
1. kafka基本认识
1.1. kafka简介
Apache Kafka 是目前最流行的开源流处理软件之一,用于大规模收集、处理、存储和分析数据。它以其卓越的性能、低延迟、容错和高吞吐量而闻名,每秒能够处理数千条消息。拥有 1,000 多个 Kafka 用例并且还在不断增加,一些常见的好处是构建数据管道、利用实时数据流、支持运营指标以及跨无数来源的数据集成。
1.2. kafka关键功能
发布(写)和订阅(读)流事件,包括来自其他系统的数据的持续导入/导出的。
为了存储持久和可靠的事件流,只要你想要的。
在事件发生时或追溯性地处理事件流。
所有这些功能都是以分布式、高度可扩展、弹性、容错和安全的方式提供的。Kafka 可以部署在裸机硬件、虚拟机和容器上,也可以部署在本地和云端。您可以在自行管理 Kafka 环境和使用各种供应商提供的完全托管服务之间进行选择。
1.3. kafka是如何工作的
Kafka 是一个分布式系统,由通过高性能TCP 网络协议进行通信的服务器和客户端组成。
服务器:Kafka 作为一个或多个服务器的集群运行,这些服务器可以跨越多个数据中心或云区域。其中一些服务器形成存储层,称为节点(broker)。其他服务器运行 Kafka Connect以将数据作为事件流持续导入和导出,从而将 Kafka 与您现有的系统(例如关系数据库以及其他 Kafka 集群)集成。为了让您实现关键任务用例,Kafka 集群具有高度可扩展性和容错性:如果其中任何一个服务器出现故障,其他服务器将接管它们的工作,以确保连续运行而不会丢失任何数据。
客户端:它们允许您编写分布式应用程序和微服务,即使在网络问题或机器故障的情况下,它们也可以并行、大规模和容错方式读取、写入和处理事件流。Kafka 附带了一些这样的客户端,这些客户端由 Kafka 社区提供的数十个客户端进行了扩充 :客户端可用于 Java 和 Scala,包括更高级别的 Kafka Streams库,用于 Go、Python、C/C++ 和许多其他编程语言以及 REST API。
1.4. kafka整体结构图
1.5. kafka主要概念
一个事件记录,在整体上或者在您的业务上记录“事件发生”的事实。它在文档中也称为记录或消息。当您向 Kafka 读取或写入数据时,您以事件的形式执行此操作。从概念上讲,事件具有键、值、时间戳和可选的元数据标头。这是一个示例事件:
- 事件键:“爱丽丝”
- 事件价值:“向鲍勃支付了 200 美元”
- 事件时间戳:“2020 年 6 月 25 日下午 2:06”
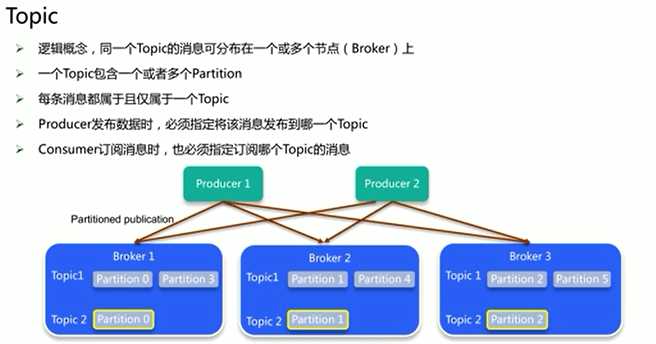
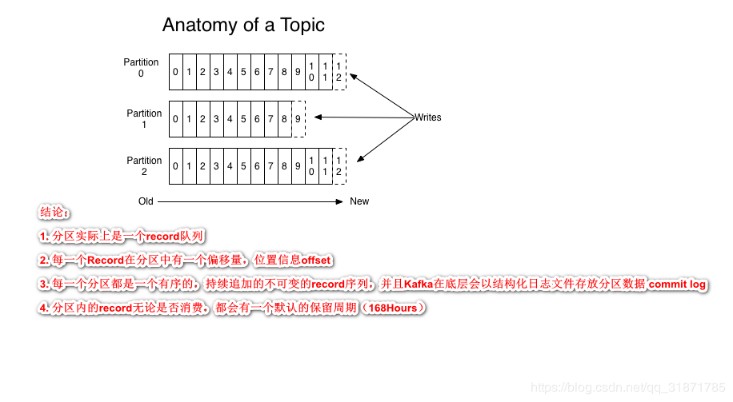
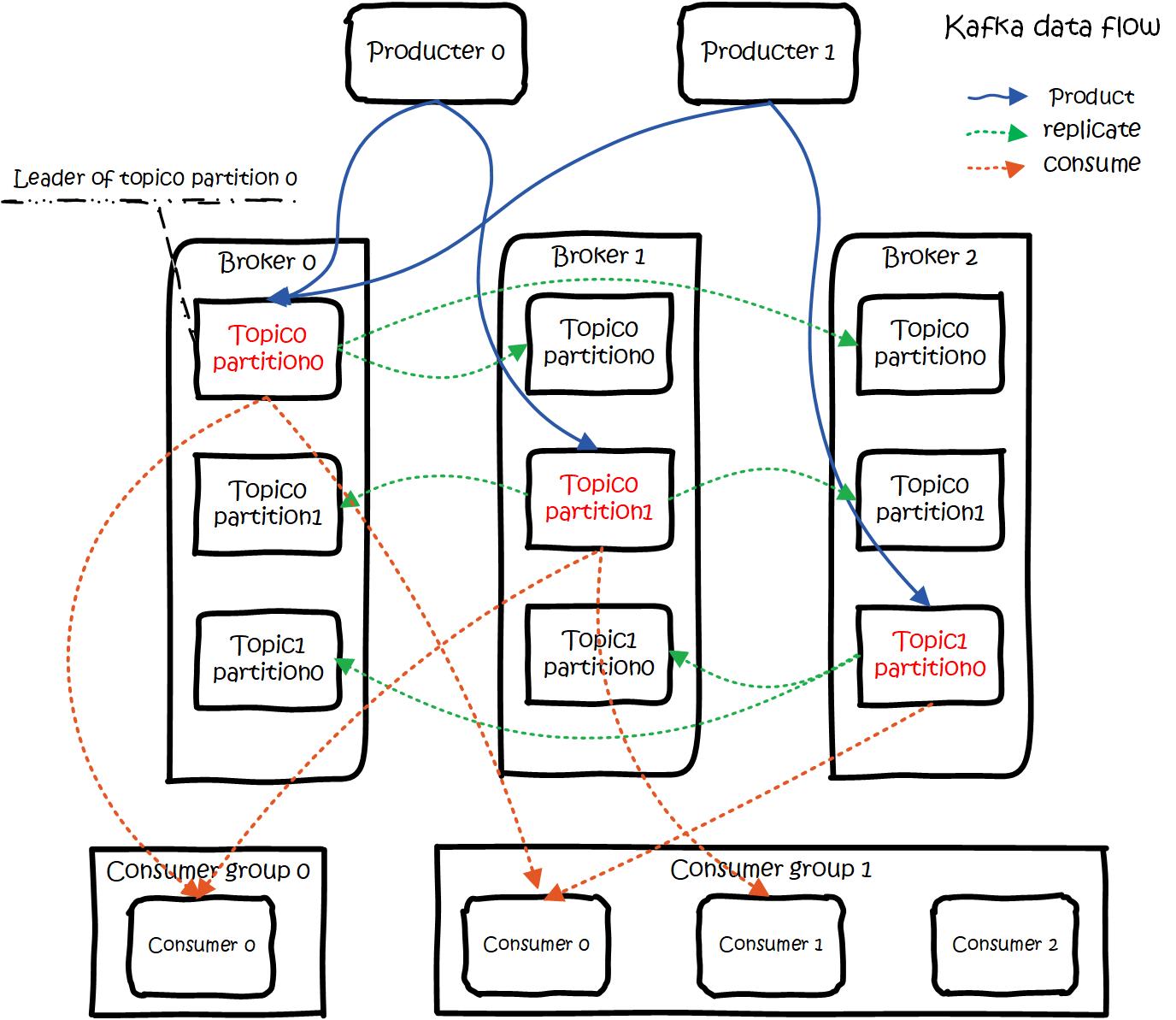
事件被组织并持久地存储在主题中(topic)。非常简单,主题类似于文件系统中的文件夹,事件就是该文件夹中的文件。一个示例主题名称可以是“支付”。Kafka 中的主题总是多生产者和多订阅者(消费者):一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。可以根据需要随时读取主题中的事件——与传统消息传递系统不同,事件在消费后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应该保留您的事件多长时间,之后旧事件将被丢弃。Kafka 的性能在数据大小方面实际上是恒定的,因此长时间存储数据是完全没问题的。
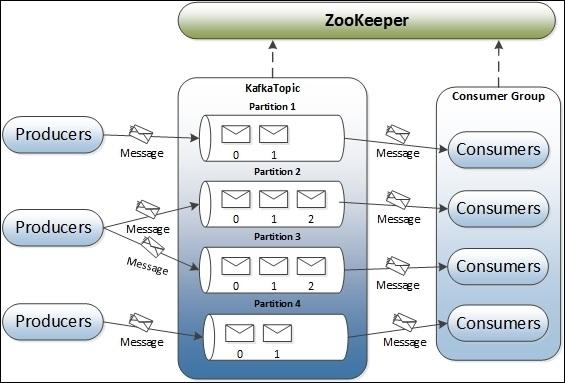
图1.5.1事件(图中message可理解为event(事件), Topic有4个分区Partition1到4)
生产者是那些向 Kafka 发布(写入)事件的客户端应用程序,而消费者是订阅(读取和处理)这些事件的那些客户端应用程序。在 Kafka 中,生产者和消费者之间是完全解耦和不可知的,这是实现 Kafka 众所周知的高可扩展性的关键设计元素。例如,生产者永远不需要等待消费者。Kafka 提供了各种保证,例如能够一次处理事件。
主题是分区的(上图分为4个片区),这意味着一个主题分布在位于不同 Kafka broker的多个“桶”上。数据的这种分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从/向多个broker(节点)读取和写入数据。当一个新事件发布到一个主题时,它实际上被附加到该主题的分区之一。具有相同事件键(例如,客户或车辆 ID)的事件被写入同一分区,并且 Kafka保证给定主题分区的任何消费者将始终以与写入事件完全相同的顺序读取该分区的事件(同一组消费者只能消费一次,被读取的消息并不会删除,由offset记录消费)。
1.6. kafka用例
- Kafka 可用于消息传递,消息传递使用的吞吐量通常相对较低,但可能需要较低的端到端延迟,并且通常依赖于 Kafka 提供的强大的持久性保证。与大多数消息系统相比,Kafka 具有更好的吞吐量、内置分区、复制和容错,这使其成为大规模消息处理应用程序的良好解决方案。
在这个领域,Kafka 可与传统的消息传递系统(如ActiveMQ或 RabbitMQ)相媲美。
Kafka可用于网站活动追踪,站点活动(页面查看、搜索或用户可能采取的其他操作)被发布到中心主题,每个活动类型有一个主题。这些提要可用于订阅一系列用例,包括实时处理、实时监控以及加载到 Hadoop 或离线数据仓库系统以进行离线处理和报告。
活动跟踪通常非常大量,因为每次用户页面查看都会生成许多活动消息。
Kafka 常用于操作监控数据。这涉及聚合来自分布式应用程序的统计数据以生成操作数据的集中提要。
Kafka 可以作为日志聚合解决方案的替代品。与 Scribe 或 Flume 等以日志为中心的系统相比,Kafka 提供了同样出色的性能、由于复制而产生的更强的持久性保证以及更低的端到端延迟。
Kafka 可以作为分布式系统的一种外部提交日志。日志有助于在节点之间复制数据,并作为故障节点恢复其数据的重新同步机制。Kafka 中的日志压缩功能有助于支持这种用法。
Kafka可用于流处理(Kafka Streams),从 Kafka 主题中消费原始输入数据,然后聚合、丰富或以其他方式转换为新主题,以供进一步消费或后续处理。
例如,用于推荐新闻文章的处理管道可能会从 RSS 提要中抓取文章内容并将其发布到“文章”主题;进一步处理可能会对该内容进行规范化或重复删除,并将清理后的文章内容发布到新主题;最后的处理阶段可能会尝试向用户推荐此内容。此类处理管道基于各个主题创建实时数据流图。
1.7. kafka版本变化
各版本之间差异可参考官方文档:入门->升级,地址https://kafka.apache.org/documentation/#upgrade Kafka总共发布了7个大版本,分别是0.7.x、0.8.x、0.9.x、0.10.x、0.11.x、1.x及2.x版本。
0.7.x版本
这是很老的Kafka版本,它只有基本的消息队列功能,连消息副本机制都没有,不建议使用。
0.8.x版本
两个重要特性,一个是Kafka 0.8.0增加了副本机制,另一个是Kafka 0.8.2.0引入了新版本Producer API。新旧版本Producer API如下:
1 | //旧版本Producer |
与旧版本相比,新版本Producer API有点不同,一是连接Kafka方式上,旧版本的生产者及消费者API连接的是Zookeeper,而新版本则连接的是Broker;二是新版Producer采用异步方式发送消息,比之前同步发送消息的性能有所提升。但此时的新版Producer API尚不稳定,不建议生产使用。
0.9.x版本
Kafka 0.9 是一个重大的版本迭代,增加了非常多的新特性,主要体现在三个方面:
- 安全方面:在0.9.0之前,Kafka安全方面的考虑几乎为0。Kafka 0.9.0 在安全认证、授权管理、数据加密等方面都得到了支持,包括支持Kerberos等。
- 新版本Consumer API:Kafka 0.9.0 重写并提供了新版消费端API,使用方式也是从连接Zookeeper切到了连接Broker,但是此时新版Consumer API也不太稳定、存在不少Bug,生产使用可能会比较痛苦;而0.9.0版本的Producer API已经比较稳定了,生产使用问题不大。
- Kafka Connect:Kafka 0.9.0 引入了新的组件 Kafka Connect ,用于实现Kafka与其他外部系统之间的数据抽取。
0.10.x版本
Kafka 0.10 是一个重要的大版本,因为Kafka 0.10.0.0 引入了 Kafka Streams,使得Kafka不再仅是一个消息引擎,而是往一个分布式流处理平台方向发展。0.10 大版本包含两个小版本:0.10.1 和 0.10.2,它们的主要功能变更都是在 Kafka Streams 组件上。
- 将
--new-consumer/--new.consumer开关不再需要使用的工具,像MirrorMaker和控制台与消费者新的消费; 一个人只需要通过一个 Kafka broker来连接而不是 ZooKeeper 集合。此外,旧消费者已弃用控制台消费者,它将在未来的主要版本中删除。 - 由于为每个段添加了时间索引文件,0.10.0 的打开文件处理程序将增加约 33%。
- Zookeeper 依赖项已从 Streams API 中删除。Streams API 现在使用 Kafka 协议来管理内部主题,而不是直接修改 Zookeeper。这消除了直接访问 Zookeeper 权限的需要,并且不应再在 Streams 应用程序中设置“StreamsConfig.ZOOKEEPER_CONFIG”。如果 Kafka 集群受到保护,则 Streams 应用程序必须具有创建新主题所需的安全权限。
值得一提的是,自 0.10.2.2 版本起,新版本 Consumer API 已经比较稳定了,而且 Producer API 的性能也得到了提升,因此对于使用 0.10.x 大版本的用户,建议使用或升级到 Kafka 0.10.2.2 版本。
0.11.x版本
Kafka 0.11 是一个里程碑式的大版本,主要有两个大的变更,一是Kafka从这个版本开始支持 Exactly-Once 语义即精准一次语义,主要是实现了Producer端的消息幂等性,以及事务特性,这对于Kafka流式处理具有非常大的意义。
另一个重大变更是Kafka消息格式的重构,Kafka 0.11主要为了实现Producer幂等性与事务特性,重构了投递消息的数据结构。这一点非常值得关注,因为Kafka 0.11之后的消息格式发生了变化,所以我们要特别注意Kafka不同版本间消息格式不兼容的问题。
1.x版本
Kafka 1.x 更多的是Kafka Streams方面的改进,以及Kafka Connect的改进与功能完善等。但仍有两个重要特性,一是Kafka 1.0.0实现了磁盘的故障转移,当Broker的某一块磁盘损坏时数据会自动转移到其他正常的磁盘上,Broker还会正常工作,这在之前版本中则会直接导致Broker宕机,因此Kafka的可用性与可靠性得到了提升;
二是Kafka 1.1.0开始支持副本跨路径迁移,分区副本可以在同一Broker不同磁盘目录间进行移动,这对于磁盘的负载均衡非常有意义。
2.x版本:
Kafka 2.x 更多的也是Kafka Streams、Connect方面的性能提升与功能完善,以及安全方面的增强等。一个使用特性,Kafka 2.1.0开始支持ZStandard的压缩方式,提升了消息的压缩比,显著减少了磁盘空间与网络io消耗。
- 已取消对 Java 7 的支持,Java 8 现在是所需的最低版本。
- 我们正在为 Kafka Connect 引入一种新的基于增量协作重新平衡的重新平衡协议 。新协议不需要在 Connect 工作人员之间的重新平衡阶段停止所有任务。相反,只有需要在工作人员之间交换的任务才会停止,并在后续的重新平衡中启动。从 2.3.0 开始,默认启用新的 Connect 协议。有关其工作原理以及如何启用急切重新平衡的旧行为的更多详细信息,请查看 增量合作重新平衡设计。
- 我们正在向消费者用户引入静态成员资格。此功能减少了正常应用程序升级或滚动反弹期间不必要的重新平衡。有关如何使用它的更多详细信息,请查看静态成员资格设计。
1.8. Kafka核心机制
一、压缩。
Kafka支持以集合(batch)为单位发送消息,在此基础上,Kafka还支持对消息集合进行压缩。
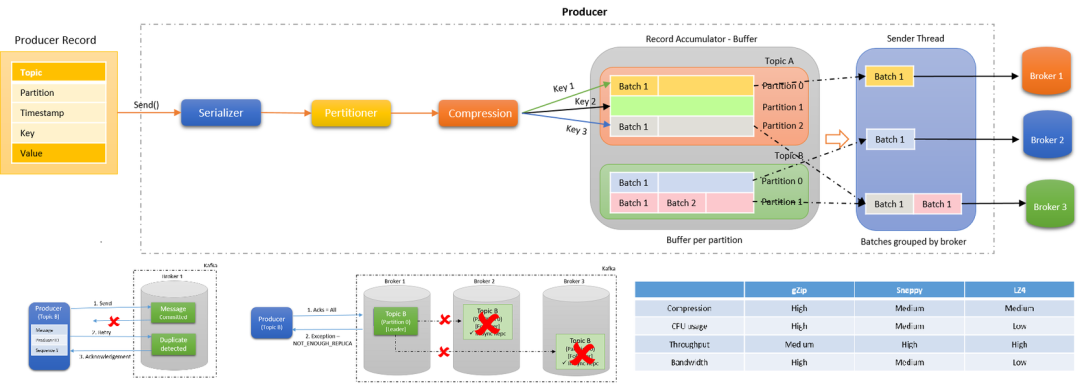
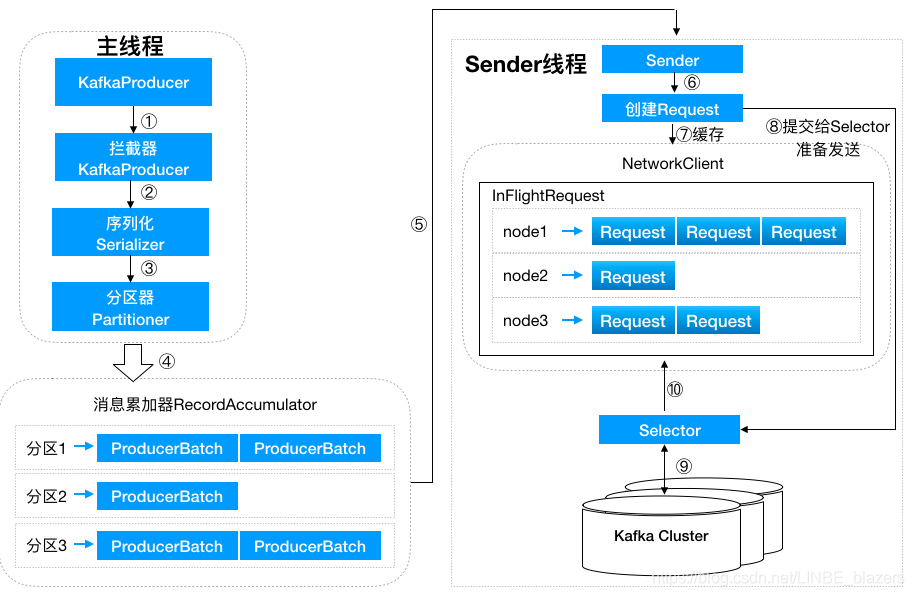
发送消息依次经过以下处理器:
- Serialize:键和值都根据传递的序列化器进行序列化。优秀的序列化方式可以提高网络传输的效率。
- Partition:决定将消息写入主题的哪个分区,默认情况下遵循 murmur2 算法。自定义分区程序也可以传递给生产者,以控制应将消息写入哪个分区。
- Compress:默认情况下,在 Kafka 生产者中不启用压缩.Compression 不仅可以更快地从生产者传输到代理,还可以在复制过程中进行更快的传输。压缩有助于提高吞吐量,降低延迟并提高磁盘利用率。
- Accumulate:
Accumulate顾名思义,就是一个消息累计器。其内部为每个 Partition 维护一个Deque双端队列,队列保存将要发送的批次数据,Accumulate将数据累计到一定数量,或者在一定过期时间内,便将数据以批次的方式发送出去。记录被累积在主题每个分区的缓冲区中。根据生产者批次大小属性将记录分组。主题中的每个分区都有一个单独的累加器 / 缓冲区。 - Group Send:记录累积器中分区的批次按将它们发送到的代理分组。批处理中的记录基于 batch.size 和 linger.ms 属性发送到代理。记录由生产者根据两个条件发送。当达到定义的批次大小或达到定义的延迟时间时。
Kafka 支持多种压缩算法:lz4、snappy、gzip。Kafka 2.1.0 正式支持 ZStandard —— ZStandard 是 Facebook 开源的压缩算法,旨在提供超高的压缩比 (compression ratio),具体细节参见 zstd。
Producer、Broker 和 Consumer 使用相同的压缩算法,在 producer 向 Broker 写入数据,Consumer 向 Broker 读取数据时甚至可以不用解压缩,最终在 Consumer Poll 到消息时才解压,这样节省了大量的网络和磁盘开销。
二、消息可靠性。
从Producer(生产者)端看:Kafka是这么处理的,当一个消息被发送后,Producer会等待broker成功接收到消息的反馈(可通过参数控制等待时间),如果消息在途中丢失或是其中一个broker挂掉,Producer会重新发送(我们知道Kafka有备份机制,可以通过参数控制是否等待所有备份节点都收到消息)。
从Consumer(消费者)端看:当组协调器收到 OffsetCommitRequest 时,它会将请求附加到名为*__consumer_offsets*的特殊压缩Kafka 主题。只有在偏移量主题的所有副本都收到偏移量后,代理才会向消费者发送成功的偏移量提交响应。如果偏移量无法在可配置的超时内复制,则偏移量提交将失败,消费者可以在回退后重试提交。
日志的写入(fsync)允许串行追加,它总是到最后一个文件。当此文件达到可配置的大小(例如 1GB)时,它会转存为新文件。该日志采用两个配置参数:M,它给出了在强制操作系统将文件刷新到磁盘之前要写入的消息数,以及S,它给出了强制刷新后的秒数。这提供了在系统崩溃时最多丢失M 条消息或S秒数据的持久性保证。
三、备份机制。
备份机制是Kafka0.8版本的新特性,备份机制的出现大大提高了Kafka集群的可靠性、稳定性。有了备份机制后,Kafka允许集群中的节点挂掉后而不影响整个集群工作。一个备份数量为n的集群允许n-1个节点失败。在所有备份节点中,有一个节点作为lead节点,这个节点保存了其它备份节点列表,并维持各个备份间的状体同步。
四、 顺序读写磁盘
Kafka高度依赖文件系统来存储和缓存消息,一般的人认为磁盘是缓慢的,这导致人们对持久化结构具有竞争性持怀疑态度。其实,磁盘远比你想象的要快或者慢,这决定于我们如何使用磁盘。 一个和磁盘性能有关的关键事实是:磁盘驱动器的吞吐量跟寻到延迟是相背离的,也就是所,线性写的速度远远大于随机写。比如:在一个6 7200rpm SATA RAID-5 的磁盘阵列上线性写的速度大概是600M/秒,但是随机写的速度只有100K/秒,两者相差将近6000倍。线性读写在大多数应用场景下是可以预测的,因此,操作系统利用read-ahead和write-behind技术来从大的数据块中预取数据,或者将多个逻辑上的写操作组合成一个大写物理写操作中。更多的讨论可以在ACMQueueArtical中找到,他们发现,对磁盘的线性读在有些情况下可以比内存的随机访问要快一些。
基于这些事实,利用文件系统并且依靠页缓存(和下文数据拷贝次数也有关系)比维护一个内存缓存或者其他结构要好——我们至少要使得可用的缓存加倍,通过自动访问可用内存,并且通过存储更紧凑的字节结构而不是一个对象,这将有可能再次加倍。这么做的结果就是在一台32GB的机器上,如果不考虑GC惩罚,将最多有28-30GB的缓存。此外,这些缓存将会一直存在即使服务重启,然而进程内缓存需要在内存中重构(10GB缓存需要花费10分钟)或者它需要一个完全冷缓存启动(非常差的初始化性能)。它同时也简化了代码,因为现在所有的维护缓存和文件系统之间内聚的逻辑都在操作系统内部了,这使得这样做比one-off in-process attempts更加高效与准确。如果你的磁盘应用更加倾向于顺序读取,那么read-ahead在每次磁盘读取中实际上获取到这人缓存中的有用数据。 以上这些建议了一个简单的设计:不同于维护尽可能多的内存缓存并且在需要的时候刷新到文件系统中,我们换一种思路。所有的数据不需要调用刷新程序,而是立刻将它写到一个持久化的日志中。事实上,这仅仅意味着,数据将被传输到内核页缓存中并稍后被刷新。我们可以增加一个配置项以让系统的用户来控制数据在什么时候被刷新到物理硬盘上。
1 | 补充说明(方便理解): |
mmap内存映射介绍,可以参考这篇博客:https://blog.csdn.net/coolwriter/article/details/80493166
五、消息持久性
Kafka可以通过配置时间和大小来持久化所有的消息,不管是否被消费(消费者收掉)。消息被消费后不是立马被删除,我们可以将这些消息保留一段相对比较长的时间(比如一个星期)。
六、 Kafka数据存储结构
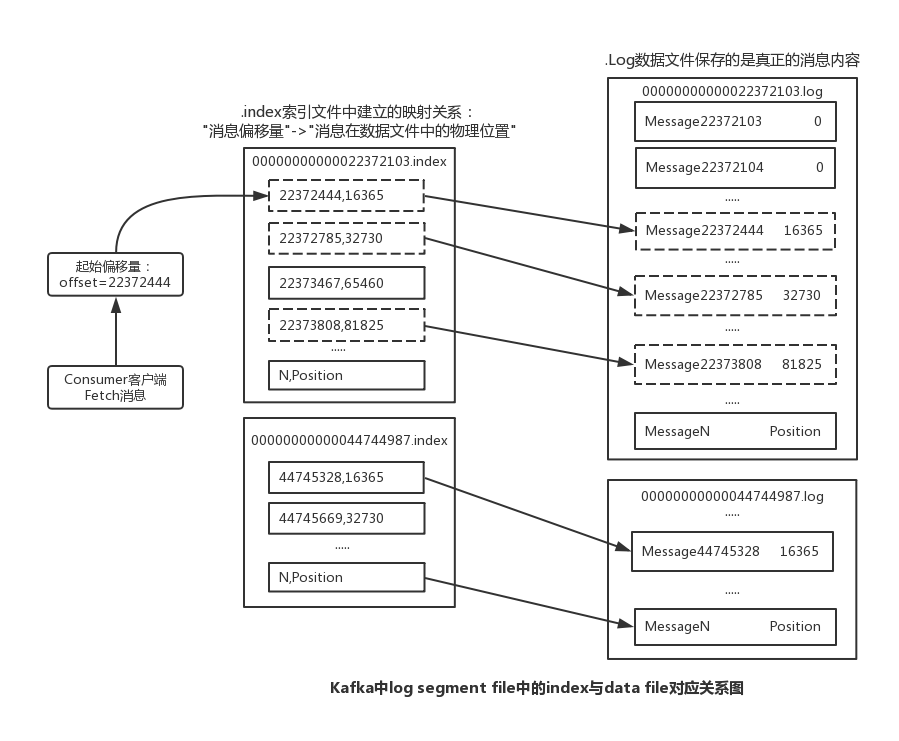
(1)数据文件的分段Kafka解决查询效率的手段之一是将数据文件分段(segment File),比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
(2)为数据文件建索引数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message 了,但是这依然需要顺序扫描才能找到对应offset的Message。
为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中小的offset的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
position,表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个 position就可以读取对应的Message了。index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
