使用 Prometheus 之类的解决方案的另一个原因是,当您将 RabbitMQ 推到极限时,管理 UI 可能会变得缓慢或无响应。 UI 正在尝试在可能已经接近 100% CPU 使用率的机器上运行。
10.2. 对性能的一些常见影响
当您改变基准的不同方面时,您可以期待以下一些事情。
- 一个队列有吞吐量限制,因此创建几个队列可以增加总吞吐量。 但是创建数百个队列会降低总吞吐量。 每个 CPU 线程一两个队列往往会提供最高的吞吐量。 不仅如此,上下文切换还会降低效率。
- 使用发布者确认和消费者确认比不使用它们具有更低的吞吐量。 但是当使用数百个发布者和队列时,发布者确认实际上可以提高性能,因为它们充当发布者的有效背压机制 - 避免吞吐量的大幅波动(了解有关 更多信息 流量控制的 )。
- 发送一条消息,等待发布者确认,然后发送下一条等等,非常非常慢。 与发布者一起使用批处理或流水线策略可显着提高吞吐量( https://www.rabbitmq.com/tutorials/tutorial-seven-java.html 或 https://www.rabbitmq.com/tutorials/tutorial-seven- dotnet.html )
- 不使用消费者预取会增加吞吐量(但不建议这样做,因为它会压倒消费者 - 预取是我们对 RabbitMQ 施加压力的方式)。 预取为 1 将显着降低吞吐量。 尝试使用预取来为您的工作负载找到合适的值。
- 发送小消息会增加吞吐量(尽管 MB/s 会很低),发送大消息会降低吞吐量(但 MB/s 会很高)。
- 拥有少数发布者和消费者将导致最高的吞吐量。 创建数千将导致较低的总吞吐量。
- 经典队列比复制队列(镜像/仲裁)更快。 复制因子越大,队列越慢。
一种常见的模式是,一旦超过几十个队列和/或客户端,总吞吐量就会下降。 连接和连接越多,上下文切换就越多,效率也就越低。 只有有限数量的 CPU 内核。 如果您有数千个队列和客户端,那么这并不是一件坏事,但要意识到与拥有数十或数百个客户端/队列时相比,您可能无法获得相同的总吞吐量。
10.3. 开始测试
您可以使用以下命令以这些强度运行此工作负载:
1 | bin/runjava com.rabbitmq.perf.PerfTest \ |
只需将 –rate 参数更改为每次测试所需的费率,并记住它是每个发布商的费率,而不是总组合费率。 由于消费者处理时间(消费者延迟)设置为 10 毫秒,我们还需要增加消费者数量以获得更高的发布率。
在运行 PerfTest 之前,您需要创建一个策略,将创建的队列转换为具有一个主节点和要测试的镜像数量的镜像队列。
下面对集群使用不同数量节点进行了测试,详细可以查看:https://blog.rabbitmq.com/posts/2020/06/cluster-sizing-case-study-mirrored-queues-part-1