补充说明为CSDN博主「芬格尔mkq0.4~」的原创文章 原文链接:https://blog.csdn.net/weixin_28956753/article/details/113017705
1 | 分区目录中的日志数据文件和日志索引文件 |
七、 减少请求次数(消息集合)和减少数据拷贝次数(sendfile)
我们已经为效率做了非常多的努力。但是有一种非常主要的应用场景是:处理Web活动数据,它的特点是数据量非常大,每一次的网页浏览都会产生大量的写操作。更进一步,我们假设每一个被发布的消息都会被至少一个consumer消费,因此我们更要怒路让消费变得更廉价。 通过上面的介绍,我们已经解决了磁盘方面的效率问题,除此之外,在此类系统中还有两类比较低效的场景:
- 太多小的I/O操作
- 过多的字节拷贝
为了减少大量小I/O操作的问题,kafka的协议是围绕消息集合构建的(减少请求次数,提高吞吐量)。Producer一次网络请求可以发送一个消息集合,而不是每一次只发一条消息。在server端是以消息块的形式追加消息到log中的,consumer在查询的时候也是一次查询大量的线性数据块。消息集合即MessageSet,实现本身是一个非常简单的API,它将一个字节数组或者文件进行打包。所以对消息的处理,这里没有分开的序列化和反序列化的上步骤,消息的字段可以按需反序列化(如果没有需要,可以不用反序列化)。 另一个影响效率的问题就是字节拷贝。为了解决字节拷贝的问题,kafka设计了一种“标准字节消息”,Producer、Broker、Consumer共享这一种消息格式。Kakfa的message log在broker端就是一些目录文件,这些日志文件都是MessageSet按照这种“标准字节消息”格式写入到磁盘的。 维持这种通用的格式对这些操作的优化尤为重要:持久化log 块的网络传输。流行的unix操作系统提供了一种非常高效的途径来实现页面缓存和socket之间的数据传递。在Linux操作系统中,这种方式被称作:sendfile system call(Java提供了访问这个系统调用的方法:FileChannel.transferTo api)。
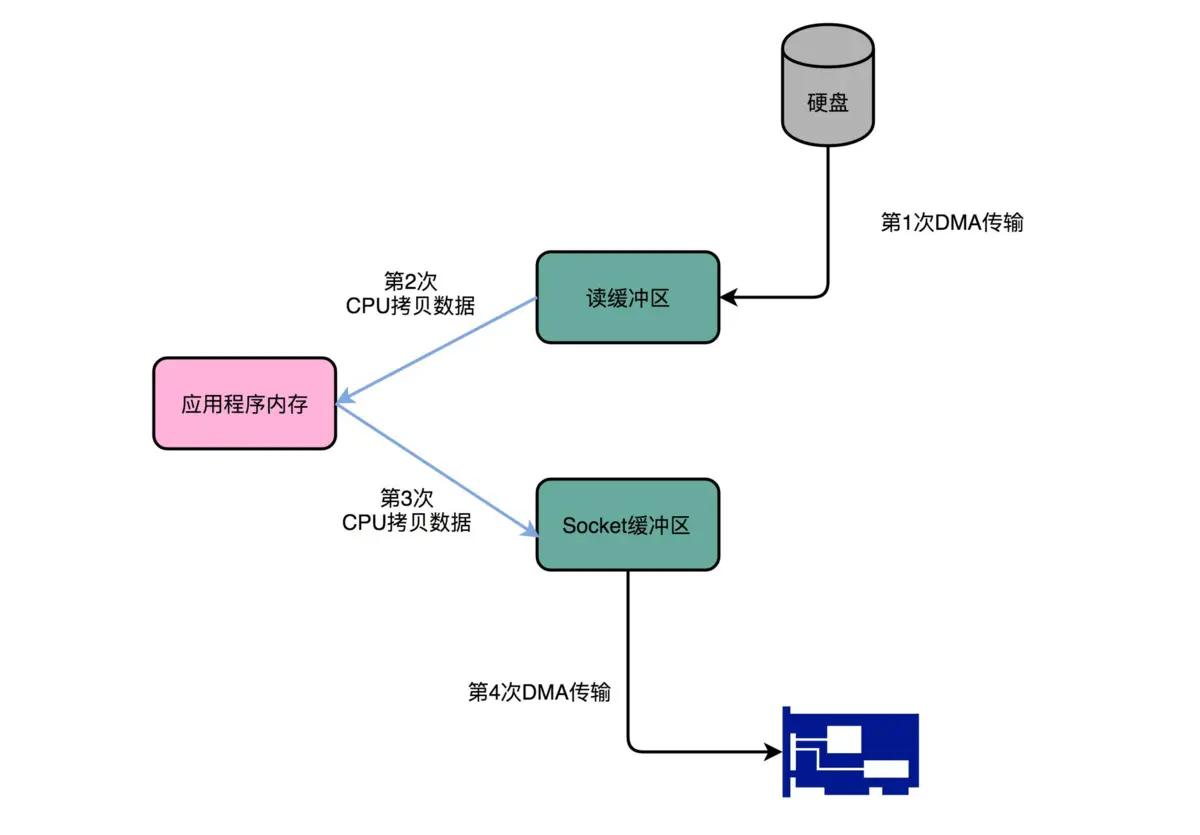
为了理解sendfile的影响,需要理解传统的将数据从文件传到socket的路径:
- 操作系统将数据从磁盘读到内核空间的页缓存中。这个传输是通过DMA搬运的。
- 应用将数据从内核空间读到用户空间的缓存中。这个传输是通过CPU搬运的。
- 应用将数据写回内核空间的socket缓存中。这个传输是通过CPU搬运的。
- 操作系统将数据从socket缓存写到网卡缓存中,以便将数据经网络发出。这个传输又是通过DMA搬运的。
这种操作方式明显是非常低效的,这里有四次拷贝,两次系统调用。如果使用sendfile,就可以避免两次拷贝:操作系统将数据直接从页缓存发送到网络上。所以在这个优化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的。
操作系统的设计就是每个应用程序都有自己的用户内存,用户内存和内核内存隔离,这是为了程序和系统安全考虑,否则的话每个应用程序内存满天飞,随意读写那还得了。
我们期望一个主题上有多个消费者是一种常见的应用场景。利用上述的zero-copy,数据只被拷贝到页缓存一次,然后就可以在每次消费时被重得利用,而不需要将数据存在内存中,然后在每次读的时候拷贝到内核空间中。这使得消息消费速度可以达到网络连接的速度。这样以来,通过页面缓存和sendfile的结合使用,整个kafka集群几乎都已以缓存的方式提供服务,而且即使下游的consumer很多,也不会对整个集群服务造成压力。
sendfile 的实现是通过给MessageSet接口一个writeTo方法来完成的。这允许文件支持的消息集使用更有效的transferTo实现而不是进程内缓冲写入。
1 | 针对官方文档补充说明(sendfile): |
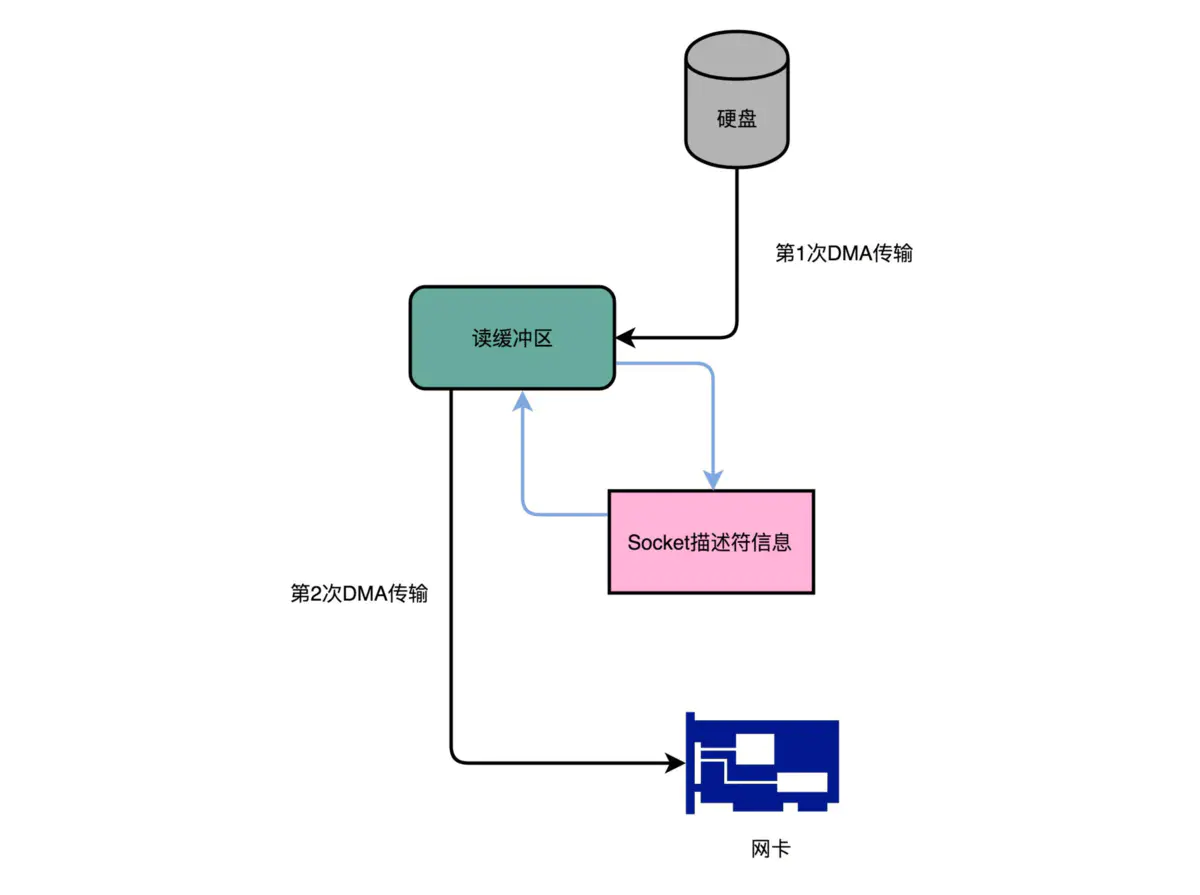
第一次,是通过DMA,从硬盘直接读到操作系统内核的读缓冲区里面。第二次,则是根据Socket的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。
零拷贝
在这个方法里面,我们没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。IBM Developer Works里面有一篇文章,专们写过程序来测试过在同样的硬件下,使用零拷贝能够带来的性能提升。我在这里放上这篇文章链接。在这篇文章最后,你可以看到,无论传输数据量的大小,传输同样的数据,使用了零拷贝能够缩短65%的时间,大幅度提升了机器传输数据的吞吐量。想要深入了解零拷贝,建议你可以仔细读读读这篇文章。
DMA总结
讲到这里,相信你对DMA的原理、作用和效果都有所理解了。那么,我们⼀起来回顾总结一下。、
如果我们始终让CPU来进行各种数据传输工作,会特别浪费。一方面,我们的数据传输工作用不到多少CPU核新的“计算”功能。另一方面,CPU的运转速度也比I/O操作要快很多。
所以,我们希望能够给CPU“减负”。
于是,工程师们就在主板上放上了DMAC这样一个协处理器芯片。通过这个芯片,CPU只需要告诉DMAC,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。
后续的实际数据传输工作,都会有DMAC来完成。随着现代计算机各种外设硬件越来越多,光一个通用的DMAC芯片不够了,我们在各个外设上都加上了DMAC芯片,
使得CPU很少再需要关注数据传输的工作了。
在我们实际的系统开发过程中,利用好DMA的数据传输机制,也可以大幅提升I/O的吞吐率。最典型的例子就是Kafka。
传统地从硬盘读取数据,然后再通过网卡上向外发送,我们需要进行四次数据传输,其中有两次是发生在内存里的缓冲区和对应的硬件设备之间,我们没法节省掉。
但是还有两次,完全是通过CPU在内存里面进行数据复制。
在Kafka里,通过Java的NIO里面FileChannel的transferTo方法调用,我们可以不用把数据复制到我们应用程序的内存里面。通过DMA的方式,
我们可以把数据从内存缓冲区直接写到网卡的缓冲区里面。在使用了这样的零拷贝的方法之后呢,我们传输同样数据的时间,可以缩减为原来的1/3,相当于提升了3倍的吞吐率。
这也是为什么,Kafka是目前实时数据传输管道的标准解决方案
八、PageCache
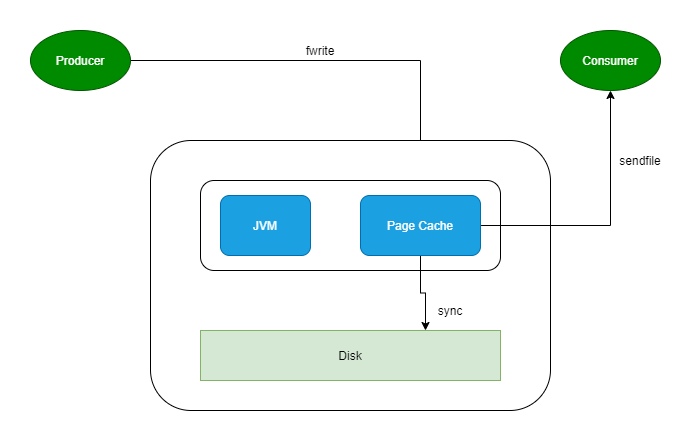
producer 生产消息到 Broker 时,Broker 会使用 pwrite() 系统调用【对应到 Java NIO 的 FileChannel.write() API】按偏移量写入数据,此时数据都会先写入page cache。consumer 消费消息时,Broker 使用 sendfile() 系统调用【对应 FileChannel.transferTo() API】,零拷贝地将数据从 page cache 传输到 broker 的 Socket buffer,再通过网络传输。
leader 与 follower 之间的同步,与上面 consumer 消费数据的过程是同理的。
page cache中的数据会随着内核中 flusher 线程的调度以及对 sync()/fsync() 的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。另外,如果 consumer 要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入 page cache,以方便下一次读取。
因此如果 Kafka producer 的生产速率与 consumer 的消费速率相差不大,那么就能几乎只靠对 broker page cache 的读写完成整个生产 - 消费过程,磁盘访问非常少。
九、网络模型
Kafka 自己实现了网络模型做 RPC。底层基于 Java NIO,采用和 Netty 一样的 Reactor 线程模型。
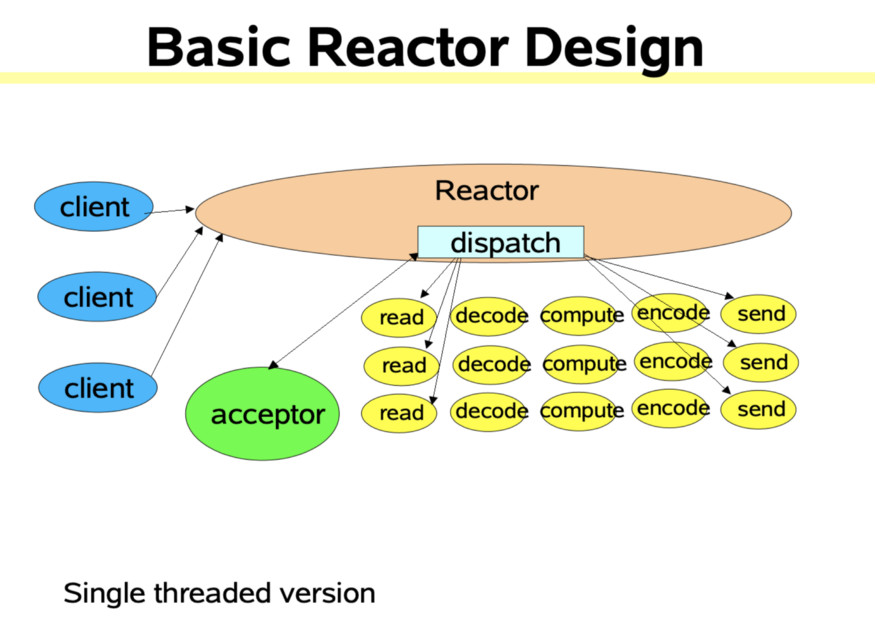
Reacotr 模型主要分为三个角色
- Reactor:把 IO 事件分配给对应的 handler 处理
- Acceptor:处理客户端连接事件
- Handler:处理非阻塞的任务
在传统阻塞 IO 模型中,每个连接都需要独立线程处理,当并发数大时,创建线程数多,占用资源;采用阻塞 IO 模型,连接建立后,若当前线程没有数据可读,线程会阻塞在读操作上,造成资源浪费
针对传统阻塞 IO 模型的两个问题,Reactor 模型基于池化思想,避免为每个连接创建线程,连接完成后将业务处理交给线程池处理;基于 IO 复用模型,多个连接共用同一个阻塞对象,不用等待所有的连接。遍历到有新数据可以处理时,操作系统会通知程序,线程跳出阻塞状态,进行业务逻辑处理
Kafka 即基于 Reactor 模型实现了多路复用和处理线程池。其设计如下:
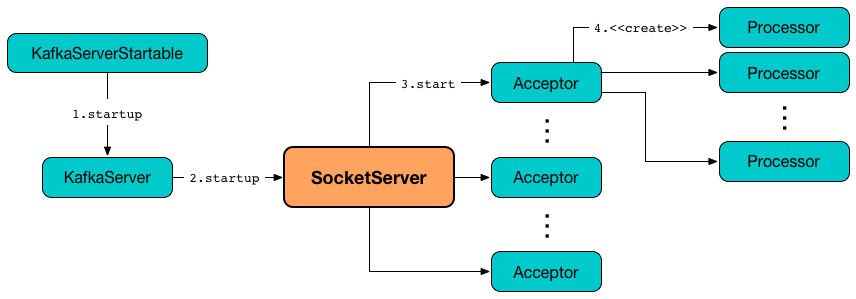
其中包含了一个Acceptor线程,用于处理新的连接,Acceptor 有 N 个 Processor 线程 select 和 read socket 请求,N 个 Handler 线程处理请求并相应,即处理业务逻辑。
I/O 多路复用可以通过把多个 I/O 的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。它的最大优势是系统开销小,并且不需要创建新的进程或者线程,降低了系统的资源开销。
总结: Kafka Broker 的 KafkaServer 设计是一个优秀的网络架构。
补充方便理解:
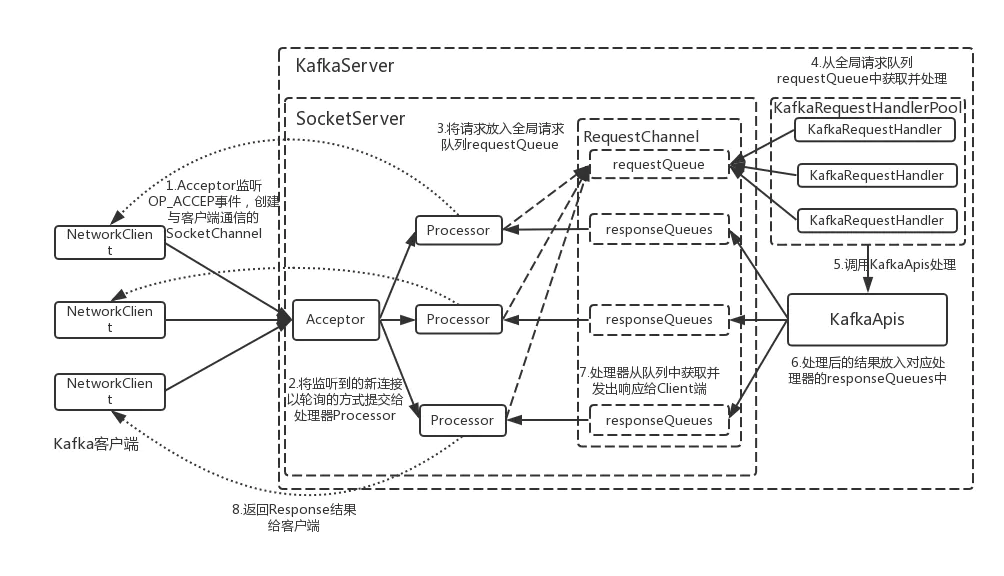
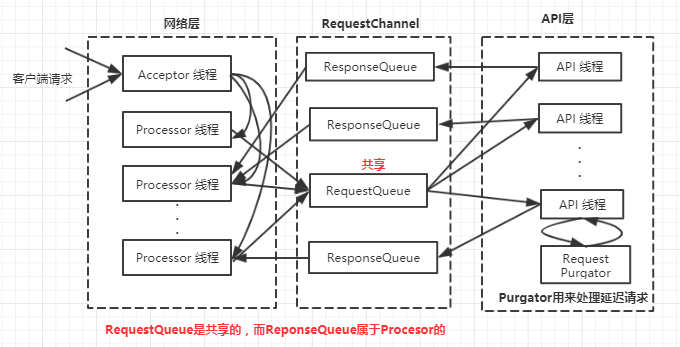
网络层的核心类是SocketServer,包含一个Acceptor用来接收新的连接,Acceptor对应多个Processor线程,每个 Processor线程都有自己的Selector,用来从连接中读取请求并写回响应
同时一个Acceptor线程对应多个Handler线程,这才是真正处理请求的线程,Handler线程处理完请求后把响应返回给 Processor线程,其中Processor线程和Handler线程通过RequestChannel传递数据,ReqeustChannel包括共享的RequestQueue和Processor私有的ResponseQueue。
1 | 1.客户端(NetworkClient)发送请求被接收器(Acceptor)转发给处理器(Processor)处理 |
十、分区并发
Kafka 的 Topic 可以分成多个 Partition,每个 Paritition 类似于一个队列,保证数据有序。同一个 Group 下的不同 Consumer 并发消费 Paritition,分区实际上是调优 Kafka 并行度的最小单元,因此,可以说,每增加一个 Paritition 就增加了一个消费并发。
Kafka 具有优秀的分区分配算法——StickyAssignor,可以保证分区的分配尽量地均衡,且每一次重分配的结果尽量与上一次分配结果保持一致。这样,整个集群的分区尽量地均衡,各个 Broker 和 Consumer 的处理不至于出现太大的倾斜。
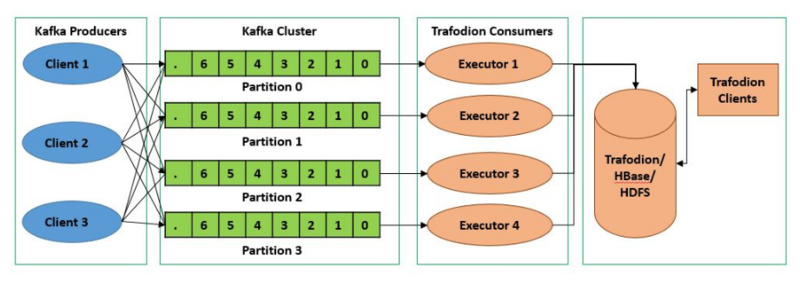
转载至:https://cloud.tencent.com/developer/article/1826512?from=information.detail.kafka%20mmap
作者:码哥
1.9. Kafka优点
一、解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
二、冗余(副本)
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
三、扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
四、灵活性&峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
五、可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
六、顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。
七、缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
八、异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
2. kafka中的生产者
2.1. 生产者基本概念
消息和数据生成者,向Kafka的一个topic发布消息的过程叫做producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;
异步发送批量发送可以很有效的提高发送效率。kafka producer的异步发送模式允许进行批量发送,先将消息缓存到内存中,然后一次请求批量发送出去。
原文链接:https://blog.csdn.net/weixin_38004638/article/details/90231607
作者:陈晨辰~
2.2. 生产者设计
负载均衡。 生产者将消息发布到主题下(topic)哪个分区,这可以随机完成,实现一种随机负载平衡,也可以用户通过客户端指定一个键来进行分区并使用它来散列到一个分区,例如,用户选择的键是分区ID,那么给定分区的所有数据都将发送到同一个分区。消费者如果想消费生产者发布的消息,需要指定的是同一个主题(topic),而不是分区。
生产者将数据直接发送到作为分区领导者的broker,而没有任何干预路由层。为了帮助生产者做到这一点,所有 Kafka 节点都可以在任何给定时间回答有关哪些服务器处于活动状态以及主题分区的领导者在哪里的元数据请求,以允许生产者适当地引导其请求。
异步发送。 批处理是效率的重要驱动因素之一,为了启用批处理,Kafka 生产者将尝试在内存中积累数据并在单个请求中发送更大的批次。批处理可以配置为累积不超过固定数量的消息,等待时间不超过某个固定的延迟限制(例如 64k 或 10 毫秒)。这允许累积更多要发送的字节,并且服务器上很少有较大的 I/O 操作。这种缓冲是可配置的,并提供了一种机制来权衡少量额外的延迟以获得更好的吞吐量。
2.3. 生产者与分区的关系
默认的分区策略:
如果发送消息的时候指定了分区,则消息发送到指定分区;
如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区;
如果既没有指定分区,且消息的key为空,则用轮询的方式选择一个分区。
一个生产者可以指定多个分区写入,一个分区也可以由多个生产者写入:
2.4. 生产者配置
参考官网链接:https://kafka.apache.org/documentation/#producerconfigs
producer.properties:生产端的配置文件
1 | 用于建立与 Kafka 集群的初始连接的主机/端口对列表。 |
消息传递语义
- 最多一次——消息可能会丢失,但永远不会重新传递。(消费者进程有可能在保存其位置之后但在保存其消息处理的输出之前崩溃。)
- 至少一次——消息永远不会丢失,但可能会重新传递。(消费者进程有可能在处理消息之后但在保存其位置之前崩溃。)
- 恰好一次——这是人们真正想要的,每条消息只传递一次。(使用事务。消费者的位置作为消息存储在主题中,因此我们可以在与接收处理数据的输出主题相同的事务中将偏移量写入 Kafka。如果交易被中止,消费者的位置将恢复到其旧值,并且其他消费者将看不到输出主题上产生的数据,这取决于他们的“隔离级别”。在默认的“read_uncommitted”隔离级别中,所有消息对消费者都是可见的,即使它们是中止事务的一部分,但在“read_committed”中,消费者只会返回来自已提交事务的消息(以及任何不属于该事务的消息)交易))
值得注意的是,这分为两个问题:发布消息的持久性保证和消费消息时的保证。
许多系统声称提供“恰好一次”交付语义,但阅读细则很重要,这些声明中的大多数是误导性的(即它们没有转化为消费者或生产者可能失败的情况,存在多个消费者进程,或写入磁盘的数据可能丢失的情况)。
Kafka 的语义是直截了当的。当发布消息时,我们有一个消息被“提交”到日志的概念。提交发布的消息后,只要复制该消息所写入分区的一个代理保持“活动”,它就不会丢失。已提交消息的定义、活动分区以及我们尝试处理的故障类型的描述将在下一节中更详细地描述。现在让我们假设一个完美的无损代理,并尝试了解对生产者和消费者的保证。如果生产者尝试发布消息并遇到网络错误,则无法确定此错误是发生在消息提交之前还是之后。
在 0.11.0.0 之前,如果生产者未能收到表明消息已提交的响应,则它别无选择,只能重新发送消息。这提供了至少一次传递语义,因为如果原始请求实际上已经成功,则消息可能会在重新发送期间再次写入日志。从 0.11.0.0 开始,Kafka 生产者还支持幂等传递选项,以保证重新发送不会导致日志中出现重复条目。为了实现这一点,代理为每个生产者分配一个 ID 并使用生产者随每条消息发送的序列号对消息进行重复数据删除。同样从 0.11.0.0 开始,生产者支持使用类事务语义将消息发送到多个主题分区的能力:要么所有消息都成功写入,要么都没有写入。主要用例是 Kafka 主题之间的恰好一次处理(如下所述)。
并非所有用例都需要如此强大的保证。对于延迟敏感的用途,我们允许生产者指定其所需的持久性级别。如果生产者指定它要等待正在提交的消息,则这可能需要 10 毫秒的时间。然而,生产者也可以指定它想要完全异步地执行发送,或者它只想等到领导者(但不一定是追随者)收到消息。
现在让我们从消费者的角度来描述语义。所有副本都具有完全相同的日志和相同的偏移量。消费者控制其在此日志中的位置。如果消费者从未崩溃,它可以只将这个位置存储在内存中,但是如果消费者失败并且我们希望这个主题分区被另一个进程接管,新进程将需要选择一个合适的位置开始处理。假设消费者读取一些消息——它有几个选项来处理消息和更新其位置。
- 它可以读取消息,然后将其位置保存在日志中,最后处理消息。在这种情况下,消费者进程有可能在保存其位置之后但在保存其消息处理的输出之前崩溃。在这种情况下,接管处理的进程将从保存的位置开始,即使该位置之前的一些消息尚未处理。这对应于“最多一次”语义,因为在消费者失败消息的情况下可能不会被处理。
- 它可以读取消息,处理消息,并最终保存其位置。在这种情况下,消费者进程有可能在处理消息之后但在保存其位置之前崩溃。在这种情况下,当新进程接管它收到的前几条消息时,它已经被处理了。在消费者失败的情况下,这对应于“至少一次”语义。在许多情况下,消息有一个主键,因此更新是幂等的(两次接收相同的消息只会用它自己的另一个副本覆盖一条记录)。
那么恰好一次语义(即你真正想要的东西)呢?从 Kafka 主题消费并生成另一个主题时(如在Kafka Streams 中) 应用程序),我们可以利用上面提到的 0.11.0.0 中新的事务性生产者功能。消费者的位置作为消息存储在主题中,因此我们可以在与接收处理数据的输出主题相同的事务中将偏移量写入 Kafka。如果交易被中止,消费者的位置将恢复到其旧值,并且其他消费者将看不到输出主题上产生的数据,这取决于他们的“隔离级别”。在默认的“read_uncommitted”隔离级别中,所有消息对消费者都是可见的,即使它们是中止事务的一部分,但在“read_committed”中,消费者只会返回来自已提交事务的消息(以及任何不属于该事务的消息)交易)。
写入外部系统时,限制在于需要协调消费者的位置与实际存储为输出的内容。实现这一点的经典方法是在消费者位置的存储和消费者输出的存储之间引入两阶段提交。但这可以通过让消费者将其偏移量存储在与其输出相同的位置来更简单、更一般地处理。这更好,因为消费者可能想要写入的许多输出系统不支持两阶段提交。作为一个例子,考虑一个 Kafka Connect连接器在 HDFS 中填充数据以及它读取的数据的偏移量,以便保证数据和偏移量都被更新或都不更新。对于需要这些更强语义并且消息没有允许重复数据删除的主键的许多其他数据系统,我们遵循类似的模式。
因此 Kafka 有效地支持Kafka Streams 中的一次性交付,并且事务性生产者/消费者通常可用于在 Kafka 主题之间传输和处理数据时提供一次性交付。其他目标系统的 Exactly-once 交付通常需要与此类系统合作,但 Kafka 提供了使实现这一点可行的偏移量(另请参阅Kafka Connect)。否则,Kafka 默认保证至少一次交付,并允许用户通过在处理一批消息之前禁用对生产者的重试和在消费者中提交偏移量来实现至少一次交付。
2.4.1. 生产者事务的补充
一、事务场景
最简单的需求是producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见 。
producer可能会给多个topic,多个partition发消息,这些消息也需要能放在一个事务里面,这就形成了一个 典型的分布式事务。
kafka的应用场景经常是应用先消费一个topic,然后做处理再发到另一个topic,这个consume-transform-produce过程需要放到一个事务里面,比如在消息处理或者发送的过程中如果失败了,消费位点也不能提交。
producer或者producer所在的应用可能会挂掉,新的producer启动以后需要知道怎么处理之前未完成的事务 。
流式处理的拓扑可能会比较深,如果下游只有等上游消息事务提交以后才能读到,可能会导致rt非常长吞吐量也随之下降很多,所以需要实现read committed和read uncommitted两种事务隔离级别。
二、事务推导
因为producer发送消息可能是分布式事务,所以引入了常用的2PC,所以有事务协调者(Transaction Coordinator)。Transaction Coordinator和之前为了解决脑裂和惊群问题引入的Group Coordinator在选举和failover上面类似。
事务管理中事务日志是必不可少的,kafka使用一个内部topic来保存事务日志,这个设计和之前使用内部topic保存位点的设计保持一致。事务日志是Transaction Coordinator管理的状态的持久化,因为不需要回溯事务的历史状态,所以事务日志只用保存最近的事务状态。
因为事务存在commit和abort两种操作,而客户端又有read committed和read uncommitted两种隔离级别,所以消息队列必须能标识事务状态,这个被称作Control Message。
producer挂掉重启或者漂移到其它机器需要能关联的之前的未完成事务所以需要有一个唯一标识符来进行关联,这个就是TransactionalId,一个producer挂了,另一个有相同TransactionalId的producer能够接着处理这个事务未完成的状态。注意不要把TransactionalId和数据库事务中常见的transaction id搞混了,kafka目前没有引入全局序,所以也没有transaction id,这个TransactionalId是用户提前配置的。
TransactionalId能关联producer,也需要避免两个使用相同TransactionalId的producer同时存在,所以引入了producer epoch来保证对应一个TransactionalId只有一个活跃的producer epoch
1 | 惊群问题是指在多线程(或多进程)场景下,有多个线程在等待某一资源可用,一旦这个资源可用, |
三、事务作用
事务能够保证Kafka topic下每个分区的原子写入。例如:原子“读取-处理-写入”(consume-transform-produce)周期中,某个应用程序在某个topic tp0的偏移量X处读取到了消息A,并且在对消息A进行了一些处理(如B = F(A))之后将消息B写入topic tp1,则只有当消息A和B被认为被成功地消费并一起发布,或者完全不发布时,整个读取过程写入操作是原子的。
避免僵尸实例。我们通过为每个事务Producer分配一个称为transactional.id的唯一标识符来解决僵尸实例的问题。在进程重新启动时能够识别相同的Producer实例。
API要求事务性Producer的第一个操作应该是在Kafka集群中显示注册transactional.id。 当注册的时候,Kafka broker用给定的transactional.id检查打开的事务并且完成处理。 Kafka也增加了一个与transactional.id相关的epoch。Epoch存储每个transactional.id内部元数据。
一旦这个epoch被触发,任何具有相同的transactional.id和更旧的epoch的Producer被视为僵尸,并被围起来, Kafka会拒绝来自这些Procedure的后续事务性写入。
事务补充转载至:
https://www.cnblogs.com/wangzhuxing/p/10125437.html
作者:小人物的奋斗的博客
kafka事务
kafka所提供的事务依赖于上面所说的Exactly Once特性,因为如果消息可以重复,那么也就违背了要么都成功,要么都不成功的语义。
Kafka所提供的事务如下:
- 保证多次提交到不同主题和不同分区的消息的原子性,即要么全部发送成功,要么全部发送失败
- 保证
conumser-transform-produce应用模式中,消息能被原子性转换。
需要注意的是Kafka的Exactly Once和事务都是对于Producer而言,因为对于消费者来说:
对于 compacted topic,在一个事务中写入的数据可能会被新的值覆盖;
一个事务内的数据,可能会跨多个
log segment,如果旧的segmeng数据由于过期而被清除,那么这个事务的一部分数据就无法被消费到了;Consumer在消费时可以通过 seek 机制,随机从一个位置开始消费,这也会导致一个事务内的部分数据无法消费;Consumer可能没有订阅这个事务涉及的全部 Partition
还有就是,对于消费者而言不管是先消费,再提交还是先提交,再消费,都不能保证消息正好消费一次,因此Kafka目前的事务都针对于Producer发送消息。
对于Kafka的事务而言,由于可能跨Topic,跨Partition,因此相当于多个机器进行事务处理。需要解决的问题如下:
- 在不引入其他中间件的情况下,引入什么协议?
2PC?3PC - 不管
2PC还是3PC,都需要先将消息暂存,然后由协调者发起commit,在这期间,对于没有commit的信息应该保存在哪里?消费者是否可读? - 协调者角色怎么确定?怎么保证高可用?
- 生产者在事务发送到一半宕机后,应该如何处理?宕机恢复后,又怎么处理上一次未完成的情况?
带着上面的问题,依次来看:
在Kafka中,选用的是类似2PC的协议,不过这里的协调者更多的是处理事务状态的流转。关于协调者的高可用其实在前面的文章就有出现过,之前Kafka移除了Consumer Offset对Zookeeper的依赖,使用的就是通过_consumer_offset_ topic来持久化,通过多副本+ISR来保证高可用和数据不丢失,因此这里依然可以使用这么方式。Kafka对于事务选用的topic为:__transaction_state__,和_consumer_offset_一样,默认3个副本,50个分区。
协调者名为TransactionCoordinator。
初始化:
Producer会首先向任意一个broker发送查找自己对应事务协调器的请求,获取请求后,Producer会向事务协调器请求PID,同时在这个过程中,如果发现对应TransactionId有之前未完成的任务,它还会做以下两件事:
- 恢复
Producer对应TransactionId之前未完成的事务(Commit/Abort) - 对
PID对应epoch进行递增,防止脑裂问题。
可以看到,
Kafka事务为了实现Producer的主从功能,提出了TransactionId的概念,同一个TransactionId只能有一个在运行,后面启动的Producer会使得前面的Producer立即抛出异常。
开始事务:
本地记录事务状态为开始,但是协调器只有在接受到事务第一条消息后,才会标记为事务真正的开始。
进行事务:
在kafka事务中,会原子的支持Consumer-Process-Producer过程,因此在这个过程中还提供了一个API
producer.sendOffsetsToTransaction();,这个过程会将消费的offset暂存在协调器中,等事务提交时统一提交。
提交/回滚:
当提交或回滚的时候,协调器会进行一个两段提交
- 第一阶段,将事务日志,将此事务设置为
PREPARE_COMMIT或PREPARE_ABORT - 第二阶段,发送
Transaction Marker给事务涉及到的Leader发送标记信息,标记此条信息为已提交或已放弃
当完成第二阶段后,协调器最终会将此事务标记为COMPLETE_COMMIT或COMPLETE_ABORT
故障恢复
明白了事务流程之后,简单说一下Kafka对事务的保障:
- 首先,是一个
2PC的提交过程,为什么不用3PC? 因为Kafka的业务仅仅是追加消息,不会涉及到修改数据,因此一般出现问题的情况比较小。 - 对于
2PC协调器,由__transaction_state__topic的某个Leader担任,由Kafka本身确保高可用 - 协调器负责传递和持久化事务状态,通过持久化状态,可以使得协调器即使崩溃,也能选举新的
Leader继续补全事务 - 在提交阶段,为了防止其他
Leader崩溃而没有收到commit消息,协调器会先保存事务状态,再发送Transaction Marker消息 Kafka为了不修改消息状态,会额外持久化Transaction Marker,当消费事务消息的时候,会组合消息和标记共同判断这个消息是否能够被消费。
接下来分下下故障恢复,通过以上状态,如何保证及时出现故障Kafka也能使用:
Producer 在发送beginTransaction()时,如果出现timeout或者错误:Producer只需要重试即可;Producer在发送数据时出现错误:Producer应该abort这个事务,如果Produce没有abort(比如设置了重试无限次,并且batch超时设置得非常大),TransactionCoordinator将会在这个事务超时之后 abort 这个事务操作;Producer发送commitTransaction()时出现 timeout 或者错误:Producer 应该重试这个请求;CoordinatorFailure:如果TransactionCoordinator 发生切换(事务 topic leader 切换),Coordinator可以从日志中恢复。如果发送事务有处于PREPARE_COMMIT或 PREPARE_ABORT 状态,那么直接执行commit或者 abort 操作,如果是一个正在进行的事务,Coordinator的失败并不需要 abort 事务,producer只需要向新的Coordinator发送请求即可。
查找Transaction Coordinator 并获取 Producer ID (pid)
- Transaction Coordinator的处理逻辑
Coordinator的请求时调用 handleFindCoordinatorRequest,其实现与响应查找Group Coordinator请求一样,其实现也是一直到,主要逻辑是根据transactionId的哈希值和topic的partitionCount去余找出对应的partition Id,并返回topic信息
Utils.abs(transactionalId.hashCode) % transactionTopicPartitionCount
- Transaction Coordinator 通过handleInitProducerIdRequest(request方法生成PID
该方法首先会根据transactionId查找之前是否有相关事务,并根据之前的事务状态进行不同的处理逻辑,如果出事状态为空,会为该请求生成相应的PID,并将该信息写入_transaction_state,并返回InitProducerIdResult
kafka生产者事务详细介绍参考:http://dengchengchao.com/?p=1386
四、针对kafka使用的2PC进行补充说明
两阶段提交又称2PC,2PC是一个非常经典的强一致、中心化的原子提交协议。
这里所说的中心化是指协议中有两类节点:一个是中心化协调者节点(coordinator)和N个参与者节点(partcipant)。
两个阶段:第一阶段:投票阶段 和第二阶段:提交/执行阶段。
举例 订单服务A,需要调用 支付服务B 去支付,支付成功则处理购物订单为待发货状态,否则就需要将购物订单处理为失败状态。
那么看2PC阶段是如何处理的
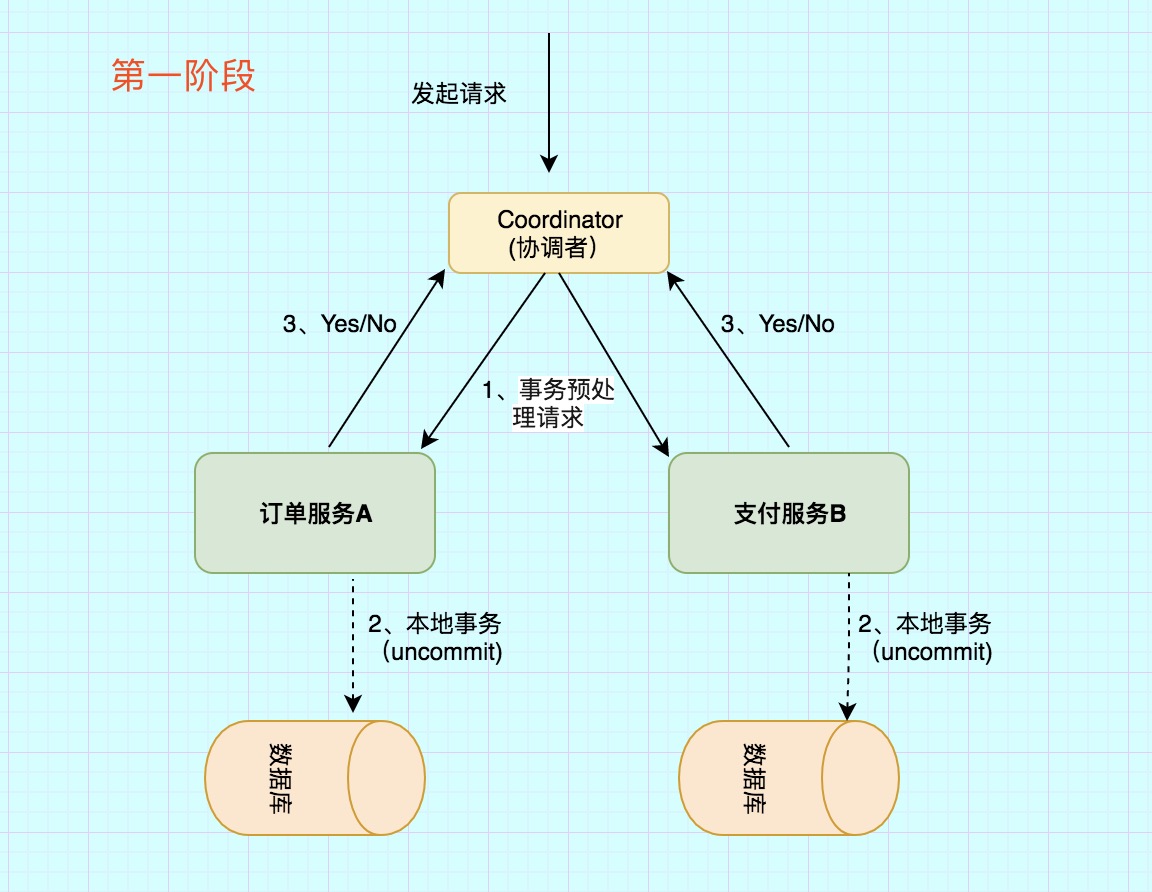
第一阶段主要分为3步
1)事务询问
协调者 向所有的 参与者 发送事务预处理请求,称之为Prepare,并开始等待各 参与者 的响应。
2)执行本地事务
各个 参与者 节点执行本地事务操作,但在执行完成后并不会真正提交数据库本地事务,而是先向 协调者 报告说:“我这边可以处理了/我这边不能处理”。.
3)各参与者向协调者反馈事务询问的响应
如果 参与者 成功执行了事务操作,那么就反馈给协调者 Yes 响应,表示事务可以执行,如果没有 参与者 成功执行事务,那么就反馈给协调者 No 响应,表示事务不可以执行。
第一阶段执行完后,会有两种可能。1、所有都返回Yes. 2、有一个或者多个返回No。
2、第二阶段:提交/执行阶段(成功流程)
成功条件:所有参与者都返回Yes。
第二阶段主要分为两步
1)所有的参与者反馈给协调者的信息都是Yes,那么就会执行事务提交
协调者 向 所有参与者 节点发出Commit请求.
2)事务提交
参与者 收到Commit请求之后,就会正式执行本地事务Commit操作,并在完成提交之后释放整个事务执行期间占用的事务资源。
3、第二阶段:提交/执行阶段(异常流程)
异常条件:任何一个 参与者 向 协调者 反馈了 No 响应,或者等待超时之后,协调者尚未收到所有参与者的反馈响应。
异常流程第二阶段也分为两步
1)发送回滚请求
协调者 向所有参与者节点发出 RoollBack 请求.
2)事务回滚
参与者 接收到RoollBack请求后,会回滚本地事务。
五、2PC缺点
通过上面的演示,很容易想到2pc所带来的缺陷
1)性能问题
无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务 协调者 才会通知进行全局提交,
参与者 进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。
2)单节点故障
由于协调者的重要性,一旦 协调者 发生故障。参与者 会一直阻塞下去。尤其在第二阶段,协调者 发生故障,那么所有的 参与者 还都处于
锁定事务资源的状态中,而无法继续完成事务操作。(虽然协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
2PC出现单点问题的三种情况
(1)协调者正常,参与者宕机
由于 协调者 无法收集到所有 参与者 的反馈,会陷入阻塞情况。
解决方案:引入超时机制,如果协调者在超过指定的时间还没有收到参与者的反馈,事务就失败,向所有节点发送终止事务请求。
(2)协调者宕机,参与者正常
无论处于哪个阶段,由于协调者宕机,无法发送提交请求,所有处于执行了操作但是未提交状态的参与者都会陷入阻塞情况.
解决方案:引入协调者备份,同时协调者需记录操作日志.当检测到协调者宕机一段时间后,协调者备份取代协调者,并读取操作日志,向所有参与者询问状态。
(3)协调者和参与者都宕机
- 发生在第一阶段: 因为第一阶段,所有参与者都没有真正执行commit,所以只需重新在剩余的参与者中重新选出一个协调者,新的协调者在重新执行第一阶段和第二阶段就可以了。
2)发生在第二阶段 并且 挂了的参与者在挂掉之前没有收到协调者的指令。也就是上面的第4步挂了,这是可能协调者还没有发送第4步就挂了。这种情形下,新的协调者重新执行第一阶段和第二阶段操作。
3)发生在第二阶段 并且 有部分参与者已经执行完commit操作。就好比这里订单服务A和支付服务B都收到协调者 发送的commit信息,开始真正执行本地事务commit,但突发情况,Acommit成功,B确挂了。这个时候目前来讲数据是不一致的。虽然这个时候可以再通过手段让他和协调者通信,再想办法把数据搞成一致的,但是,这段时间内他的数据状态已经是不一致的了! 2PC 无法解决这个问题。
三阶段提交协议(3PC)主要是为了解决两阶段提交协议的阻塞问题,2pc存在的问题是当协作者崩溃时,参与者不能做出最后的选择。因此参与者可能在协作者恢复之前保持阻塞。三阶段提交(Three-phase commit),是二阶段提交(2PC)的改进版本。
与两阶段提交不同的是,三阶段提交有两个改动点。
1 | 1、 引入超时机制。同时在协调者和参与者中都引入超时机制。 |
也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
1、CanCommit阶段
之前2PC的一阶段是本地事务执行结束后,最后不Commit,等其它服务都执行结束并返回Yes,由协调者发生commit才真正执行commit。而这里的CanCommit指的是 尝试获取数据库锁 如果可以,就返回Yes。
这阶段主要分为2步
事务询问 协调者 向 参与者 发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待 参与者 的响应。
响应反馈 参与者 接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
2、PreCommit阶段
在阶段一中,如果所有的参与者都返回Yes的话,那么就会进入PreCommit阶段进行事务预提交。这里的PreCommit阶段 跟上面的第一阶段是差不多的,只不过这里 协调者和参与者都引入了超时机制 (2PC中只有协调者可以超时,参与者没有超时机制)。
3、DoCommit阶段
在阶段二中如果所有的参与者节点都可以进行PreCommit提交,那么协调者就会从“预提交状态”-》“提交状态”。然后向所有的参与者节点发送**”doCommit”请求,参与者节点在收到提交请求后就会各自执行事务提交操作,并向协调者节点反馈“Ack”**消息,协调者收到所有参与者的Ack消息后完成事务。
相反,如果有一个参与者节点未完成PreCommit的反馈或者反馈超时,那么协调者都会向所有的参与者节点发送abort请求,从而中断事务。
1 | 相比较2PC而言,3PC对于协调者(Coordinator)和参与者(Partcipant)都设置了超时时间,而2PC只有协调者才拥有超时机制。这解决了一个什么问题呢?这个优化点,主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。 |
转载至:https://www.sohu.com/a/290897501_684445
作者:梦见
除了2PC、3PC还有TCC,感兴趣的可以自己研究一下
3. kafka中的消费者
3.1. 消费者基本概念
- 消息和数据消费者,订阅topic并处理其发布的消息的过程叫做consumers.
- 在kafka中,我们可以认为一个group是一个“订阅者”,一个topic中的每个partions只会被一个“订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息。注: Kafka的设计原理决定,对于一个topic,同一个group不能多于partition个数的consumer同时消费,否则将意味着某些consumer无法得到消息
原文链接:https://blog.csdn.net/weixin_38004638/article/details/90231607
作者:陈晨辰~
3.2. 消费者设计
一、 我们最初考虑的一个问题是消费者应该从broker那里提取数据还是broker应该将数据推送给消费者。在这方面,Kafka 遵循更传统的设计,被大多数消息传递系统共享,其中数据从生产者推送到broker,并由消费者从broker拉取。
基于推送的系统难以处理不同的消费者,因为broker控制数据传输的速率。当消费率低于生产率时,消费者往往会不知所措(本质上是拒绝服务攻击)。基于拉动的系统具有更好的特性,即消费者只是落后并在可能时赶上。基于拉式系统的另一个优点是它有助于对发送给消费者的数据进行积极的批处理。
天真的基于拉取的系统的不足之处在于,如果broker没有数据,消费者最终可能会在一个紧密的循环中轮询,实际上是忙于等待数据到达。为了避免这种情况,我们在拉取请求中设置了参数,允许消费者请求在“长轮询”中阻塞,等待数据到达(并且可以选择等待给定数量的字节可用以确保传输大小)。
二、 大多数消息传递系统保留有关broker上已使用的消息的元数据。
如果broker在每次通过网络分发消息时立即将其记录为已消费,那么如果消费者未能处理该消息(例如因为它崩溃或请求超时或其他原因),该消息将丢失。为了解决这个问题,许多消息系统添加了一个确认功能,这意味着消息只被标记为已发送而不是被消费时;broker等待来自消费者的特定确认以将消息记录为已消费,这种策略解决了丢失消息的问题,但会产生新的问题。首先,如果消费者处理消息但在发送确认之前失败,则消息将被消费两次。第二个问题是关于性能的,现在broker必须保持每条消息的多个状态(首先将其锁定,以免第二次发出,然后将其标记为永久消耗,以便可以将其删除)。必须处理棘手的问题,例如如何处理已发送但从未确认的消息。
Kafka 对此有不同的处理方式。我们的主题分为一组完全有序的分区,每个分区在任何给定时间由每个订阅消费者组中的一个消费者消费。这意味着消费者在每个分区中的位置只是一个整数,即要消费的下一条消息的偏移量。这使得关于已消费内容的状态非常小,每个分区只有一个数字。可以定期检查此状态。这使得等效的消息确认非常便宜。
这个决定有一个附带好处。消费者可以故意倒回到旧的偏移量并重新消费数据。这违反了队列的共同契约,但结果证明是许多消费者的基本特征。例如,如果消费者代码有一个 bug,并且在消费了一些消息后被发现,那么一旦 bug 被修复,消费者就可以重新消费这些消息。
三、离线数据加载
可扩展的持久性允许消费者仅定期消费,例如批量数据加载,定期将数据批量加载到离线系统(如 Hadoop 或关系数据仓库)中。
在 Hadoop 的情况下,我们通过将负载拆分为单个映射任务来并行化数据加载,每个节点/主题/分区组合一个,允许加载完全并行。Hadoop 提供了任务管理,失败的任务可以重新启动,而没有重复数据的危险——它们只需从原始位置重新启动。
四、静态成员资格
静态成员资格旨在提高基于组重新平衡协议构建的流应用程序、消费者组和其他应用程序的可用性。重新平衡协议依赖组协调器将实体 ID 分配给组成员。这些生成的 ID 是短暂的,会在成员重新启动和重新加入时发生变化。对于基于消费者的应用程序,在代码部署、配置更新和定期重启等管理操作期间,这种“动态成员资格”会导致很大一部分任务重新分配给不同的实例。对于大型状态的应用程序,shuffled 的任务需要很长时间才能在处理之前恢复其本地状态,并导致应用程序部分或全部不可用。受此观察启发,Kafka 的组管理协议允许组成员提供持久的实体 ID。组成员身份基于这些 id 保持不变,因此不会触发重新平衡。
如果要使用静态成员资格,
- 将broker集群和客户端应用程序升级到 2.3 或更高版本,并确保升级后的broker也使用
inter.broker.protocol.version2.3 或更高版本。 ConsumerConfig#GROUP_INSTANCE_ID_CONFIG为一个组下的每个使用者实例将配置设置为唯一值。- 对于 Kafka Streams 应用程序,为
ConsumerConfig#GROUP_INSTANCE_ID_CONFIG每个 KafkaStreams 实例设置一个唯一的就足够了,与实例使用的线程数无关。
如果您的broker使用的版本低于 2.3,但您选择ConsumerConfig#GROUP_INSTANCE_ID_CONFIG在客户端进行设置,则应用程序将检测broker版本,然后抛出 UnsupportedException。如果您不小心为不同的实例配置了重复的 ID,broker端的防护机制将通过触发org.apache.kafka.common.errors.FencedInstanceIdException. 有关更多详细信息,请参阅 KIP-345
3.3. 消费者与分区的关系
同一时刻,一条消息只能被组中的一个消费者实例消费。
消费者组订阅这个主题,意味着主题下的所有分区都会被组中的消费者消费到,如果按照从属关系来说的话就是,主题下的每个分区只从属于组中的一个消费者,不可能出现组中的两个消费者负责同一个分区。
那么,问题来了。如果分区数大于或者等于组中的消费者实例数,那自然没有什么问题,无非一个消费者会负责多个分区,(当然,最理想的情况是二者数量相等,这样就相当于一个消费者负责一个分区);但是,如果消费者实例的数量大于分区数,那么按照默认的策略(之所以强调默认策略是因为你也可以自定义策略),有一些消费者是多余的,一直接不到消息而处于空闲状态。
话又说回来,假设多个消费者负责同一个分区,那么会有什么问题呢?
我们知道,Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序,那么要做到这一点就首先要保证消息是由消费者主动拉取的(pull),其次还要保证一个分区只能由一个消费者负责。倘若,两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的offset,就有可能C1才读到2,而C1读到1,C1还没处理完,C2已经读到3了,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序,这就跟主动推送(push)无异。
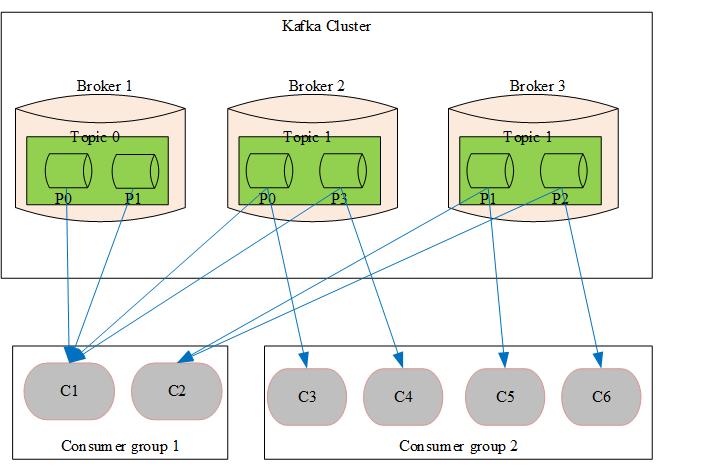
3.4. Kafka消费者与分区的三种分配策略:roundrobin, range, StickyAssignor
说策略之前,先说一下消费者重平衡。
重平衡其实就是一个协议,它规定了如何让消费者组下的所有消费者来分配topic中的每一个分区。比如一个topic有100个分区,一个消费者组内有20个消费者,在协调者的控制下让组内每一个消费者分配到5个分区,这个分配的过程就是重平衡。
重平衡的触发条件主要有三个:
- 消费者组内成员发生变更,这个变更包括了增加和减少消费者。注意这里的减少有很大的可能是被动的,就是某个消费者崩溃退出了
- 主题的分区数发生变更,kafka目前只支持增加分区,当增加的时候就会触发重平衡
- 订阅的主题发生变化,当消费者组使用正则表达式订阅主题,而恰好又新建了对应的主题,就会触发重平衡
为什么说重平衡为人诟病呢?因为重平衡过程中,消费者无法从kafka消费消息,这对kafka的TPS影响极大,而如果kafka集内节点较多,比如数百个,那重平衡可能会耗时极多。数分钟到数小时都有可能,而这段时间kafka基本处于不可用状态。所以在实际环境中,应该尽量避免重平衡发生。
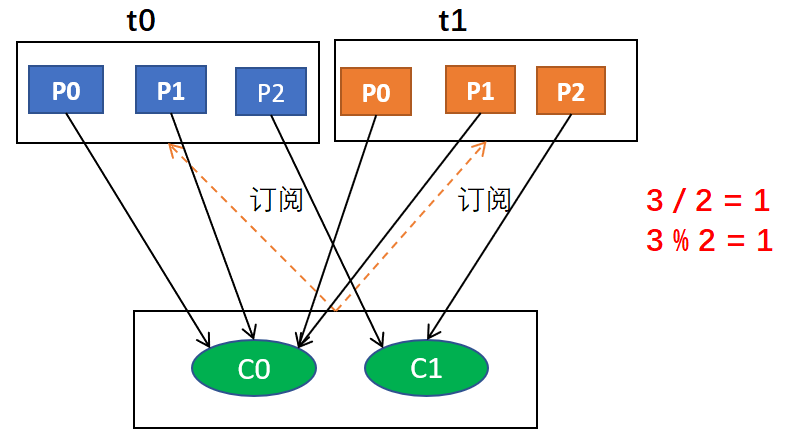
一、Range(默认策略)
分配策略针对的是主题。首先,将分区按数字顺序排行序,消费者按消费者名称的字典序排好序然后,用每个主题下分区总数除以消费者总数,如果能够除尽,则皆大欢喜,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区。
例如,假设有两个消费者C0和C1,两个主题t0和t1,并且每个主题有3个分区,分区的情况是这样的:t0p0,t0p1,t0p2;t1p0,t1p1,t1p2。那么,基于以上信息,最终消费者分配分区的情况是这样的:C0: [t0p0, t0p1, t1p0, t1p1];C1: [t0p2, t1p2]。为什么是这样的结果呢?因为,对于主题t0,分配的结果是C0负责P0和P1,C1负责P2;对于主题t2,也是如此,综合起来就是这个结果。上面的过程用图形表示的话大概是这样的:
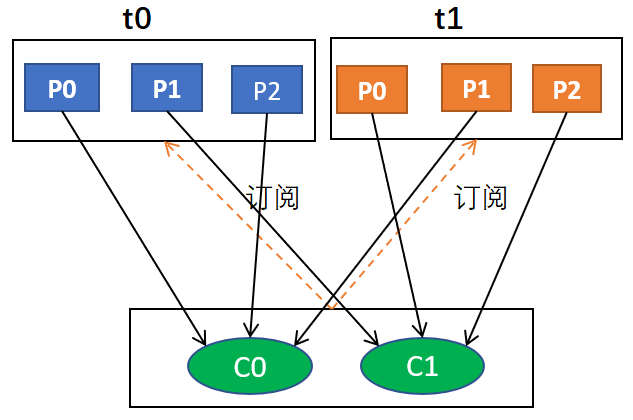
二、RoundRobin
分配策略的具体实现是org.apache.kafka.clients.consumer.RoundRobinAssignor
轮询分配策略是基于所有可用的消费者和所有可用的分区的
与前面的range策略最大的不同就是它不再局限于某个主题
如果所有的消费者实例的订阅都是相同的,那么这样最好了,可用统一分配,均衡分配
例如,假设有两个消费者C0和C1,两个主题t0和t1,每个主题有3个分区,分别是t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,最终分配的结果是这样的:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
用图形表示大概是这样的:
假设,组中每个消费者订阅的主题不一样,分配过程仍然以轮询的方式考虑每个消费者实例,但是如果没有订阅主题,则跳过实例。当然,这样的话分配肯定不均衡。
什么意思呢?也就是说,消费者组是一个逻辑概念,同组意味着同一时刻分区只能被一个消费者实例消费,换句话说,同组意味着一个分区只能分配给组中的一个消费者。事实上,同组也可以不同订阅,这就是说虽然属于同一个组,但是它们订阅的主题可以是不一样的。
例如,假设有3个主题t0,t1,t2;其中,t0有1个分区p0,t1有2个分区p0和p1,t2有3个分区p0,p1和p2;有3个消费者C0,C1和C2;C0订阅t0,C1订阅t0和t1,C2订阅t0,t1和t2。那么,按照轮询分配的话,C0应该负责
首先,肯定是轮询的方式,其次,比如说有主题t0,t1,t2,它们分别有1,2,3个分区,也就是t0有1个分区,t1有2个分区,t2有3个分区;有3个消费者分别从属于3个组,C0订阅t0,C1订阅t0和t1,C2订阅t0,t1,t2;那么,按照轮询分配的话,C0应该负责t0p0,C1应该负责t1p0,其余均由C2负责。
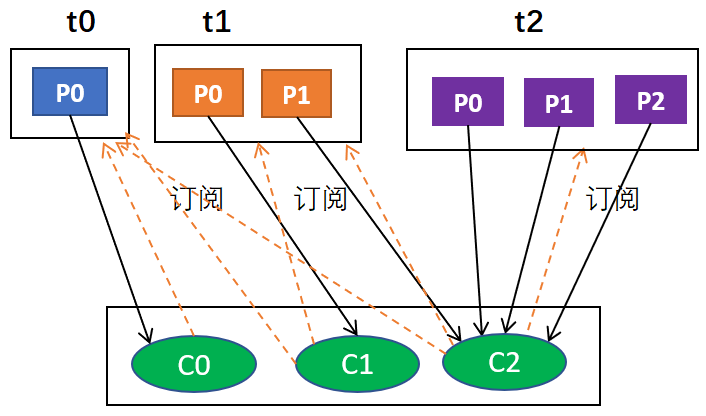
为什么最后的结果是:
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
这是因为,按照轮询t0p1由C0负责,t1p0由C1负责,由于同组,C2只能负责t1p1,由于只有C2订 阅了t2,所以t2所有分区由C2负责,综合起来就是这个结果
上述策略转载至https://www.cnblogs.com/cjsblog/p/9664536.html,作者:废物大师兄
三、StickyAssignor
我们再来看一下StickyAssignor策略,“sticky”这个单词可以翻译为“粘性的”,Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
- 分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个;
- 分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。我们举例来看一下StickyAssignor策略的实际效果。
假设消费组内有3个消费者:C0、C1和C2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有2个分区,也就是说整个消费组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分区。最终的分配结果如下:
1 | 消费者C0:t0p0、t1p1、t3p0 |
这样初看上去似乎与采用RoundRobinAssignor策略所分配的结果相同,但事实是否真的如此呢?
此时假设消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用RoundRobinAssignor策略,那么此时的分配结果如下:
1 | 消费者C0:t0p0、t1p0、t2p0、t3p0 |
如分配结果所示,RoundRobinAssignor策略会按照消费者C0和C2进行重新轮询分配。而如果此时使用的是StickyAssignor策略,那么分配结果为:
1 | 消费者C0:t0p0、t1p1、t3p0、t2p0 |
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
到目前为止所分析的都是消费者的订阅信息都是相同的情况,我们来看一下订阅信息不同的情况下的处理。
举例,同样消费组内有3个消费者:C0、C1和C2,集群中有3个主题:t0、t1和t2,这3个主题分别有1、2、3个分区,也就是说集群中有t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。消费者C0订阅了主题t0,消费者C1订阅了主题t0和t1,消费者C2订阅了主题t0、t1和t2。
如果此时采用RoundRobinAssignor策略,那么最终的分配结果如下所示(和讲述RoundRobinAssignor策略时的一样,这样不妨赘述一下):
1 | 消费者C0:t0p0 |
如果此时采用的是StickyAssignor策略,那么最终的分配结果为:
1 | 消费者C0:t0p0 |
可以看到这是一个最优解(消费者C0没有订阅主题t1和t2,所以不能分配主题t1和t2中的任何分区给它,对于消费者C1也可同理推断)。
假如此时消费者C0脱离了消费组,那么RoundRobinAssignor策略的分配结果为:
1 | 消费者C1:t0p0、t1p1 |
可以看到RoundRobinAssignor策略保留了消费者C1和C2中原有的3个分区的分配:t2p0、t2p1和t2p2(针对结果集1)。而如果采用的是StickyAssignor策略,那么分配结果为:
1 | 消费者C1:t1p0、t1p1、t0p0 |
可以看到StickyAssignor策略保留了消费者C1和C2中原有的5个分区的分配:t1p0、t1p1、t2p0、t2p1、t2p2。
从结果上看StickyAssignor策略比另外两者分配策略而言显得更加的优异,这个策略的代码实现也是异常复杂。
StickyAssignor策略转载至https://www.cnblogs.com/chenxiaoge/p/13335416.html,作者:陈小哥cw
四、ConsumerPartitionAssignor
自定义平衡策略,Kafka允许您自定义平衡策略,可在配置文件设置
3.4. 消费者配置
官方消费者配置地址:https://kafka.apache.org/documentation/#consumerconfigs
1 | format: host1:port1,host2:port2 ... 用于建立与 Kafka 集群的初始连接的主机/端口对列表 |
3.5. 消费者offset机制
主题中每个分区都是有编号的,而且每个分区的消息也会根据提交的日志进行编号。分区中的消息会被分配一个唯一的编号,这个术语叫做offset,用以识别分区中的消息。
传统的消息队列在顺序保存消息到服务器时,如果有多个消费者从队列中读取消息,服务器会顺序发送消息。但是,尽管服务器是顺序发送消息的,但是消费者是异步接收消息的,因此消费者接收到的消息可能并不是顺序的,但消费者并不知道消息是乱序的。为避免这种情况,传统的消息队列通常只允许一个进程读取消息,这也就意味着消息的处理是单向的,而不是并行的。
Kafka在这方面有更好的处理方式,它通过在主题中使用分区完成了并行处理。Kafka既保证了顺序输出又实现了消费者之间的平衡。通过给主题分配分区,将消息分给同组内的消费者,确保每一分区内的消费者是唯一的,并且是顺序读取消息。由于是通过分区来实现多个消费者对象的负载均衡,所以同一消费者组的消费者是不能超过分区的。
offset的保存与管理
一个消费组消费partition,需要保存offset记录消费到哪,0.9版本以前保存在zk中,由于zk的写性能不好,以前的解决方法都是consumer每隔一分钟上报一次。这里zk的性能严重影响了消费的速度,而且很容易出现重复消费。 在0.10版本后,kafka把这个offset的保存,从zk总剥离,保存在一个名叫__consumeroffsets topic的topic中。写进消息的key由<groupid、主题名、分区号>组成,value是偏移量offset。topic配置的清理策略是compact。总是保留最新的key,其余删掉。一般情况下,每个key的offset都是缓存在内存中,查询的时候不用遍历partition,如果没有缓存,第一次就会遍历partition建立缓存,然后查询返回。
__consumer_offsets 在 Kafka 源码中有个更为正式的名字,叫位移主题,即 Offsets Topic。
和你创建的其他主题一样,位移主题就是普通的 Kafka 主题。你可以手动地创建它、修改它,甚至是删除它。只不过,它同时也是一个内部主题,大部分情况下,你其实并不需要“搭理”它,也不用花心思去管理它,把它丢给 Kafka 就完事了。
Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题。我们说过,位移主题就是普通的 Kafka 主题,那么它自然也有对应的分区数。但如果是 Kafka 自动创建的,分区数是怎么设置的呢?这就要看 Broker 端参数 offsets.topic.num.partitions 的取值了。它的默认值是 50,因此 Kafka 会自动创建一个 50 分区的位移主题。如果位移主题是 Kafka 自动创建的,那么该主题的分区数是 50,副本数是 3。
我们前面一直在说 Kafka Consumer 提交位移时会写入该主题,那 Consumer 是怎么提交位移的呢?目前 Kafka Consumer 提交位移的方式有两种:自动提交位移和手动提交位移。
Consumer 端有个参数叫 enable.auto.commit,如果值是 true,则 Consumer 在后台默默地为你定期提交位移,提交间隔由一个专属的参数 auto.commit.interval.ms 来控制。自动提交位移有一个显著的优点,就是省事,你不用操心位移提交的事情,就能保证消息消费不会丢失。但这一点同时也是缺点。因为它太省事了,以至于丧失了很大的灵活性和可控性,你完全没法把控 Consumer 端的位移管理。
事实上,很多与 Kafka 集成的大数据框架都是禁用自动提交位移的,如 Spark、Flink 等。这就引出了另一种位移提交方式:手动提交位移,即设置 enable.auto.commit = false。一旦设置了 false,作为 Consumer 应用开发的你就要承担起位移提交的责任。Kafka Consumer API 为你提供了位移提交的方法,如 consumer.commitSync 等。当调用这些方法时,Kafka 会向位移主题写入相应的消息。 如果你选择的是自动提交位移,那么就可能存在一个问题:只要 Consumer 一直启动着,它就会无限期地向位移主题写入消息。
我们来举个极端一点的例子。假设 Consumer 当前消费到了某个主题的最新一条消息,位移是 100,之后该主题没有任何新消息产生,故 Consumer 无消息可消费了,所以位移永远保持在 100。由于是自动提交位移,位移主题中会不停地写入位移 =100 的消息。显然 Kafka 只需要保留这类消息中的最新一条就可以了,之前的消息都是可以删除的。这就要求 Kafka 必须要有针对位移主题消息特点的消息删除策略,否则这种消息会越来越多,最终撑爆整个磁盘。
Kafka 是怎么删除位移主题中的过期消息的呢?答案就是 Compaction。国内很多文献都将其翻译成压缩,我个人是有一点保留意见的。在英语中,压缩的专有术语是 Compression,它的原理和 Compaction 很不相同,我更倾向于翻译成压实,或干脆采用 JVM 垃圾回收中的术语:整理。
不管怎么翻译,Kafka 使用Compact 策略来删除位移主题中的过期消息,避免该主题无限期膨胀。那么应该如何定义 Compact 策略中的过期呢?对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起。我在这里贴一张来自官网的图片,来说明 Compact 过程。
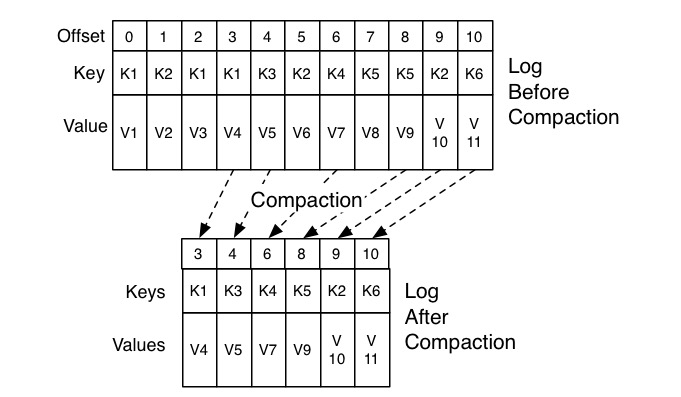
图中位移为 0、2 和 3 的消息的 Key 都是 K1。Compact 之后,分区只需要保存位移为 3 的消息,因为它是最新发送的。
Kafka 提供了专门的后台线程定期地巡检待 Compact 的主题,看看是否存在满足条件的可删除数据。这个后台线程叫 Log Cleaner。很多实际生产环境中都出现过位移主题无限膨胀占用过多磁盘空间的问题,如果你的环境中也有这个问题,我建议你去检查一下 Log Cleaner 线程的状态,通常都是这个线程挂掉了导致的。
1 | bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper localhost:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning |
原文链接:https://blog.csdn.net/qq_41049126/article/details/111311816
作者: 章全蛋
offset手动提交详述
在上一节kafka的consumer消费者offset中,我们提到了自动提交offset下标。 但是offset下标自动提交其实在很多场景都不适用,因为自动提交是在kafka拉取到数据之后就直接提交,这样很容易丢失数据,尤其是在需要事物控制的时候。 很多情况下我们需要从kafka成功拉取数据之后,对数据进行相应的处理之后再进行提交。如拉取数据之后进行写入mysql这种 , 所以这时我们就需要进行手动提交kafka的offset下标。
手动提交测试可以查看这篇博客:
https://www.cnblogs.com/xuwujing/p/8432984.html
作者:虚无境
4. kafka中的broker
4.1. broker基本概念
- Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。
- Broker不保存订阅者(消费者)的状态,由订阅者自己保存。
- 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),Kafka采用基于时间的SLA(服务保证),消息保存一定时间(通常7天)后会删除。
- 消费订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息
- broker指的是kafka的服务端,可以是一个服务器也可以是一个集群。producer和consumer都相当于这个服务端的客户端。(broker-list指定集群中的一个或者多个服务器,一般我们再使用console producer的时候,这个参数是必备参数,另外一个必备的参数是topic)
- 本地主机如果要模拟多个broker,方法是复制多个server.properties,然后修改里面的端口, broker.id等配置模拟多个broker集群。
原文链接:https://blog.csdn.net/weixin_38004638/article/details/90231607
作者:陈晨辰~
4.2. broker关系图
4.2.1 broker与Zookeeper
Zookeeper详情可以查看Zookeeper介绍。
一个broker是由ZooKeeper管理的单个Kafka节点。一组brokers组成了Kafka集群。在Kaka中创建的主题基于分区,复制和其他因素分布在broker中。当broker节点基于ZooKeeper中存储的状态失败时,它会自动重新平衡群集,如果领导分区丢失,则其中一个跟随者请求被选为领导者。
ZooKeeper存储元数据和Kafka集群的当前状态。例如,主题名称,分区数量,复制,请愿的领导者详细信息以及消费者组详细信息等详细信息存储在ZooKeeper中。您可以将ZooKeeper视为项目经理,他负责管理项目中的资源并记住项目的状态。
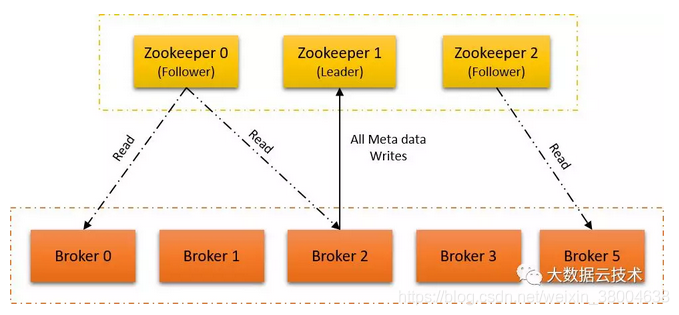
broker 在 ZooKeeper 中的注册
- 为了记录 broker 的注册信息,在 ZooKeeper 上,专门创建了属于 Kafka 的一个节点,其路径为 /brokers
- Kafka 的每个 broker 启动时,都会到 ZooKeeper 中进行注册,告诉 ZooKeeper 其 broker.id,在整个集群中,broker.id 应该全局唯一,并在 ZooKeeper 上创建其属于自己的节点,其节点路径为 /brokers/ids/{broker.id};
- 创建完节点后,Kafka 会将该 broker 的 broker.name 及端口号记录到该节点;
- 另外,该 broker 节点属性为临时节点,当 broker 会话失效时,ZooKeeper 会删除该节点,这样,我们就可以很方便的监控到broker 节点的变化,及时调整负载均衡等。

原文链接:https://blog.csdn.net/valada/article/details/80892612
作者:蔚1
4.2.2 broker与Topic
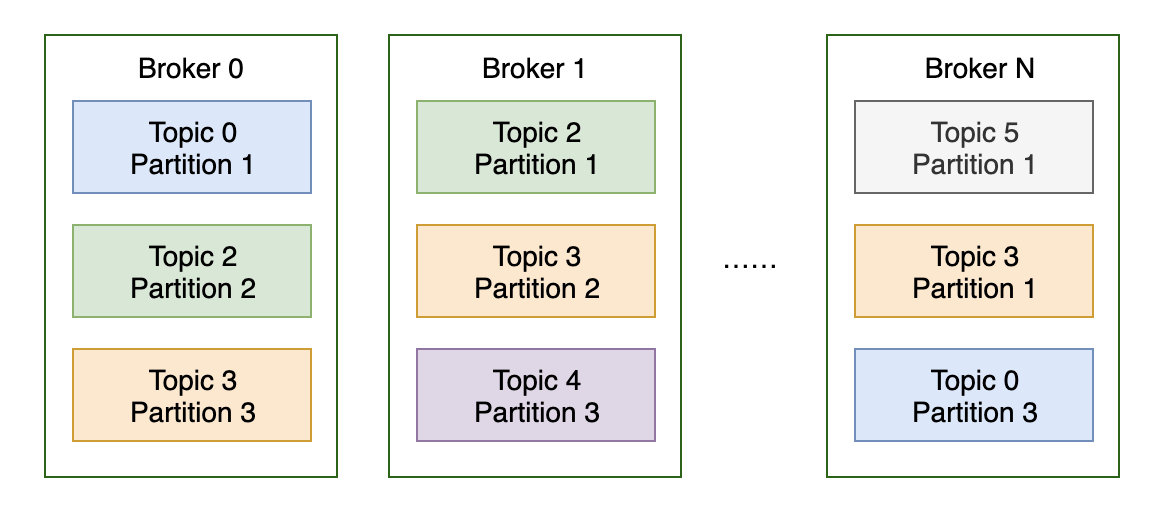
一个topic对应多个partition,partition分布在多broker上,多broker一起提供kafka服务。
Topic 是一个逻辑概念,代表了一类消息。通常我们可以使用不同的 Topic 来区分不同的业务。partition是Topic下的分区,也是一个个文件,broker是启动的服务的概念
4.2.3 broker与partition
broker将消息存储在对应的partition当中。
4.2.4 broker与producer(producer与partition)
生产者将消息发送到broker进行分区存储。
分区存储的原则
1.如果生产者指定放到broker的哪个partition中了,那就会按指定的分区存储
2.如果生产者没有指明partition但存储的内容含有key,则把key的hash值(采用MurmurHash2算法,具备高运算性能及低碰撞率)与broker的分区数进行取模,然后放到对应分区中
3.如果既没有指明partition也没有存储key,则第一次存储会随机生成一个整数,让这个整数和partition数取模,然后放到对应的分区中。第二次存储时再第一次随机生成的随机数上自增再取模执行同样的操作。
4.2.5 broker与consumer
consumer采用pull(拉)模式从broker中读取数据。 拉取模式也有不足,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,kafka消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间后再返回,这段时长即为timeout
4.3. broker集群
4.4. broker配置
官网地址:https://kafka.apache.org/documentation/#brokerconfigs
1 | ########################### Server Basics ############################# |
5. kafka中的Topic
5.1. Topic概念
topic 是一个逻辑概念,代表了一类消息。通常我们可以使用不同的 topic 来区分不同的业务。
每个 Kafka topic 都由若干个 partition 组成,Kafka 的 partition 是不可修改的有序消息日志。用户对partition 唯一能做的操作就是在消息序列的尾部追加写入消息。每条消息会被分配一个初始的序列号,可以唯一定位到某 partition 下的一条消息,成为消息位移(offset)。
为了使您的数据具有容错性和高可用性,每个主题都可以复制,甚至可以跨地理区域或数据中心进行复制,以便始终有多个代理拥有数据副本,以防万一出现问题,您想要对经纪人进行维护等。常见的生产设置是复制因子为 3,即,您的数据将始终存在三个副本。此复制在主题分区级别执行。
作者:analanxingde 链接:https://www.jianshu.com/p/88303bbd1e9d
5.2. Topic设计
kafka为什么要加入topic概念? topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。
producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。 为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。
所以把topic内的数据分布到整个集群就是一个自然而然的设计方式。
5.3. Topic配置
官网地址:https://kafka.apache.org/documentation/#topicconfigs
1 | “delete”或“compact”或两者兼有的字符串。此字符串指定要在旧日志段上使用的保留策略。当达到保留时间或大小限制时,默认策略(“删除”)将丢弃旧段。“压缩”设置将启用主题的日志压缩。 |
服务端的配置文件中设置的auto.create.topics.enable为true,Producer向服务器一个不存在的topic发送数据,该topic会被自动创建。
5.4. 针对上述Kafka使用的fsync补充说明
传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行。当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时,再将该缓冲排入输出队列,然后待其到达队首时,才进行实际的I/O操作。这种输出方式被称为延迟写(delayed write)(Bach [1986]第3章详细讨论了缓冲区高速缓存)。 延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,使得欲写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能造成文件更新内容的丢失。为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个函数。 sync函数只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。 通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync函数。这就保证了定期冲洗内核的块缓冲区。命令sync(1)也调用sync函数。 fsync函数只对由文件描述符filedes指定的单一文件起作用,并且等待写磁盘操作结束,然后返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上。 fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性。
1. write不够,需要fsync
一般情况下,对硬盘(或者其他持久存储设备)文件的write操作,更新的只是内存中的页缓存(page cache),而脏页面不会立即更新到硬盘中,而是由操作系统统一调度,如由专门的flusher内核线程在满足一定条件时(如一定时间间隔、内存中的脏页达到一定比例)内将脏页面同步到硬盘上(放入设备的IO请求队列)。
因为write调用不会等到硬盘IO完成之后才返回,因此如果OS在write调用之后、硬盘同步之前崩溃,则数据可能丢失。虽然这样的时间窗口很小,但是对于需要保证事务的持久化(durability)和一致性(consistency)的数据库程序来说,write()所提供的“松散的异步语义”是不够的,通常需要OS提供的同步IO(synchronized-IO)原语来保证:
1 | 1 #include <unistd.h> |
fsync的功能是确保文件fd所有已修改的内容已经正确同步到硬盘上,该调用会阻塞等待直到设备报告IO完成。
2. fsync的性能问题,与fdatasync
除了同步文件的修改内容(脏页),fsync还会同步文件的描述信息(metadata,包括size、访问时间st_atime & st_mtime等等),因为文件的数据和metadata通常存在硬盘的不同地方,因此fsync至少需要两次IO写操作,fsync的man page这样说:
“Unfortunately fsync() will always initialize two write operations : one for the newly written data and another one in order to update the modification time stored in the inode. If the modification time is not a part of the transaction concept fdatasync() can be used to avoid unnecessary inode disk write operations.”
多余的一次IO操作,有多么昂贵呢?根据Wikipedia的数据,当前硬盘驱动的平均寻道时间(Average seek time)大约是3~15ms,7200RPM硬盘的平均旋转延迟(Average rotational latency)大约为4ms,因此一次IO操作的耗时大约为10ms左右。这个数字意味着什么?下文还会提到。
Posix同样定义了fdatasync,放宽了同步的语义以提高性能:
1 | 1 #include <unistd.h> |
fdatasync的功能与fsync类似,但是仅仅在必要的情况下才会同步metadata,因此可以减少一次IO写操作。那么,什么是“必要的情况”呢?根据man page中的解释:
“fdatasync does not flush modified metadata unless that metadata is needed in order to allow a subsequent data retrieval to be corretly handled.”
举例来说,文件的尺寸(st_size)如果变化,是需要立即同步的,否则OS一旦崩溃,即使文件的数据部分已同步,由于metadata没有同步,依然读不到修改的内容。而最后访问时间(atime)/修改时间(mtime)是不需要每次都同步的,只要应用程序对这两个时间戳没有苛刻的要求,基本无伤大雅。
PS:open时的参数O_SYNC/O_DSYNC有着和fsync/fdatasync类似的语义:使每次write都会阻塞等待硬盘IO完成。(实际上,Linux对O_SYNC/O_DSYNC做了相同处理,没有满足Posix的要求,而是都实现了fdatasync的语义)相对于fsync/fdatasync,这样的设置不够灵活,应该很少使用。
3. 使用fdatasync优化日志同步
文章开头时已提到,为了满足事务要求,数据库的日志文件是常常需要同步IO的。由于需要同步等待硬盘IO完成,所以事务的提交操作常常十分耗时,成为性能的瓶颈。
在Berkeley DB下,如果开启了AUTO_COMMIT(所有独立的写操作自动具有事务语义)并使用默认的同步级别(日志完全同步到硬盘才返回),写一条记录的耗时大约为5~10ms级别,基本和一次IO操作(10ms)的耗时相同。
我们已经知道,在同步上fsync是低效的。但是如果需要使用fdatasync减少对metadata的更新,则需要确保文件的尺寸在write前后没有发生变化。日志文件天生是追加型(append-only)的,总是在不断增大,似乎很难利用好fdatasync。
且看Berkeley DB是怎样处理日志文件的:
1.每个log文件固定为10MB大小,从1开始编号,名称格式为“log.%010d”
2.每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
3.向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
4.如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销
fsync补充说明转载至:https://blog.csdn.net/zhouxinlin2009/article/details/89633464
作者:zhouxinlin2009
6. kafka中的Partition
6.1. Partition基本概念
Partition分区,或者说分组。Partition是Kafka提升吞吐量的一个关键设计。这样可以让消费者多线程并行接收消息。创建Topic时可指定Partition数量。一个Topic可以分为多个Partition,也可以只有一个Partition。每一个Partition是一个有序的,不可变的消息序列。每一个消息在各自的Partition中有唯一的ID。这些ID是有序的。称之为offset,offset在不同的Partition中是可以重复的,但是在一个Partition中是不可能重复的。越大的offset的消息是最新的。Kafka只保证在每个Partition中的消息是有序的,就会带来一个问题,即如果一个Consumer在不同的Partition中获取消息,那么消息的顺序也许是和Producer发送到Kafka中的消息的顺序是不一致的。
一个Topic的多个Partition可以分布式部署在不同的Server上,一个Kafka集群。配置项为:num.partitions,默认是1。每一个Partition也可以在Broker上复制多分,用来做容错。
额外配一张宏观关系图方便巩固理解:
Producter: 一个生产者可以指定多个分区,一个分区也可以由多个prodicter指定,消息不会直接写入副本。
Topic:一个broker可以有多个topic,一个topic也可以分布在多个broker上,Topic可以有多个分区,每个分区配置多个副本
Partition: 红色Partition为leader, 黑色Partition两个分别为leader副本和follow副本
Consumer:一个分区只能被同一个消费组消费一次。
6.2. Partition设计
6.2.1 Partition引入
Partition的引入就是解决水平扩展问题的一个方案。
每个partition可以被认为是一个无限长度的数组,新数据顺序追加进这个数组。
物理上,每个partition对应于一个文件夹。一个broker上可以存放多个partition。
这样,producer可以将数据发送给多个broker上的多个partition,consumer也可以并行从多个broker上的不同paritition上读数据,实现了水平扩展。
如果没有分区,topic中的segment消息写满后,直接给订阅者不是也可以吗 ?
“segment消息写满后”,consume消费数据并不需要等到segment写满,只要有一条数据被commit,就可以立马被消费 。
segment对应一个文件(实现上对应2个文件,一个数据文件,一个索引文件),一个partition对应一个文件夹,一个partition里理论上可以包含任意多个segment。(详细可以查看kafka基本认识-核心机制-kafka数据结构)
所以partition可以认为是在segment上做了一层包装。
这个问题换个角度问可能更好,“为什么有了partition还需要segment”。
如果不引入segment,一个partition直接对应一个文件(应该说两个文件,一个数据文件,一个索引文件),那这个文件会一直增大。
同时,在做数据清除时,需要把文件的前面部分给删除,不符合kafka对文件的顺序写优化设计方案。
引入segment后,每次做数据清除,只需要把旧的segment整个文件删除即可,保证了每个segment的顺序写。
转载至https://blog.csdn.net/ywl470812087/article/details/105210041
作者:ywl470812087
6.2.2 Partition复制集引入
一、partition集群
为什么使用partition集群, 越多的分区可以提供更高的吞吐量
在kafka中,单个patition是kafka并行操作的最小单元。在producer和broker端,向每一个分区写入数据是可以完全并行化的,此时,可以通过加大硬件资源的利用率来提升系统的吞吐量,例如对数据进行压缩。在consumer段,kafka只允许单个partition的数据被一个consumer线程消费。因此,在consumer端,每一个Consumer Group内部的consumer并行度完全依赖于被消费的分区数量。综上所述,通常情况下,在一个Kafka集群中,partition的数量越多,意味着可以到达的吞吐量越大。
越多的分区需要打开更多地文件句柄
在kafka的broker中,每个分区都会对照着文件系统的一个目录。在kafka的数据日志文件目录中,每个日志数据段都会分配两个文件,一个索引文件和一个数据文件。当前版本的kafka,每个broker会为每个日志段文件打开一个index文件句柄和一个数据文件句柄。因此,随着partition的增多,需要底层操作系统配置更高的文件句柄数量限制。这更多的是一个配置问题。我们曾经见到过,在生产环境Kafka集群中,每个broker打开的文件句柄数量超过30,000。
更多地分区会导致更高的不可用性
Kafka通过多副本复制技术,实现kafka集群的高可用和稳定性。每个partition都会有多个数据副本,每个副本分别存在于不同的broker。所有的数据副本中,有一个数据副本为Leader,其他的数据副本为follower。在kafka集群内部,所有的数据副本皆采用自动化的方式进行管理,并且确保所有的数据副本的数据皆保持同步状态。不论是producer端还是consumer端发往partition的请求,皆通过leader数据副本所在的broker进行处理。当broker发生故障时,对于leader数据副本在该broker的所有partition将会变得暂时不可用。Kafka将会自动在其他数据副本中选择出一个leader,用于接收客户端的请求。这个过程由kafka controller节点broker自动完成,主要是从Zookeeper读取和修改受影响partition的一些元数据信息。在当前的kafka版本实现中,对于zookeeper的所有操作都是由kafka controller来完成的(serially的方式)
在通常情况下,当一个broker有计划地停止服务时,那么controller会在服务停止之前,将该broker上的所有leader一个个地移走。由于单个leader的移动时间大约只需要花费几毫秒,因此从客户层面看,有计划的服务停机只会导致系统在很小时间窗口中不可用。(注:在有计划地停机时,系统每一个时间窗口只会转移一个leader,其他leader皆处于可用状态。)
然而,当broker非计划地停止服务时(例如,kill -9方式),系统的不可用时间窗口将会与受影响的partition数量有关。假如,一个2节点的kafka集群中存在2000个partition,每个partition拥有2个数据副本。当其中一个broker非计划地宕机,所有1000个partition同时变得不可用。假设每一个partition恢复时间是5ms,那么1000个partition的恢复时间将会花费5秒钟。因此,在这种情况下,用户将会观察到系统存在5秒钟的不可用时间窗口。
更不幸的情况发生在宕机的broker恰好是controller节点时。在这种情况下,新leader节点的选举过程在controller节点恢复到新的broker之前不会启动。Controller节点的错误恢复将会自动地进行,但是新的controller节点需要从zookeeper中读取每一个partition的元数据信息用于初始化数据。例如,假设一个kafka集群存在10,000个partition,从zookeeper中恢复元数据时每个partition大约花费2ms,则controller的恢复将会增加约20秒的不可用时间窗口。
通常情况下,非计划的宕机事件发生的情况是很少的。如果系统可用性无法容忍这些少数情况的场景,我们最好是将每个broker的partition数量限制在2,000到4,000,每个kafka集群中partition的数量限制在10,000以内。
越多的分区可能增加端对端的延迟
Kafka端对端延迟定义为producer端发布消息到consumer端接收消息所需要的时间。即consumer接收消息的时间减去producer发布消息的时间。Kafka只有在消息提交之后,才会将消息暴露给消费者。例如,消息在所有in-sync副本列表同步复制完成之后才暴露。因此,in-sync副本复制所花时间将是kafka端对端延迟的最主要部分。在默认情况下,每个broker从其他broker节点进行数据副本复制时,该broker节点只会为此工作分配一个线程(可以在server中配置修改),该线程需要完成该broker所有partition数据的复制。经验显示,将1000个partition从一个broker到另一个broker所带来的时间延迟约为20ms,这意味着端对端的延迟至少是20ms。这样的延迟对于一些实时应用需求来说显得过长。
注意,上述问题可以通过增大kafka集群来进行缓解。例如,将1000个分区leader放到一个broker节点和放到10个broker节点,他们之间的延迟是存在差异的。在10个broker节点的集群中,每个broker节点平均需要处理100个分区的数据复制。此时,端对端的延迟将会从原来的数十毫秒变为仅仅需要几毫秒。
根据经验,如果你十分关心消息延迟问题,限制每个broker节点的partition数量是一个很好的主意:对于b个broker节点和复制因子为r的kafka集群,整个kafka集群的partition数量最好不超过100br个.
越多的partition意味着需要客户端需要更多的内存
在最新发布的0.8.2版本的kafka中,我们开发了一个更加高效的Java producer。新版producer拥有一个比较好的特征,他允许用户为待接入消息存储空间设置内存大小上限。在内部实现层面,producer按照每一个partition来缓存消息。在数据积累到一定大小或者足够的时间时,积累的消息将会从缓存中移除并发往broker节点。
如果partition的数量增加,消息将会在producer端按更多的partition进行积累。众多的partition所消耗的内存汇集起来,有可能会超过设置的内容大小限制。当这种情况发生时,producer必须通过消息堵塞或者丢失一些新消息的方式解决上述问题,但是这两种做法都不理想。为了避免这种情况发生,我们必须重新将produder的内存设置得更大一些。
根据经验,为了达到较好的吞吐量,我们必须在producer端为每个分区分配至少几十KB的内存,并且在分区数量显著增加时调整可以使用的内存数量。
类似的事情对于consumer端依然有效。Consumer端每次从kafka按每个分区取出一批消息进行消费。消费的分区数越多,需要的内存数量越大。尽管如此,上述方式主要运用于非实时的应用场景。
总结
通常情况下,kafka集群中越多的partition会带来越高的吞吐量。但是,我们必须意识到集群的partition总量过大或者单个broker节点partition过多,都会对系统的可用性和消息延迟带来潜在的影响。未来,我们计划对这些限制进行一些改进,让kafka在分区数量方面变得更加可扩展。
二、partition副本
Kafka 在可配置数量的服务器上复制每个主题分区的日志(您可以逐个主题地设置此复制因子)。这允许在集群中的服务器发生故障时自动故障转移到这些副本,以便在出现故障时消息仍然可用。
复制单位是主题分区。在非故障条件下,Kafka 中的每个分区都有一个领导者和零个或多个追随者。包括领导者在内的副本总数构成了复制因子。所有读取和写入都转到分区的领导者。通常,分区比broker多得多,并且领导者在broker之间均匀分布。跟随者上的日志与领导者的日志相同——都具有相同的偏移量和相同顺序的消息(当然,在任何给定时间,领导者在其日志末尾可能有一些尚未复制的消息)。
追随者像普通的 Kafka 消费者一样消费来自领导者的消息,并将它们应用到自己的日志中。让追随者从领导者那里拉取有一个很好的特性,即允许追随者自然地将他们应用到他们的日志的日志条目组合在一起。
kafka动态维护了一个同步状态的副本的集合(a set of In-Sync Replicas),简称ISR。
replication对Kafka的吞吐率是有一定影响的,但极大的增强了可用性。
与大多数分布式系统一样,自动处理故障需要精确定义节点“活着”意味着什么。对于 Kafka 节点活跃度有两个条件
- broker节点必须能够保持与 ZooKeeper 的会话(通过 ZooKeeper 的心跳机制)
- 如果它是一个跟随者,它必须复制发生在领导者上的写入,并且不会落后“太远”
我们将满足这两个条件的节点称为“同步”,以避免“活着”或“失败”的模糊性。领导者跟踪“同步”节点集。如果跟随者死亡、卡住或落后,领导者会将其从同步副本列表中删除。卡住和滞后副本的确定replica.lag.time.max.ms 配置控制。
leader会track “in sync”的node list(ISR)。如果一个follower宕机,或者落后太多,leader将把它从”in sync” list中移除。这里所描述的“落后太多”指follower复制的消息落后于leader后的条数超过预定值,该在$KAFKA_HOME/config/server.properties中配置
转载于https://zhuanlan.zhihu.com/p/354358485
作者:我啊赛
6.2.3 Partition复制集选举
摘至官网:https://kafka.apache.org/documentation/#replication
如果领导者没有失败,我们就不需要追随者!当领导者确实死亡时,我们需要从追随者中选择一个新的领导者。但是追随者本身可能会落后或崩溃,因此我们必须确保选择最新的追随者。
假设我们有 2 f +1 个副本。如果f +1 个副本必须在领导者声明提交之前收到消息,并且如果我们通过从至少f +1 个副本中选出具有最完整日志的跟随者来选举新领导者 ,那么,不超过f失败,领导者保证拥有所有提交的消息。
这个家族中有各种各样的算法,包括 ZooKeeper 的 Zab、 Raft和Viewstamped Replication。我们所知道的与 Kafka 的实际实现最相似的学术出版物是 来自微软的PacificA。
1 | PacificA:简要说明:当一个scondary故障时,primary在向该secondary发送lease请求时会超时, |
Kafka 不是通过多数投票,而是动态维护一组同步副本(ISR),这些副本会赶上领导者。只有这个集合的成员才有资格被选举为领导者。
当所有副本都死亡时,实际系统需要做一些合理的事情。如果您不幸发生这种情况,重要的是要考虑会发生什么。有两种行为可以实现:
- 等待 ISR 中的一个副本恢复生命并选择这个副本作为领导者(希望它仍然拥有所有数据)。
- 选择作为领导者复活的第一个副本(不一定在 ISR 中)。
一个简单的领导者选举实现最终会在该节点失败时为该节点托管的所有分区运行每个分区的选举。相反,我们选择其中一位经纪人作为“控制器”。该控制器检测代理级别的故障,并负责更改故障代理中所有受影响分区的领导者。结果是,我们能够将许多必需的领导层变更通知一起批处理,这使得大量分区的选举过程更加便宜和快速。如果控制器出现故障,幸存的代理之一将成为新的控制器。
补充说明
分区leader副本的选举由Kafka Controller 负责具体实施。当创建分区(创建主题或增加分区都有创建分区的动作)或分区上线(比如分区中原先的leader副本下线,此时分区需要选举一个新的leader上线来对外提供服务)的时候都需要执行leader的选举动作。
基本思路是按照AR集合中副本的顺序查找第一个存活的副本,并且这个副本在ISR集合中。一个分区的AR集合在分配的时候就被指定,并且只要不发生重分配的情况,集合内部副本的顺序是保持不变的,而分区的ISR集合中副本的顺序可能会改变。注意这里是根据AR的顺序而不是ISR的顺序进行选举的。这个说起来比较抽象,有兴趣的读者可以手动关闭/开启某个集群中的broker来观察一下具体的变化。
还有一些情况也会发生分区leader的选举,比如当分区进行重分配(reassign)的时候也需要执行leader的选举动作。这个思路比较简单:从重分配的AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中。
再比如当发生优先副本(preferred replica partition leader election)的选举时,直接将优先副本设置为leader即可,AR集合中的第一个副本即为优先副本。
还有一种情况就是当某节点被优雅地关闭(也就是执行ControlledShutdown)时,位于这个节点上的leader副本都会下线,所以与此对应的分区需要执行leader的选举。这里的具体思路为:从AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中,与此同时还要确保这个副本不处于正在被关闭的节点上。下图的broker可以理解为broker上对应的partition。
6.2.4 Partition复制集扩容
在分区扩容时分区会执行重分配,而在执行分区重分配的过程中,对集群会有两点主要影响:
- 分区重分配主要是对主题数据进行 Broker 间的迁移,因此会占用集群的带宽资源;
- 分区重分配会改变分区 Leader 所在的 Broker,因此会影响客户端。
针对以上两点,第一点可以在晚间业务低峰时操作,必要时还可以和业务沟通,临时缩短数据保存时间,加快迁移,减少带宽影响时间。针对第二点,有两个方案:
- 整个分配方案分成两个步骤:1)手动生成分配方案,原有分区
Leader位置不改变,只对副本进行分区重分配;2)等待数据迁移完成后,再手动更改分区分配方案,目的是均衡Leader。 - 直接用
Kafka官方提供的分区重新分配 工具 生成分区重分配方案,直接执行分区重分配。
本文来源:码农网 本文链接:https://www.codercto.com/a/112309.html
6.2.5 Partition复制集与Broker
一般情况下partition的数量大于等于broker的数量,并且所有partition的leader均匀分布在broker上。
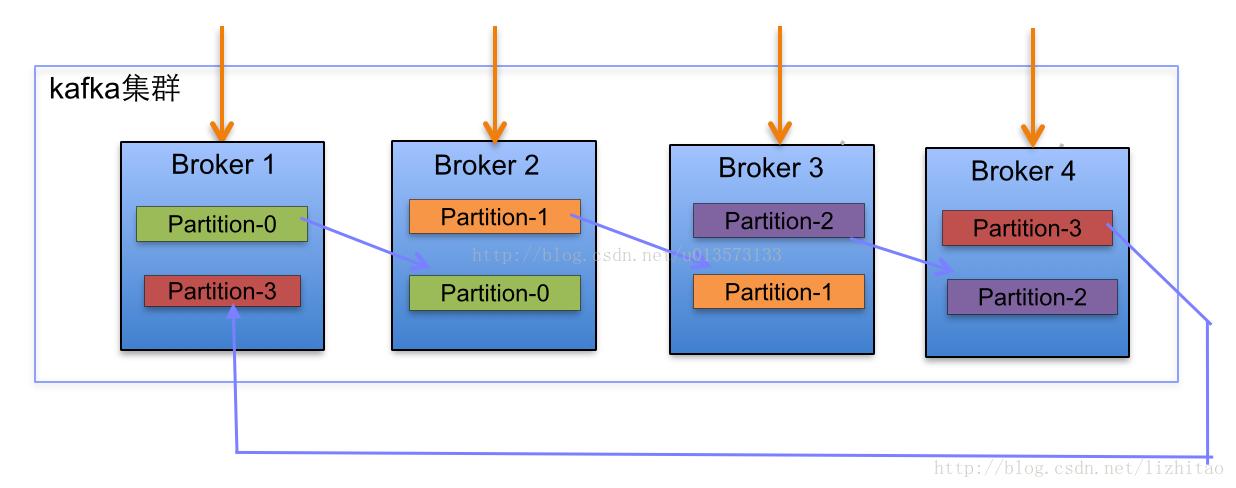
下面以一个Kafka集群中4个Broker举例,创建1个topic包含4个Partition,2 Replication;数据Producer流动(1)如图所示:
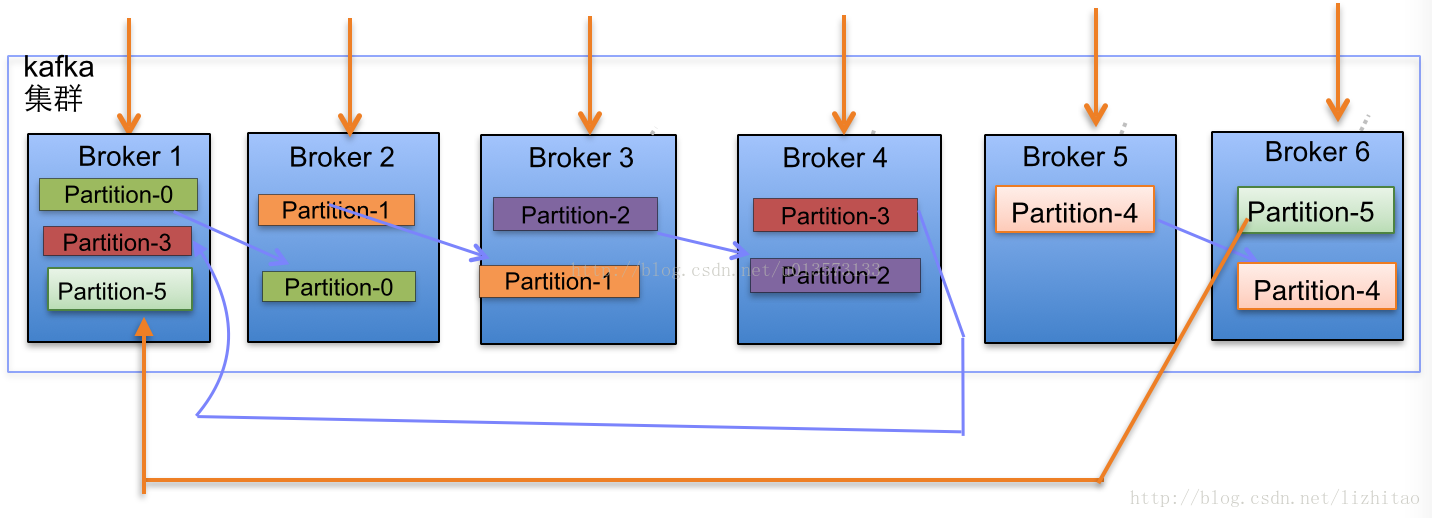
(2)当集群中新增2节点,Partition增加到6个时分布情况如下:
副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图中每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
6.2.6 Partition复制集与consumer
我们可以更精确地定义,当该分区的所有同步副本已将消息应用于其日志时,该消息被视为已提交。只有已提交的消息才会发送给消费者。这意味着消费者不必担心可能会看到如果领导者失败可能会丢失的消息。另一方面。
Kafka分布式的单位是partition,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。不同partition之间不能保证顺序。
下面针对offset
本节主要讨论0.11版本之前Kafka的副本备份机制的设计问题以及0.11是如何解决的。简单来说,0.11之前副本备份机制主要依赖水位(或水印)的概念,而0.11采用了leader epoch来标识备份进度。后面我们会详细讨论两种机制的差异。不过首先先做一些基本的名词含义解析。
水位或水印(watermark)一词,也可称为高水位(high watermark),通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。一个比较经典的表述为:流式系统保证在水位t时刻,创建时间(event time) = t’且t’ ≤ t的所有事件都已经到达或被观测到。在Kafka中,水位的概念反而与时间无关,而是与位置信息相关。严格来说,它表示的就是位置信息,即位移(offset)。网上有一些关于Kafka watermark的介绍,本不应再赘述,但鉴于本文想要重点强调的leader epoch与watermark息息相关,故这里再费些篇幅阐述一下watermark。注意:由于Kafka源码中使用的名字是高水位,故本文将始终使用high watermaker或干脆简称为HW。
Kafka分区下有可能有很多个副本(replica)用于实现冗余,从而进一步实现高可用。副本根据角色的不同可分为3类:
- leader副本:响应clients端读写请求的副本
- follower副本:被动地备份leader副本中的数据,不能响应clients端读写请求。
- ISR副本:包含了leader副本和所有与leader副本保持同步的follower副本——如何判定是否与leader同步后面会提到
每个Kafka副本对象都有两个重要的属性:LEO和HW。注意是所有的副本,而不只是leader副本。
- LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。另外,leader LEO和follower LEO的更新是有区别的。我们后面会详细说
- HW:即上面提到的水位值。对于同一个副本对象而言,其HW值不会大于LEO值。小于等于HW值的所有消息都被认为是“已备份”的(replicated)。同理,leader副本和follower副本的HW更新是有区别的,我们后面详谈。
我们使用下图来形象化地说明两者的关系:
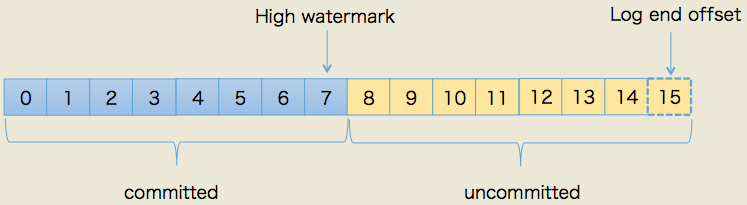
上图中,HW值是7,表示位移是07的所有消息都已经处于“已备份状态”(committed),而LEO值是15,那么814的消息就是尚未完全备份(fully replicated)——为什么没有15?因为刚才说过了,LEO指向的是下一条消息到来时的位移,故上图使用虚线框表示。我们总说consumer无法消费未提交消息。这句话如果用以上名词来解读的话,应该表述为:consumer无法消费分区下leader副本中位移值大于分区HW的任何消息。这里需要特别注意分区HW就是leader副本的HW值。
既然副本分为leader副本和follower副本,而每个副本又都有HW和LEO,那么它们是怎么被更新的呢?它们更新的机制又有什么区别呢?我们一一来分析下:
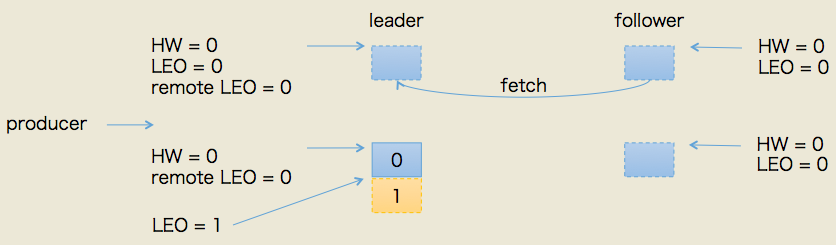
一、follower副本何时更新LEO?
如前所述,follower副本只是被动地向leader副本请求数据,具体表现为follower副本不停地向leader副本所在的broker发送FETCH请求,一旦获取消息后写入自己的日志中进行备份。那么follower副本的LEO是何时更新的呢?首先我必须言明,Kafka有两套follower副本LEO(明白这个是搞懂后面内容的关键,因此请多花一点时间来思考):1. 一套LEO保存在follower副本所在broker的副本管理机中;2. 另一套LEO保存在leader副本所在broker的副本管理机中——换句话说,leader副本机器上保存了所有的follower副本的LEO。
为什么要保存两套?这是因为Kafka使用前者帮助follower副本更新其HW值;而利用后者帮助leader副本更新其HW使用。下面我们分别看下它们被更新的时机。
1 follower副本端的follower副本LEO何时更新?
follower副本端的LEO值就是其底层日志的LEO值,也就是说每当新写入一条消息,其LEO值就会被更新(类似于LEO += 1)。当follower发送FETCH请求后,leader将数据返回给follower,此时follower开始向底层log写数据,从而自动地更新LEO值。
2 leader副本端的follower副本LEO何时更新?
leader副本端的follower副本LEO的更新发生在leader在处理follower FETCH请求时。一旦leader接收到follower发送的FETCH请求,它首先会从自己的log中读取相应的数据,但是在给follower返回数据之前它先去更新follower的LEO(即上面所说的第二套LEO)。
二、follower副本何时更新HW?
follower更新HW发生在其更新LEO之后,一旦follower向log写完数据,它会尝试更新它自己的HW值。具体算法就是比较当前LEO值与FETCH响应中leader的HW值,取两者的小者作为新的HW值。这告诉我们一个事实:如果follower的LEO值超过了leader的HW值,那么follower HW值是不会越过leader HW值的。
三、leader副本何时更新LEO?
和follower更新LEO道理相同,leader写log时就会自动地更新它自己的LEO值。
四、leader副本何时更新HW值?
前面说过了,leader的HW值就是分区HW值,因此何时更新这个值是我们最关心的,因为它直接影响了分区数据对于consumer的可见性 。以下4种情况下leader会尝试去更新分区HW——切记是尝试,有可能因为不满足条件而不做任何更新:
- 副本成为leader副本时:当某个副本成为了分区的leader副本,Kafka会尝试去更新分区HW。这是显而易见的道理,毕竟分区leader发生了变更,这个副本的状态是一定要检查的!不过,本文讨论的是当系统稳定后且正常工作时备份机制可能出现的问题,故这个条件不在我们的讨论之列。
- broker出现崩溃导致副本被踢出ISR时:若有broker崩溃则必须查看下是否会波及此分区,因此检查下分区HW值是否需要更新是有必要的。本文不对这种情况做深入讨论
- producer向leader副本写入消息时:因为写入消息会更新leader的LEO,故有必要再查看下HW值是否也需要修改
- leader处理follower FETCH请求时:当leader处理follower的FETCH请求时首先会从底层的log读取数据,之后会尝试更新分区HW值
特别注意上面4个条件中的最后两个。它揭示了一个事实——当Kafka broker都正常工作时,分区HW值的更新时机有两个:leader处理PRODUCE请求时和leader处理FETCH请求时。另外,leader是如何更新它的HW值的呢?前面说过了,leader broker上保存了一套follower副本的LEO以及它自己的LEO。当尝试确定分区HW时,它会选出所有满足条件的副本,比较它们的LEO(当然也包括leader自己的LEO),并选择最小的LEO值作为HW值。这里的满足条件主要是指副本要满足以下两个条件之一:
- 处于ISR中
- 副本LEO落后于leader LEO的时长不大于replica.lag.time.max.ms参数值(默认是10s)
乍看上去好像这两个条件说得是一回事,毕竟ISR的定义就是第二个条件描述的那样。但某些情况下Kafka的确可能出现副本已经“追上”了leader的进度,但却不在ISR中——比如某个从failure中恢复的副本。如果Kafka只判断第一个条件的话,确定分区HW值时就不会考虑这些未在ISR中的副本,但这些副本已经具备了“立刻进入ISR”的资格,因此就可能出现分区HW值越过ISR中副本LEO的情况——这肯定是不允许的,因为分区HW实际上就是ISR中所有副本LEO的最小值。
好了,理论部分我觉得说的差不多了,下面举个实际的例子。我们假设有一个topic,单分区,副本因子是2,即一个leader副本和一个follower副本。我们看下当producer发送一条消息时,broker端的副本到底会发生什么事情以及分区HW是如何被更新的。
下图是初始状态,我们稍微解释一下:初始时leader和follower的HW和LEO都是0(严格来说源代码会初始化LEO为-1,不过这不影响之后的讨论)。leader中的remote LEO指的就是leader端保存的follower LEO,也被初始化成0。此时,producer没有发送任何消息给leader,而follower已经开始不断地给leader发送FETCH请求了,但因为没有数据因此什么都不会发生。值得一提的是,follower发送过来的FETCH请求因为无数据而暂时会被寄存到leader端的purgatory中,待500ms(replica.fetch.wait.max.ms参数)超时后会强制完成。倘若在寄存期间producer端发送过来数据,那么会Kafka会自动唤醒该FETCH请求,让leader继续处理之。
虽然purgatory不是本文的重点,但FETCH请求发送和PRODUCE请求处理的时机会影响我们的讨论。因此后续我们也将分两种情况来讨论分区HW的更新。

第一种情况:follower发送FETCH请求在leader处理完PRODUCE请求之后
producer给该topic分区发送了一条消息。此时的状态如下图所示:
本例中当follower发送FETCH请求时,leader端的处理依次是:
- 读取底层log数据
- 更新remote LEO = 0(为什么是0? 因为此时follower还没有写入这条消息。leader如何确认follower还未写入呢?这是通过follower发来的FETCH请求中的fetch offset来确定的)
- 尝试更新分区HW——此时leader LEO = 1,remote LEO = 0,故分区HW值= min(leader LEO, follower remote LEO) = 0
- 把数据和当前分区HW值(依然是0)发送给follower副本
而follower副本接收到FETCH response后依次执行下列操作:
- 写入本地log(同时更新follower LEO)
- 更新follower HW——比较本地LEO和当前leader HW取小者,故follower HW = 0
此时,第一轮FETCH RPC结束,我们会发现虽然leader和follower都已经在log中保存了这条消息,但分区HW值尚未被更新。实际上,它是在第二轮FETCH RPC中被更新的,如下图所示:
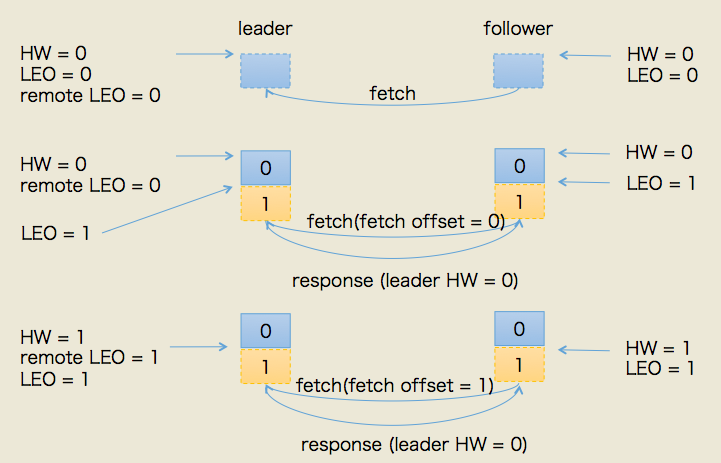
上图中,follower发来了第二轮FETCH请求,leader端接收到后仍然会依次执行下列操作:
- 读取底层log数据
- 更新remote LEO = 1(这次为什么是1了? 因为这轮FETCH RPC携带的fetch offset是1,那么为什么这轮携带的就是1了呢,因为上一轮结束后follower LEO被更新为1了)
- 尝试更新分区HW——此时leader LEO = 1,remote LEO = 1,故分区HW值= min(leader LEO, follower remote LEO) = 1。注意分区HW值此时被更新了!!!
- 把数据(实际上没有数据)和当前分区HW值(已更新为1)发送给follower副本
同样地,follower副本接收到FETCH response后依次执行下列操作:
- 写入本地log,当然没东西可写,故follower LEO也不会变化,依然是1
- 更新follower HW——比较本地LEO和当前leader HW取小者。由于此时两者都是1,故更新follower HW = 1 (**注意:我特意用了两种颜色来描述这两步,后续会谈到原因!**)
Okay,producer端发送消息后broker端完整的处理流程就讲完了。此时消息已经成功地被复制到leader和follower的log中且分区HW是1,表明consumer能够消费offset = 0的这条消息。下面我们来分析下PRODUCE和FETCH请求交互的第二种情况。
第二种情况:FETCH请求保存在purgatory中PRODUCE请求到来
这种情况实际上和第一种情况差不多。前面说过了,当leader无法立即满足FECTH返回要求的时候(比如没有数据),那么该FETCH请求会被暂存到leader端的purgatory中,待时机成熟时会尝试再次处理它。不过Kafka不会无限期地将其缓存着,默认有个超时时间(500ms),一旦超时时间已过,则这个请求会被强制完成。不过我们要讨论的场景是在寄存期间,producer发送PRODUCE请求从而使之满足了条件从而被唤醒。此时,leader端处理流程如下:
- leader写入本地log(同时自动更新leader LEO)
- 尝试唤醒在purgatory中寄存的FETCH请求
- 尝试更新分区HW
至于唤醒后的FETCH请求的处理与第一种情况完全一致,故这里不做详细展开了。
以上所有的东西其实就想说明一件事情:Kafka使用HW值来决定副本备份的进度,而HW值的更新通常需要额外一轮FETCH RPC才能完成,故而这种设计是有问题的。它们可能引起的问题包括:
- 备份数据丢失
- 备份数据不一致
我们一一分析下:
一、数据丢失
如前所述,使用HW值来确定备份进度时其值的更新是在下一轮RPC中完成的。现在翻到上面使用两种不同颜色标记的步骤处思考下, 如果follower副本在蓝色标记的第一步与紫色标记的第二步之间发生崩溃,那么就有可能造成数据的丢失。我们举个例子来看下。
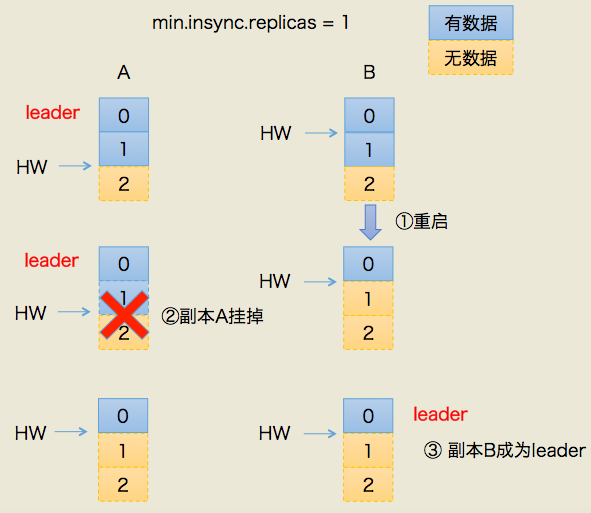
上图中有两个副本:A和B。开始状态是A是leader。我们假设producer端min.insync.replicas设置为1,那么当producer发送两条消息给A后,A写入到底层log,此时Kafka会通知producer说这两条消息写入成功。
但是在broker端,leader和follower底层的log虽都写入了2条消息且分区HW已经被更新到2,但follower HW尚未被更新(也就是上面紫色颜色标记的第二步尚未执行)。倘若此时副本B所在的broker宕机,那么重启回来后B会自动把LEO调整到之前的HW值,故副本B会做日志截断(log truncation),将offset = 1的那条消息从log中删除,并调整LEO = 1,此时follower副本底层log中就只有一条消息,即offset = 0的消息。
B重启之后需要给A发FETCH请求,但若A所在broker机器在此时宕机,那么Kafka会令B成为新的leader,而当A重启回来后也会执行日志截断,将HW调整回1(个人补充:这里应该是刚开始是2,但是通过同步请求后,每次取最小值,所以HW变成了1)。这样,位移=1的消息就从两个副本的log中被删除,即永远地丢失了。
这个场景丢失数据的前提是在min.insync.replicas=1时,一旦消息被写入leader端log即被认为是“已提交”,而延迟一轮FETCH RPC更新HW值的设计使得follower HW值是异步延迟更新的,倘若在这个过程中leader发生变更,那么成为新leader的follower的HW值就有可能是过期的,使得clients端认为是成功提交的消息被删除。
二、leader/follower数据离散
除了可能造成的数据丢失以外,这种设计还有一个潜在的问题,即造成leader端log和follower端log的数据不一致。比如leader端保存的记录序列是r1,r2,r3,r4,r5,….;而follower端保存的序列可能是r1,r3,r4,r5,r6…。这也是非法的场景,因为顾名思义,follower必须追随leader,完整地备份leader端的数据。
我们依然使用一张图来说明这种场景是如何发生的: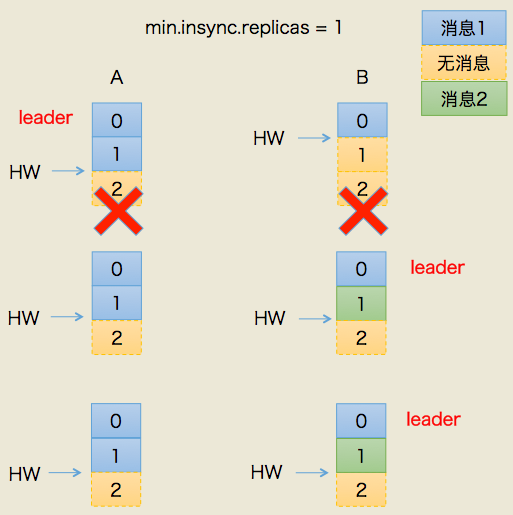
这种情况的初始状态与情况1有一些不同的:A依然是leader,A的log写入了2条消息,但B的log只写入了1条消息。分区HW更新到2,但B的HW还是1,同时producer端的min.insync.replicas = 1。
这次我们让A和B所在机器同时挂掉,然后假设B先重启回来,因此成为leader,分区HW = 1。假设此时producer发送了第3条消息(绿色框表示)给B,于是B的log中offset = 1的消息变成了绿色框表示的消息,同时分区HW更新到2(A还没有回来,就B一个副本,故可以直接更新HW而不用理会A)之后A重启回来,需要执行日志截断,但发现此时分区HW=2而A之前的HW值也是2,故不做任何调整。此后A和B将以这种状态继续正常工作。
显然,这种场景下,A和B底层log中保存在offset = 1的消息是不同的记录,从而引发不一致的情形出现。
Kafka 0.11.0.0.版本解决方案
造成上述两个问题的根本原因在于HW值被用于衡量副本备份的成功与否以及在出现failture时作为日志截断的依据,但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中间发生的任何崩溃都可能导致HW值的过期。鉴于这些原因,Kafka 0.11引入了leader epoch来取代HW值。Leader端多开辟一段内存区域专门保存leader的epoch信息,这样即使出现上面的两个场景也能很好地规避这些问题。
所谓leader epoch实际上是一对值:(epoch,offset)。epoch表示leader的版本号,从0开始,当leader变更过1次时epoch就会+1,而offset则对应于该epoch版本的leader写入第一条消息的位移。因此假设有两对值:
(0, 0)
(1, 120)
则表示第一个leader从位移0开始写入消息;共写了120条[0, 119];而第二个leader版本号是1,从位移120处开始写入消息。
leader broker中会保存这样的一个缓存,并定期地写入到一个checkpoint文件中。
当leader写底层log时它会尝试更新整个缓存——如果这个leader首次写消息,则会在缓存中增加一个条目;否则就不做更新。而每次副本重新成为leader时会查询这部分缓存,获取出对应leader版本的位移,这就不会发生数据不一致和丢失的情况。
下面我们依然使用图的方式来说明下利用leader epoch如何规避上述两种情况
一、规避数据丢失
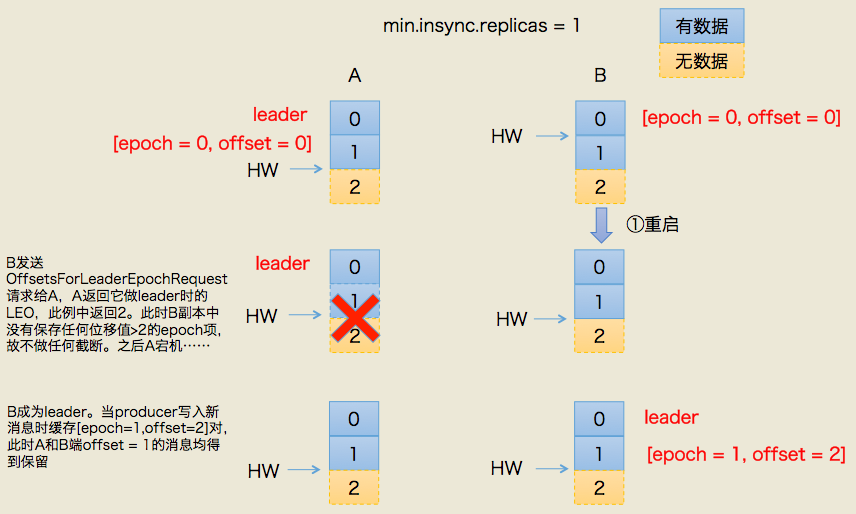
上图左半边已经给出了简要的流程描述,这里不详细展开具体的leader epoch实现细节(比如OffsetsForLeaderEpochRequest的实现),我们只需要知道每个副本都引入了新的状态来保存自己当leader时开始写入的第一条消息的offset以及leader版本。这样在恢复的时候完全使用这些信息而非水位来判断是否需要截断日志。
二、规避数据不一致
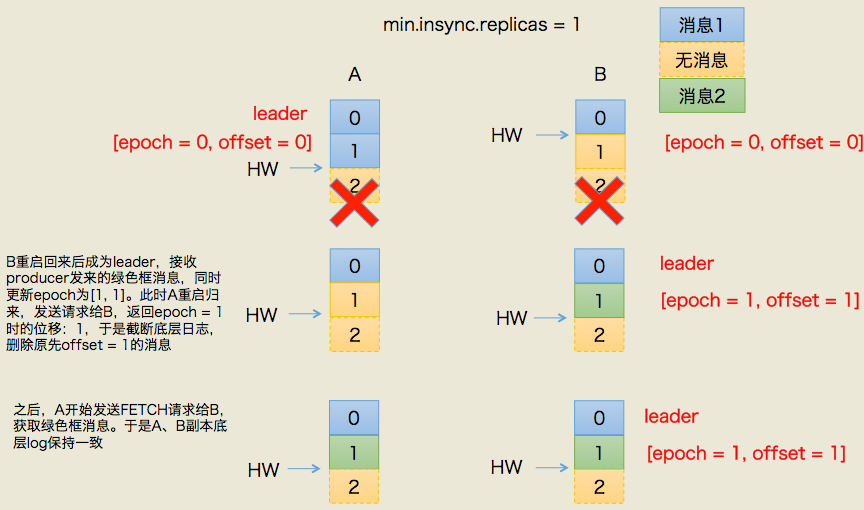
同样的道理,依靠leader epoch的信息可以有效地规避数据不一致的问题。
总结
0.11.0.0版本的Kafka通过引入leader epoch解决了原先依赖水位表示副本进度可能造成的数据丢失/数据不一致问题。有兴趣的读者可以阅读源代码进一步地了解其中的工作原理。
源代码位置:kafka.server.epoch.LeaderEpochCache.scala (leader epoch数据结构)、kafka.server.checkpoints.LeaderEpochCheckpointFile(checkpoint检查点文件操作类)还有分布在Log中的CRUD操作。
上述副本备份机制转载至:https://www.cnblogs.com/huxi2b/p/7453543.html
作者:huxihx
补充说明leader epoch:
场景和之前大致是类似的,只不过引用 Leader Epoch 机制后,Follower 副本 B 重启回来后,需要向 A 发送一个特殊的请求去获取 Leader 的 LEO 值。在这个例子中,该值为 2。当获知到 Leader LEO=2 后,B 发现该 LEO 值不比它自己的 LEO 值小,而且缓存中也没有保存任何起始位移值 > 2 的 Epoch 条目,因此 B 无需执行任何日志截断操作。这是对高水位机制的一个明显改进,即副本是否执行日志截断不再依赖于高水位进行判断。
现在,副本 A 宕机了,B 成为 Leader。同样地,当 A 重启回来后,执行与 B 相同的逻辑判断,发现也不用执行日志截断,至此位移值为 1 的那条消息在两个副本中均得到保留。后面当生产者程序向 B 写入新消息时,副本 B 所在的 Broker 缓存中,会生成新的 Leader Epoch 条目:[Epoch=1, Offset=2]。之后,副本 B 会使用这个条目帮助判断后续是否执行日志截断操作。这样,通过 Leader Epoch 机制,Kafka 完美地规避了这种数据丢失场景。
6.2.7 Partition复制集与Producer
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;生产者可以选择等待消息提交或不提交,这取决于他们对延迟和持久性之间权衡的偏好。此首选项由生产者使用的 acks 设置控制。请注意,主题具有同步副本的“最小数量”设置,当生产者请求确认消息已写入完整的同步副本集时,会检查该设置。
如果需要等待ack则为同步,如果不需要等待所有follower复制完成即回传ack则为异步模式。
同步复制:
1.producer联系zk识别leader
2.向leader发送消息
3.leadr收到消息写入到本地log
4.follower从leader pull消息
5.follower向本地写入log
6.follower向leader发送ack消息
7.leader收到所有follower的ack消息
8.leader向producer回传ack
异步复制:
和同步复制的区别在于,leader写入本地log之后,
直接向client回传ack消息,不需要等待所有follower复制完成。
作者:可期 链接:https://www.zhihu.com/question/266390197/answer/772404605 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
producer保证分区消息的有序性
消息重试对顺序消息的影响
对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了。 这时对于本身顺序为AB的消息顺序变成了BA
消息producer发送逻辑的控制
消息producer在发送消息的时候,对于同一个broker连接是存在多个未确认的消息在同时发送的,也就是存在上面场景说到的情况,虽然A和B消息是顺序的,但是由于存在未知的确认关系,有可能存在A发送失败,B发送成功,A需要重试的时候顺序关系就变成了BA。简之一句就是在发送B时A的发送状态是未知的。 针对以上的问题,严格的顺序消费还需要以下参数支持:max.in.flight.requests.per.connection 这个参数官方文档的解释是:
在发送阻塞前对于每个连接,正在发送但是发送状态未知的最大消息数量。如果设置大于1,那么就有可能存在有发送失败的情况下,因为重试发送导致的消息乱序问题。 所以我们应该将其设置为1,保证在后一条消息发送前,前一条的消息状态已经是可知的。
7. kafka中的Zookeeper
7.1. Zookeeper概念
在介绍ZooKeeper之前,先来介绍一下分布式协调技术,所谓分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成资源竞争的后果。
目前,在分布式协调技术方面做得比较好的有Google的Chubby,还有Apache的ZooKeeper,它们都是分布式锁的实现者。ZooKeeper所提供锁服务在分布式领域久经考验,它的可靠性、可用性都是经过理论和实践验证的。
ZooKeeper是一种为分布式应用所设计的高可用、高性能的开源协调服务,它提供了一项基本服务:分布式锁服务,同时,也提供了数据的维护和管理机制,如:统一命名服务、状态同步服务、集群管理、分布式消息队列、分布式应用配置项的管理等等。
7.2. Zookeeper设计
ZooKeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
关于ZooKeeper这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家RaghuRamakrishnan开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧 一一 因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而ZooKeeper正好要用来进行分布式环境的协调。于是,ZooKeeper的名字也就由此诞生了。
Apache ZooKeeper 是一个提供高可靠性的分布式协调服务框架。它使用的数据模型类似于文件系统的树形结构,根目录也是以“/”开始。该结构上的每个节点被称为 znode,用来保存一些元数据协调信息。
如果以 znode 持久性来划分,znode 可分为持久性 znode 和临时 znode。持久性 znode 不会因为 ZooKeeper 集群重启而消失,而临时 znode 则与创建该 znode 的 ZooKeeper 会话绑定,一旦会话结束,该节点会被自动删除。
ZooKeeper 赋予客户端监控 znode 变更的能力,即所谓的 Watch 通知功能。一旦 znode 节点被创建、删除,子节点数量发生变化,抑或是 znode 所存的数据本身变更,ZooKeeper 会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端。
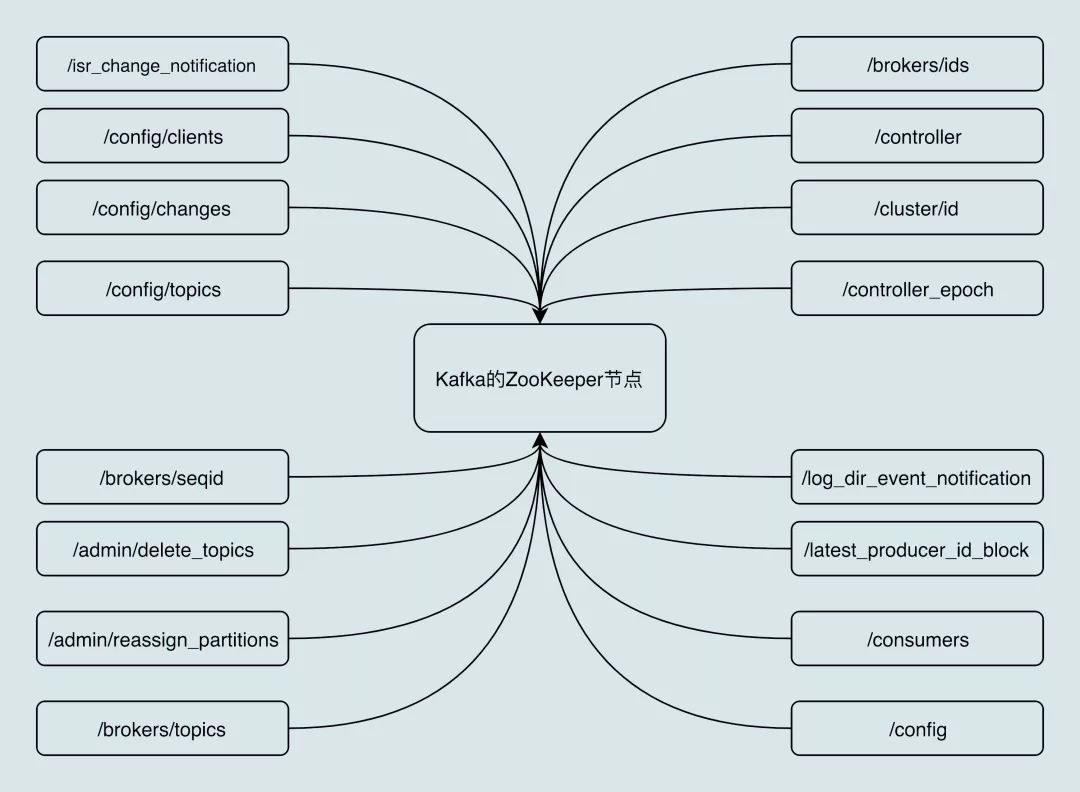
依托于这些功能,ZooKeeper 常被用来实现集群成员管理、分布式锁、领导者选举等功能。Kafka 控制器大量使用 Watch 功能实现对集群的协调管理。我们一起来看一张图片,它展示的是 Kafka 在 ZooKeeper 中创建的 znode 分布。你不用了解每个 znode 的作用,但你可以大致体会下 Kafka 对 ZooKeeper 的依赖。
7.3. Zookeeper安装建议
在操作上,我们为健康的 ZooKeeper 安装执行以下操作:
- 物理/硬件/网络布局中的冗余:尽量不要将它们全部放在同一个机架中,体面(但不要发疯)硬件,尽量保留冗余电源和网络路径等。典型的 ZooKeeper 集成有 5 个或7 台服务器,分别可容忍 2 台和 3 台服务器停机。如果您的部署规模较小,则可以使用 3 台服务器,但请记住,在这种情况下,您只能容忍 1 台服务器停机。
- I/O 隔离:如果您执行大量写入类型的流量,您几乎肯定希望将事务日志放在专用磁盘组上。对事务日志的写入是同步的(但为了性能而进行批处理),因此,并发写入会显着影响性能。ZooKeeper 快照可以作为并发写入的来源之一,理想情况下应该写入与事务日志分开的磁盘组。快照以异步方式写入磁盘,因此通常可以与操作系统和消息日志文件共享。您可以将服务器配置为使用带有 dataLogDir 参数的单独磁盘组。
- 应用程序隔离:除非您真正了解要安装在同一台机器上的其他应用程序的应用程序模式,否则单独运行 ZooKeeper 可能是一个好主意(尽管这可能是与硬件功能的平衡行为)。
- 谨慎使用虚拟化:它可以工作,具体取决于您的集群布局、读/写模式和 SLA,但虚拟化层引入的微小开销可能会累加并抛弃 ZooKeeper,因为它可能对时间非常敏感
- ZooKeeper 配置:它是 java,确保你给它“足够”的堆空间(我们通常用 3-5G 运行它们,但这主要是由于我们这里的数据集大小)。不幸的是,我们没有一个好的公式,但请记住,允许更多的 ZooKeeper 状态意味着快照可能会变大,而大快照会影响恢复时间。事实上,如果快照变得太大(几 GB),那么您可能需要增加 initLimit 参数,以便为服务器提供足够的时间来恢复并加入整体。
- 监控:JMX 和 4 字母单词 (4lw) 命令都非常有用,它们在某些情况下确实重叠(在这些情况下,我们更喜欢 4 字母命令,它们似乎更可预测,或者至少,它们与LI 监控基础设施)
- 不要过度构建集群:大型集群,尤其是在写入大量使用模式中,意味着大量集群内通信(写入和后续集群成员更新的仲裁),但不要构建不足(并且有淹没集群的风险)。拥有更多服务器会增加您的读取能力。
总的来说,我们尽量让 ZooKeeper 系统尽可能小,以处理负载(加上标准的增长容量规划),并尽可能简单。与官方版本相比,我们尽量不对配置或应用程序布局做任何花哨的事情,并尽可能保持其自包含。由于这些原因,我们倾向于跳过 OS 打包版本,因为它倾向于尝试将事物放在 OS 标准层次结构中,这可能是“混乱”的,因为需要更好的表达方式。
当 ZooKeeper 单独与 Kafka 一起工作时,它不是内存密集型的。 对于大多数用例,大约 8 GB 的 RAM 就足够了。
与内存非常相似,ZooKeeper 不会大量消耗 CPU 资源。但是,最佳做法是为 ZooKeeper提供专用的 CPU 内核,以确保上下文切换不会出现问题。
最后,磁盘性能对于 ZooKeeper 至关重要。由于 ZooKeeper 需要低延迟磁盘写入,我们建议使用**固态驱动器 (SSD)**。
社区讨论的对Zookeeper的优化:
ZooKeeper 本身的 API 提供了同步写和异步写两种方式。之前控制器操作 ZooKeeper 使用的是同步的 API,性能很差,集中表现为,当有大量主题分区发生变更时,ZooKeeper 容易成为系统的瓶颈。新版本 Kafka 修改了这部分设计,完全摒弃了之前的同步 API 调用,转而采用异步 API 写入 ZooKeeper,性能有了很大的提升。根据社区的测试,改成异步之后,ZooKeeper 写入提升了 10 倍!
将所有同步操作Zookeeper的地方都改成异步调用+回调的方式。实际上Apache Zookeeper客户端执行请求的方式有三种:同步、异步和batch。通常以batch性能最好,但Kafka社区目前还是倾向于用async替换sync。毕竟实现起来相对简单同时性能上也能得到不少提升。
ZkClient是同步顺序处理ZK事件的,而原生Zookeeper client支持async方式。另外使用原生API还能够在接收到状态变更通知时便马上开始处理,而ZkClient的特定线程则必须要在队列中顺序处理到这条变更消息时才能处理。
7.4. Zookeeper配置
1 | 存储快照的目录。 |
7.5. Zookeeper工作
7.5.1. Broker注册
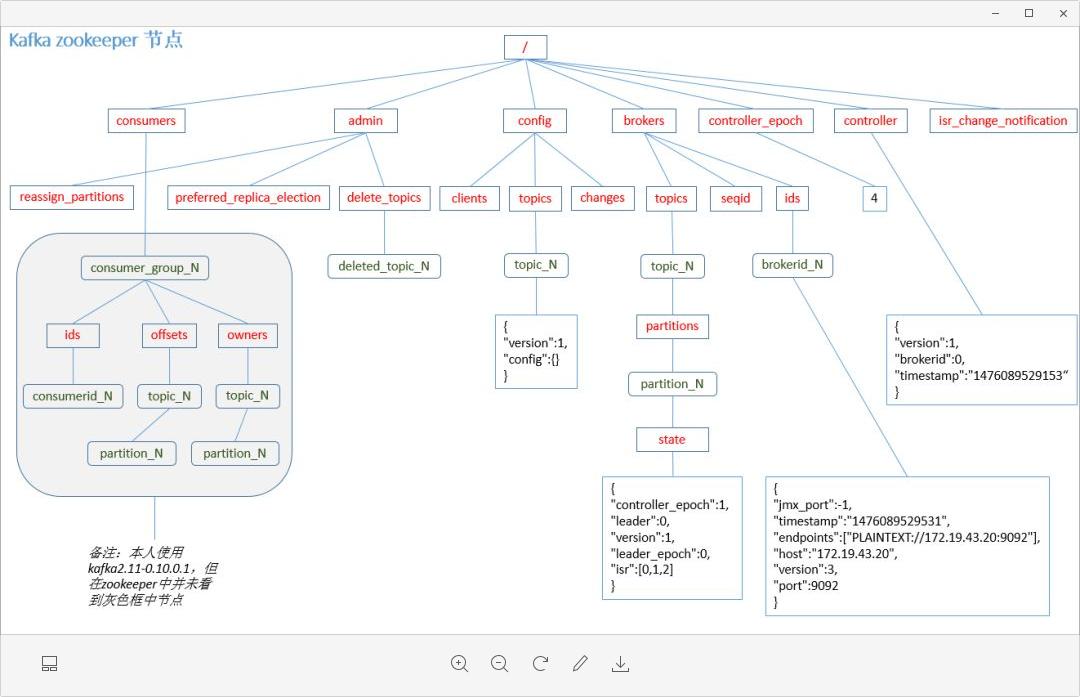
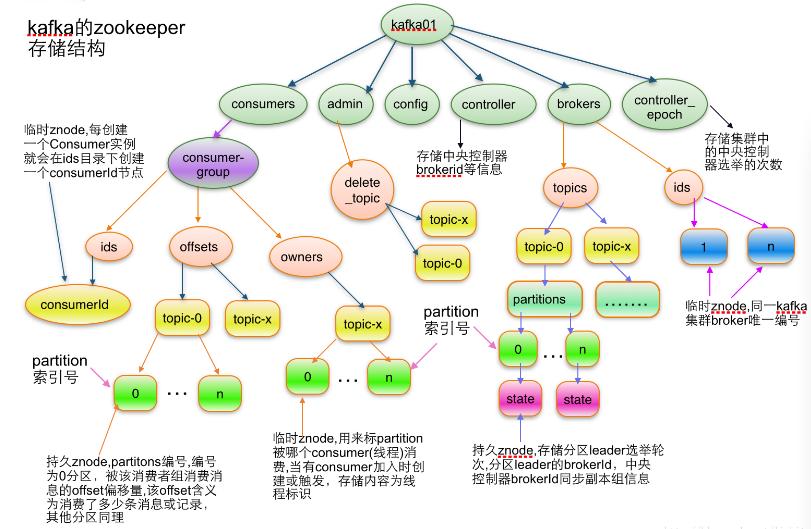
Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。在Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点:
/brokers/ids
每个Broker在启动时,都会到Zookeeper上进行注册,即到/brokers/ids下创建属于自己的节点,如/brokers/ids/[0…N]。
Kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册,创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。其中,Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
7.5.2. Topic注册
在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录,如:
/borkers/topics
Kafka中每个Topic都会以/brokers/topics/[topic]的形式被记录,如/brokers/topics/login和/brokers/topics/search等。Broker服务器启动后,会到对应Topic节点(/brokers/topics)上注册自己的Broker ID并写入针对该Topic的分区总数,如/brokers/topics/login/3->2,这个节点表示Broker ID为3的一个Broker服务器,对于”login”这个Topic的消息,提供了2个分区进行消息存储,同样,这个分区节点也是临时节点。

7.5.3. 生产者负载均衡
由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上,那么如何实现生产者的负载均衡,Kafka支持传统的四层负载均衡,也支持Zookeeper方式实现负载均衡。
(1) 四层负载均衡,根据生产者的IP地址和端口来为其确定一个相关联的Broker。通常,一个生产者只会对应单个Broker,然后该生产者产生的消息都发往该Broker。这种方式逻辑简单,每个生产者不需要同其他系统建立额外的TCP连接,只需要和Broker维护单个TCP连接即可。但是,其无法做到真正的负载均衡,因为实际系统中的每个生产者产生的消息量及每个Broker的消息存储量都是不一样的,如果有些生产者产生的消息远多于其他生产者的话,那么会导致不同的Broker接收到的消息总数差异巨大,同时,生产者也无法实时感知到Broker的新增和删除。
(2) 使用Zookeeper进行负载均衡,由于每个Broker启动时,都会完成Broker注册过程,生产者会通过该节点的变化来动态地感知到Broker服务器列表的变更,这样就可以实现动态的负载均衡机制。
7.5.4. 消费者注册
消费者服务器在初始化启动时加入消费者分组的步骤如下
注册到消费者分组。每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点,例如/consumers/[group_id]/ids/[consumer_id],完成节点创建后,消费者就会将自己订阅的Topic信息写入该临时节点。
对消费者分组中的消费者的变化注册监听。每个 消费者都需要关注所属消费者分组中其他消费者服务器的变化情况,即对/consumers/[group_id]/ids节点注册子节点变化的Watcher监听,一旦发现消费者新增或减少,就触发消费者的负载均衡。
对Broker服务器变化注册监听。消费者需要对/broker/ids/[0-N]中的节点进行监听,如果发现Broker服务器列表发生变化,那么就根据具体情况来决定是否需要进行消费者负载均衡。
进行消费者负载均衡。为了让同一个Topic下不同分区的消息尽量均衡地被多个消费者消费而进行消费者与消息分区分配的过程,通常,对于一个消费者分组,如果组内的消费者服务器发生变更或Broker服务器发生变更,会发出消费者负载均衡。
7.5.5. 消费者负载均衡
与生产者类似,Kafka中的消费者同样需要进行负载均衡来实现多个消费者合理地从对应的Broker服务器上接收消息,每个消费者分组包含若干消费者,每条消息都只会发送给分组中的一个消费者,不同的消费者分组消费自己特定的Topic下面的消息,互不干扰。
7.5.6. 分区 与 消费者 的关系
消费组 (Consumer Group): consumer group 下有多个 Consumer(消费者)。 对于每个消费者组 (Consumer Group),Kafka都会为其分配一个全局唯一的Group ID,Group 内部的所有消费者共享该 ID。订阅的topic下的每个分区只能分配给某个 group 下的一个consumer(当然该分区还可以被分配给其他group)。 同时,Kafka为每个消费者分配一个Consumer ID,通常采用”Hostname:UUID”形式表示。
在Kafka中,规定了每个消息分区 只能被同组的一个消费者进行消费,因此,需要在 Zookeeper 上记录 消息分区 与 Consumer 之间的关系,每个消费者一旦确定了对一个消息分区的消费权力,需要将其Consumer ID 写入到 Zookeeper 对应消息分区的临时节点上,例如:
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]
其中,[broker_id-partition_id]就是一个 消息分区 的标识,节点内容就是该 消息分区 上 消费者的Consumer ID。
7.5.7. 消息消费进度Offset 记录(0.9版本及之前)
在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度Offset记录到Zookeeper上,以便在该消费者进行重启或者其他消费者重新接管该消息分区的消息消费后,能够从之前的进度开始继续进行消息消费。Offset在Zookeeper中由一个专门节点进行记录,其节点路径为:
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]
节点内容就是Offset的值。
作者:博弈史密斯 链接:https://www.jianshu.com/p/a036405f989c
7.7. Zookeeper作用
7.7.1. 数据发布与订阅(配置中心)
发布与订阅模型,即所谓的配置中心,顾名思义就是讲发布者将数据发布到zk节点上,共订阅者动态获取数据,实现配置的集中式管理和动态更新。例如,全局的配置信息,服务服务框架的地址列表就非常适合使用。Topic的配置之所以能动态更新就是基于zookeeper做了一个动态全局配置管理。
7.7.2. 负载均衡
即软件负载均衡。最典型的是消息中间件的生产、消费者负载均衡。基于zookeeper的消费者,实现了该特性,动态的感知分区变动,将负载使用既定策略分不到消费者身上。
7.7.3. 命名服务(Naming Service)
常见的是发布者将自己的地址列表写到zookeeper的节点上,然后订阅者可以从固定名称的节点获取地址列表,链接到发布者进行相关通讯。Broker将advertised.port和advertised.host.name,这两个配置发布到zookeeper上的zookeeper的节点上/brokers/ids/BrokerId(broker.id),这个是供生产者,消费者,其它Broker跟其建立连接用的。
7.7.4. 分布式通知/协调
这个利用的是zookeeper的watcher注册和异步通知机制,能够很好的实现分布式环境中不同系统间的通知与协调,实现对数据变更的实时处理。比如分区增加,topic变动,Broker上线下线等均是基于zookeeper来实现的分布式通知。
7.7.5. 集群管理与Master选举
集群管理,比如在线率,节点上线下线通知这些。Master选举可以使用临时顺序节点来实现。
我们可以在通过命令行,对kafka集群上的topic partition分布,进行迁移管理,也可以对partition leader选举进行干预。
Master选举,要说有也是违反常规,常规的master选举,是基于临时顺序节点来实现的,序列号最小的作为master。而kafka的Controller的选举是基于临时节点来实现的,临时节点创建成功的成为Controller,更像一个独占锁服务。
7.7.6. 分布式锁
分布式锁,这个主要得益于zookeeper数据的强一致性,利用的是临时节点。锁服务分为两类,一个是独占锁,另一个是控制时序。
独占,是指所有的客户端都来获取这把锁,最终只能有一个获取到。用的是临时节点。用于Controller的选举。
控制时序,所有来获取锁的客户端,都会被安排得到锁,只不过要有个顺序。实际上是某个节点下的临时顺序子节点来实现的。
7.7.7. 分布式队列
一种是FIFO,这个就是使用临时顺序节点实现的,和分布式锁服务控制时序一样。
第二种是等待队列的成员聚齐之后的才同意按序执行。实际上,是在队列的节点里首先创建一个/queue/num节点,并且赋值队列的大小。这样我们可以通过监控队列节点子节点的变动来感知队列是否已满或者条件已经满足执行的需要。这种,应用场景是有条件执行的任务,条件齐备了之后任务才能执行。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中。从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
早期版本的 kafka 用 zk 做 meta 信息存储,consumer 的消费状态,group 的管理以及 offse t的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中确实逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖。
7.8 Zookeeper的不足
在之前的版本中,如果没有 ZooKeeper,Kafka 将无法运行。但管理部署两个不同的系统不仅让运维复杂度翻倍,还让 Kafka 变得沉重,进而限制了 Kafka 在轻量环境下的应用,同时 ZooKeeper 的分区特性也限制了 Kafka 的承载能力。
ZooKeeper 是 Hadoop 的一个子项目,一般用来管理较大规模、结构复杂的服务器集群,具有自己的配置文件语法、管理工具和部署模式。Kafka 最初由 LinkedIn 开发,随后于 2011 年初开源,2014 年由主创人员组建企业 Confluent。
Broker 是 Kafka 集群的骨干,负责从生产者(producer)到消费者(consumer)的接收、存储和发送消息。在当前架构下,Kafka 进程在启动的时候需要往 ZooKeeper 集群中注册一些信息,比如 BrokerId,并组建集群。ZooKeeper 为 Kafka 提供了可靠的元数据存储,比如 Topic/分区的元数据、Broker 数据、ACL 信息等等。
同时 ZooKeeper 充当 Kafka 的领导者,以更新集群中的拓扑更改;根据 ZooKeeper 提供的通知,生产者和消费者发现整个 Kafka 集群中是否存在任何新 Broker 或 Broker 失败。大多数的运维操作,比如说扩容、分区迁移等等,都需要和 ZooKeeper 交互。
也就是说,Kafka 代码库中有很大一部分是负责实现在集群中多个 Broker 之间分配分区(即日志)、分配领导权、处理故障等分布式系统的功能。而早已经过业界广泛使用和验证过的 ZooKeeper 是分布式代码工作的关键部分。
假设没有 ZooKeeper 的话,Kafka 甚至无法启动进程。腾讯云中间件-微服务产品中心技术总监韩欣对 InfoQ 说,“在以前的版本中,ZooKeeper 可以说是 Kafka 集群的灵魂。”
但严重依赖 ZooKeeper,也给 Kafka 带来了掣肘。Kafka 一路发展过来,绕不开的两个话题就是集群运维的复杂度以及单集群可承载的分区规模,韩欣表示,比如腾讯云 Kafka 维护了上万节点的 Kafka 集群,主要遇到的问题也还是这两个。
首先从集群运维的角度来看,Kafka 本身就是一个分布式系统。但它又依赖另一个开源的分布式系统,而这个系统又是 Kafka 系统本身的核心。这就要求集群的研发和维护人员需要同时了解这两个开源系统,需要对其运行原理以及日常的运维(比如参数配置、扩缩容、监控告警等)都有足够的了解和运营经验。否则在集群出现问题的时候无法恢复,是不可接受的。所以,ZooKeeper 的存在增加了运维的成本。
其次从集群规模的角度来看,限制 Kafka 集群规模的一个核心指标就是集群可承载的分区数。集群的分区数对集群的影响主要有两点:ZooKeeper 上存储的元数据量和控制器变动效率。
Kafka 集群依赖于一个单一的 Controller 节点来处理绝大多数的 ZooKeeper 读写和运维操作,并在本地缓存所有 ZooKeeper 上的元数据。分区数增加,ZooKeeper 上需要存储的元数据就会增加,从而加大 ZooKeeper 的负载,给 ZooKeeper 集群带来压力,可能导致 Watch 的延时或丢失。
当 Controller 节点出现变动时,需要进行 Leader 切换、Controller 节点重新选举等行为,分区数越多需要进行越多的 ZooKeeper 操作:比如当一个 Kafka 节点关闭的时候,Controller 需要通过写 ZooKeeper 将这个节点的所有 Leader 分区迁移到其他节点;新的 Controller 节点启动时,首先需要将所有 ZooKeeper 上的元数据读进本地缓存,分区越多,数据量越多,故障恢复耗时也就越长。
Kafka 单集群可承载的分区数量对于一些业务来说,又特别重要。韩欣举例补充道,“腾讯云 Kafka 主要为公有云用户以及公司内部业务提供服务。我们遇到了很多需要支持百万分区的用户,比如腾讯云 Serverless、腾讯云的 CLS 日志服务、云上的一些客户等,他们面临的场景是一个客户需要一个 topic 来进行业务逻辑处理,当用户量达到百万千万量级的情况下,topic 带来的膨胀是非常恐怖的。在当前架构下,Kafka 单集群无法稳定承载百万分区稳定运行。这也是我对新的 KIP-500 版本感到非常兴奋的原因。”
转载至:https://www.infoq.cn/article/phf3gfjutdhwmctg6kxe
作者:Tina
从 2019 年起,Confluent 就开始策划更换掉 ZooKeeper。这是一项相当大的工程,经过九个多月的开发,KIP-500 代码的早期访问已经提交到 trunk 中。
第一次,用户可以在没有 ZooKeeper 的情况下运行 Kafka。
这是一次架构上的重大升级,让一向“重量级”的 Kafka 从此变得简单了起来。轻量级的单进程部署可以作为 ActiveMQ 或 RabbitMQ 等的替代方案,同时也适合于边缘场景和使用轻量级硬件的场景。
Zookeeper的后续改进
ZooKeeper 本身的 API 提供了同步写和异步写两种方式。之前控制器操作 ZooKeeper 使用的是同步的 API,性能很差,集中表现为,当有大量主题分区发生变更时,ZooKeeper 容易成为系统的瓶颈。新版本 Kafka 修改了这部分设计,完全摒弃了之前的同步 API 调用,转而采用异步 API 写入 ZooKeeper,性能有了很大的提升。根据社区的测试,改成异步之后,ZooKeeper 写入提升了 10 倍!
Apache Kafka 变得简单:没有 ZooKeeper 的 Kafka 的第一次
仲裁控制器:事件驱动的共识
如果您选择使用新的仲裁控制器运行 Kafka,那么之前由 Kafka 控制器和 ZooKeeper 承担的所有元数据职责都将合并到这一新服务中,在 Kafka 集群本身内部运行。如果您有需要它的用例,仲裁控制器也可以在专用硬件上运行。
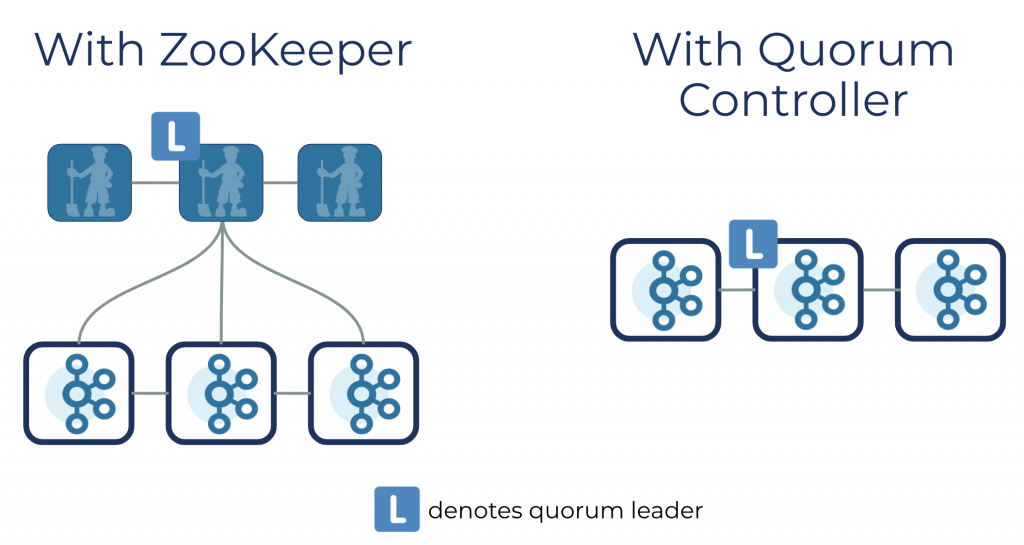
Kafka 集群可以支持的分区数量由两个属性决定:每个节点的分区计数限制和集群范围的分区限制。两者都很有趣,但迄今为止,元数据管理一直是集群范围限制的主要瓶颈。之前的 Kafka 改进提案 (KIP) 已经改进了每个节点的限制,尽管总是有更多的事情可以做。但是 Kafka 的可扩展性主要取决于添加节点以获得更多容量。这就是集群范围限制变得重要的地方,因为它定义了系统内可伸缩性的上限。
新的仲裁控制器旨在处理每个集群的大量分区。为了评估这一点,我们进行了与之前在 2018 年运行的测试类似的测试,以宣传Kafka 的固有分区限制。这些测试测量关闭和恢复所用的时间,这是旧控制器的 O(#partitions) 操作。正是这一操作为 Kafka 目前在单个集群中可以支持的分区数量设置了上限。
正如 Jun Rao 在上面引用的帖子中解释的那样,之前的实现可以实现 200K 分区,限制因素是在外部共识(ZooKeeper)和内部领导者管理(Kafka 控制器)之间移动关键元数据所需的时间。使用新的仲裁控制器,这两个角色都由同一个组件提供服务。事件驱动的方法意味着控制器故障转移现在几乎是即时的。以下是在我们的实验室中执行的运行 200 万个分区(是之前上限的 10 倍)的集群的汇总数字:
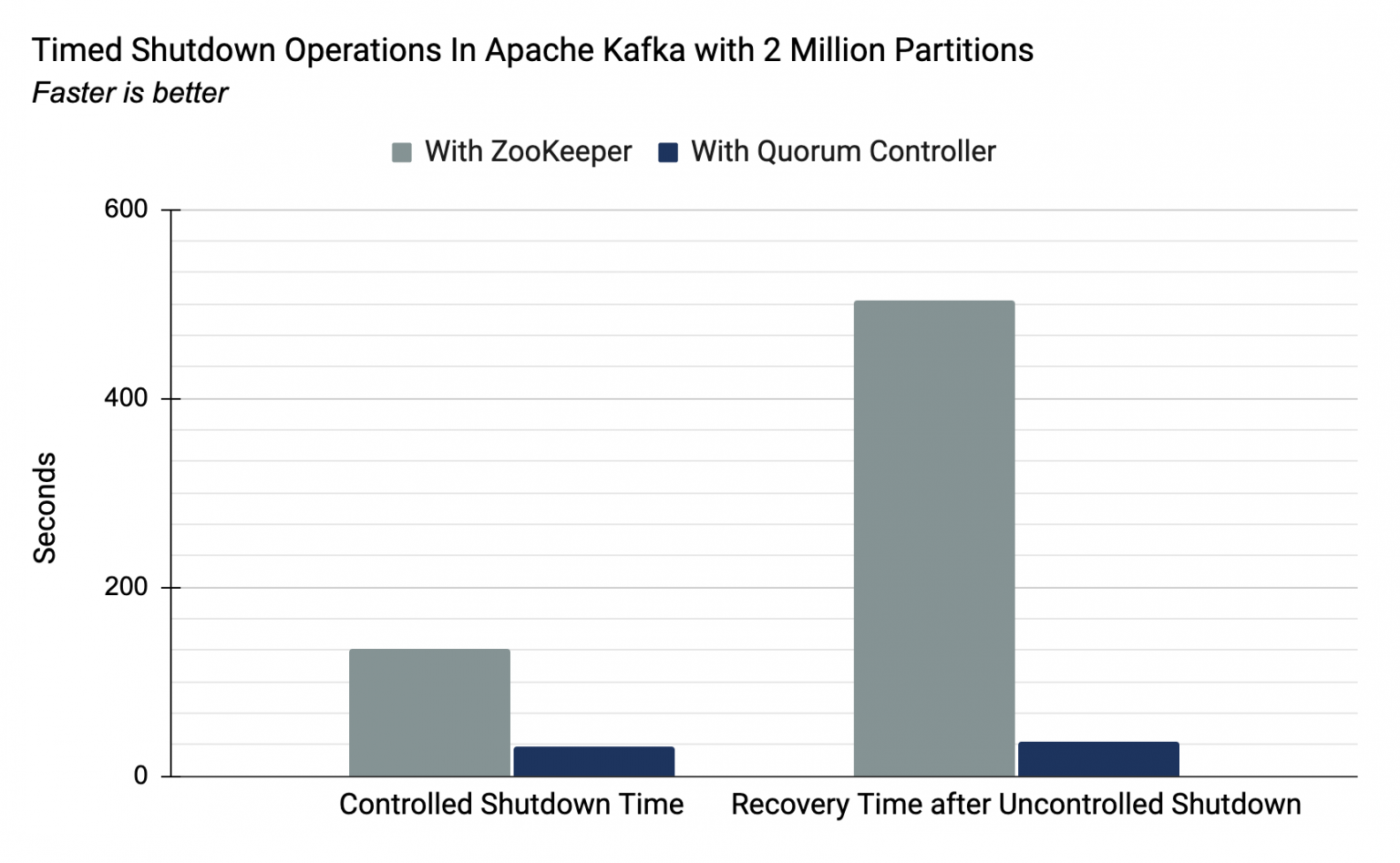
| 使用基于 ZooKeeper 的控制器 | 使用仲裁控制器 | |
|---|---|---|
| 受控关机时间 (200 万个分区) | 135 秒 | 32 秒。 |
| 从不受控制的关机中恢复(200 万个分区) | 503 秒 | 37 秒。 |
转发至:https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/
作者:ISMAEL JUMA, BEN STOPFORD
7.9 Zookeeper的补充
ZooKeeper 有五个主要功能。具体来说,ZooKeeper 用于控制器选举、集群成员、主题配置、访问控制列表和配额。
控制器选举。 控制器是负责维护所有分区的领导者/追随者关系的代理。如果某个节点关闭,ZooKeeper 会确保其他副本扮演分区领导者的角色,替换正在关闭的节点中的分区领导者。
集群成员资格。 ZooKeeper 保存集群中所有功能代理的列表。
主题配置。 ZooKeeper 维护所有主题的配置,包括现有主题列表、每个主题的分区数、副本的位置、主题的配置覆盖、首选领导节点等详细信息。
**访问控制列表 (ACL)**。 ZooKeeper 还维护所有主题的 ACL。这包括允许谁或什么可以读/写每个主题、消费者组列表、组成员以及每个消费者组从每个分区收到的最近偏移量。
配额。 ZooKeeper 访问每个客户端允许读/写的数据量。
ZooKeeper 以其可靠性、简单性、速度和可扩展性而闻名。
可靠性。 即使节点发生故障,ZooKeeper 也会继续工作。
简单。 ZooKeeper 的架构很简单,有一个共享的分层命名空间,有助于协调进程。
速度。 ZooKeeper 以其对需要读多于写的工作负载的快速处理而闻名,例如读取主导的工作负载。
可扩展性。 ZooKeeper 是水平可扩展的,这意味着它可以通过简单地添加额外节点来扩展。
转载于:https://dattell.com/data-architecture-blog/what-is-zookeeper-how-does-it-support-kafka/
作者:dattell
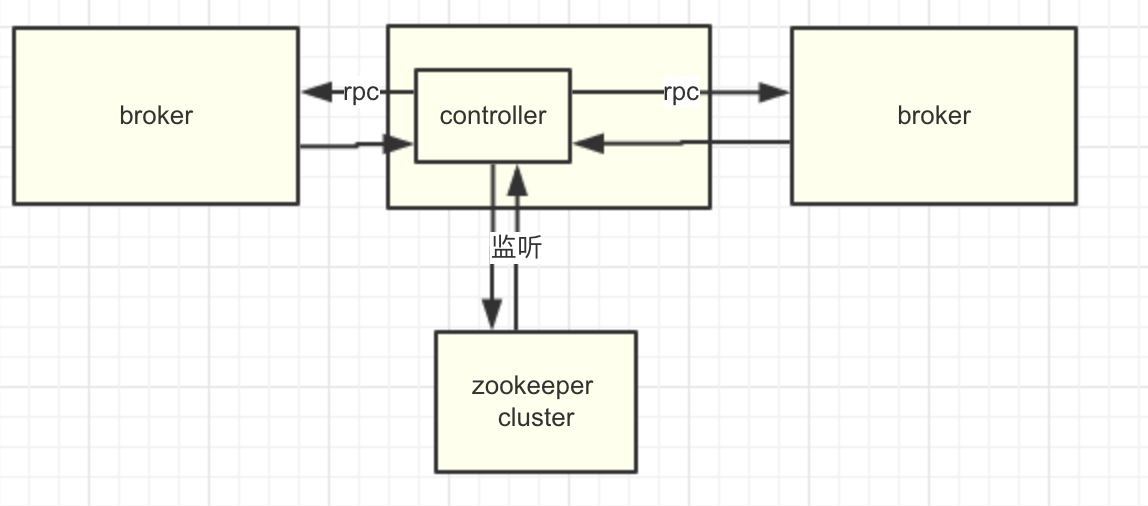
8. kafka的Controller
8.1. Controller概念
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责分区的重新分配。 Kafka中的控制器选举的工作依赖于Zookeeper,成功竞选为控制器的broker会在Zookeeper中创建/controller这个临时(EPHEMERAL)节点。此临时节点的内容参考如下:
1 | {"version":1,"brokerid":0,"timestamp":"1529210278988"} |
其中version在目前版本中固定为1,brokerid表示称为控制器的broker的id编号,timestamp表示竞选称为控制器时的时间戳。
8.2. Controller设计
控制器组件(Controller),是 Apache Kafka 的核心组件。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。
在任意时刻,集群中有且仅有一个控制器。每个broker启动的时候会去尝试去读取/controller节点的brokerid的值,如果读取到brokerid的值不为-1,则表示已经有其它broker节点成功竞选为控制器,所以当前broker就会放弃竞选;如果Zookeeper中不存在/controller这个节点,或者这个节点中的数据异常,那么就会尝试去创建/controller这个节点,当前broker去创建节点的时候,也有可能其他broker同时去尝试创建这个节点,只有创建成功的那个broker才会成为控制器,而创建失败的broker则表示竞选失败。每个broker都会在内存中保存当前控制器的brokerid值,这个值可以标识为activeControllerId。
Zookeeper中还有一个与控制器有关的/controller_epoch节点,这个节点是持久(PERSISTENT)节点,节点中存放的是一个整型的controller_epoch值。controller_epoch用于记录控制器发生变更的次数,即记录当前的控制器是第几代控制器,我们也可以称之为“控制器的纪元”。controller_epoch的初始值为1,即集群中第一个控制器的纪元为1,当控制器发生变更时,没选出一个新的控制器就将该字段值加1。每个和控制器交互的请求都会携带上controller_epoch这个字段,如果请求的controller_epoch值小于内存中的controller_epoch值,则认为这个请求是向已经过期的控制器所发送的请求,那么这个请求会被认定为无效的请求。如果请求的controller_epoch值大于内存中的controller_epoch值,那么则说明已经有新的控制器当选了。由此可见,Kafka通controller_epoch来保证控制器的唯一性,进而保证相关操作的一致性。
控制器在选举成功之后会读取Zookeeper中各个节点的数据来初始化上下文信息(ControllerContext),并且也需要管理这些上下文信息,比如为某个topic增加了若干个分区,控制器在负责创建这些分区的同时也要更新上下文信息,并且也需要将这些变更信息同步到其他普通的broker节点中。不管是监听器触发的事件,还是定时任务触发的事件,亦或者是其他事件(比如ControlledShutdown)都会读取或者更新控制器中的上下文信息,那么这样就会涉及到多线程间的同步,如果单纯的使用锁机制来实现,那么整体的性能也会大打折扣。针对这一现象,Kafka的控制器使用单线程基于事件队列的模型,将每个事件都做一层封装,然后按照事件发生的先后顺序暂存到LinkedBlockingQueue中,然后使用一个专用的线程(ControllerEventThread)按照FIFO(First Input First Output, 先入先出)的原则顺序处理各个事件,这样可以不需要锁机制就可以在多线程间维护线程安全。
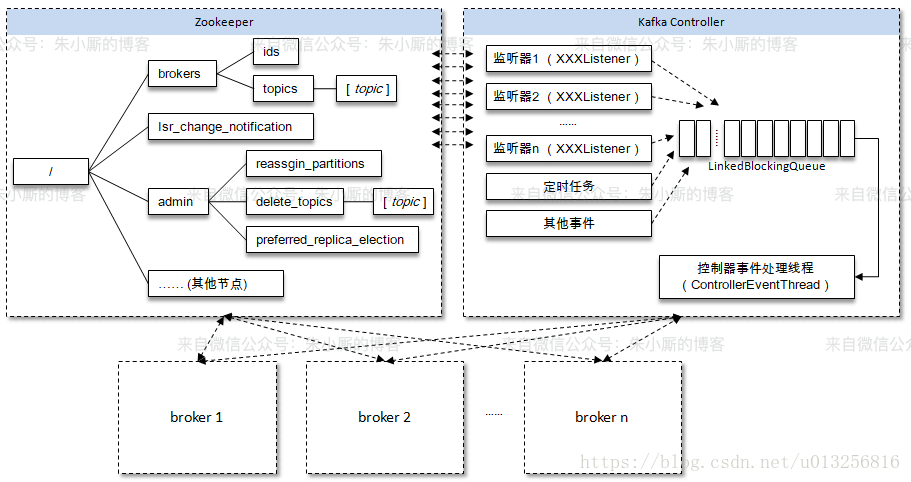
在Kafka的早期版本中,并没有采用Kafka Controller这样一个概念来对分区和副本的状态进行管理,而是依赖于Zookeeper,每个broker都会在Zookeeper上为分区和副本注册大量的监听器(Watcher)。当分区或者副本状态变化时,会唤醒很多不必要的监听器,这种严重依赖于Zookeeper的设计会有脑裂、羊群效应以及造成Zookeeper过载的隐患。在目前的新版本的设计中,只有Kafka Controller在Zookeeper上注册相应的监听器,其他的broker极少需要再监听Zookeeper中的数据变化,这样省去了很多不必要的麻烦。不过每个broker还是会对/controller节点添加监听器的,以此来监听此节点的数据变化(参考ZkClient中的IZkDataListener)。
当/controller节点的数据发生变化时,每个broker都会更新自身内存中保存的activeControllerId。如果broker在数据变更前是控制器,那么如果在数据变更后自身的brokerid值与新的activeControllerId值不一致的话,那么就需要“退位”,关闭相应的资源,比如关闭状态机、注销相应的监听器等。有可能控制器由于异常而下线,造成/controller这个临时节点会被自动删除;也有可能是其他原因将此节点删除了。
当/controller节点被删除时,每个broker都会进行选举,如果broker在节点被删除前是控制器的话,在选举前还需要有一个“退位”的动作。如果有特殊需要,可以手动删除/controller节点来触发新一轮的选举。当然关闭控制器所对应的broker以及手动向/controller节点写入新的brokerid的所对应的数据同样可以触发新一轮的选举。
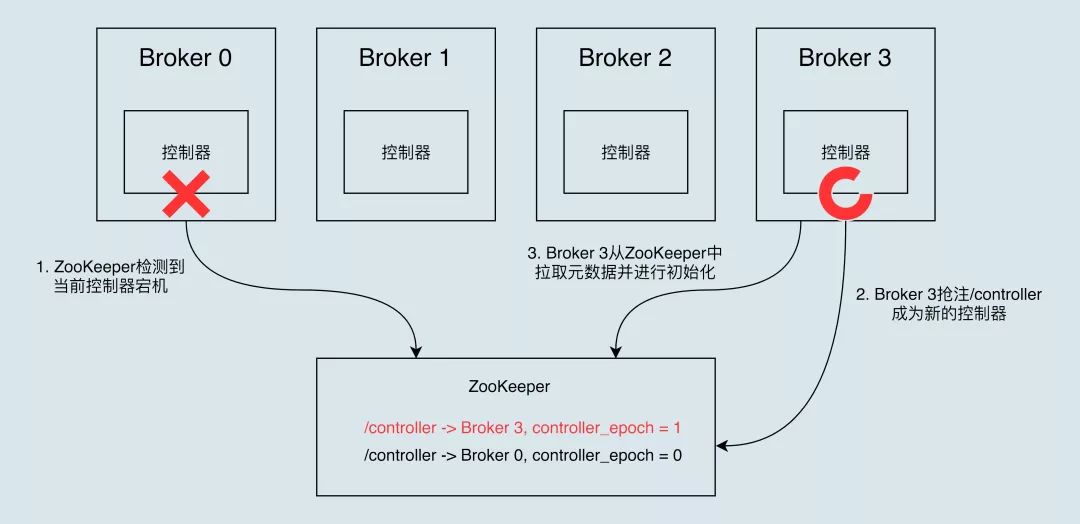
原文链接:https://blog.csdn.net/u013256816/article/details/80865540
作者:朱小厮
脑裂:当网络原因,导致心跳检测超时,主备切换的情况下,此时slave已经开始提供服务。但是后续之前被判定“死”的master由于网络恢复重新“复活”,此时系统存在两个“主”,发生脑裂问题;
羊群效应:在分布式系统中,例如Zokeeper集群中,例如某一节点A被大量client进行watch时,当节点A发生变化时候可能只对某一个客户端有影响,但是由于所有客户端都对该节点进行了watch,所以对于其他没有影响的client也会受到通知,这种不必要的通知就是分布式中的羊群效应。
过载:简单地讲就是系统当前所承受的压力超过了自身的处理能力
控制器内部设计原理
在 Kafka 0.11 版本之前,控制器的设计是相当繁琐的,代码更是有些混乱,这就导致社区中很多控制器方面的 Bug 都无法修复。控制器是多线程的设计,会在内部创建很多个线程。比如,控制器需要为每个 Broker 都创建一个对应的 Socket 连接,然后再创建一个专属的线程,用于向这些 Broker 发送特定请求。如果集群中的 Broker 数量很多,那么控制器端需要创建的线程就会很多。另外,控制器连接 ZooKeeper 的会话,也会创建单独的线程来处理 Watch 机制的通知回调。除了以上这些线程,控制器还会为主题删除创建额外的 I/O 线程。
比起多线程的设计,更糟糕的是,这些线程还会访问共享的控制器缓存数据。我们都知道,多线程访问共享可变数据是维持线程安全最大的难题。为了保护数据安全性,控制器不得不在代码中大量使用 ReentrantLock 同步机制,这就进一步拖慢了整个控制器的处理速度。
鉴于这些原因,社区于 0.11 版本重构了控制器的底层设计,最大的改进就是,把多线程的方案改成了单线程加事件队列的方案。我直接使用社区的一张图来说明。
在0.11版本之后将多线程并发访问改成了单线程事件队列模式。将涉及到共享数据竞争相关方面的访问抽象成事件,将事件塞入阻塞队列中,然后单线程处理。
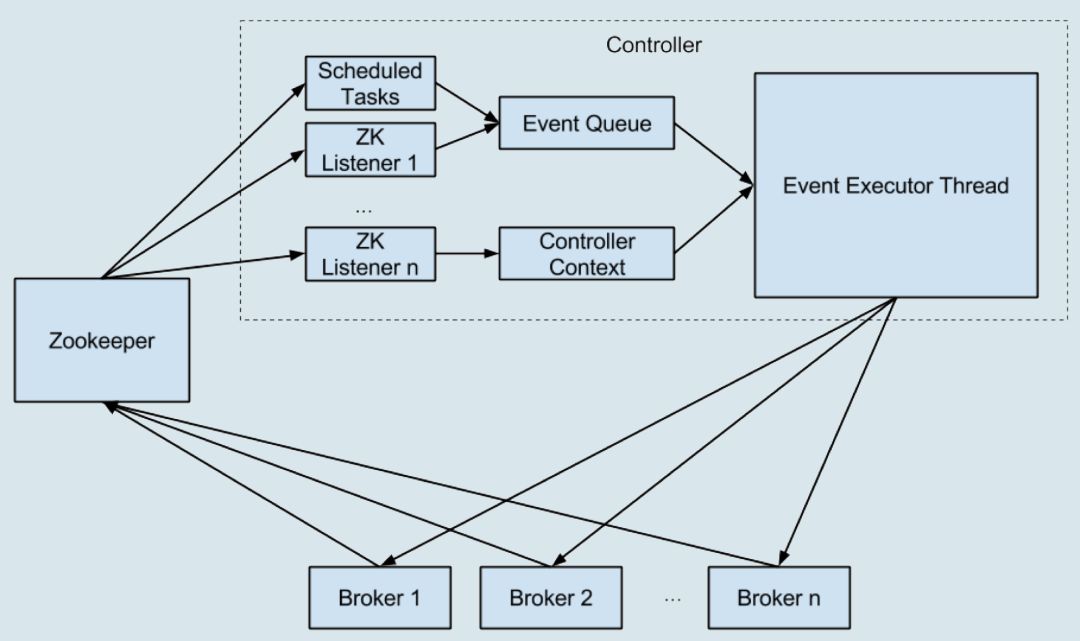
从这张图中,我们可以看到,社区引入了一个事件处理线程,统一处理各种控制器事件,然后控制器将原来执行的操作全部建模成一个个独立的事件,发送到专属的事件队列中,供此线程消费。这就是所谓的单线程 + 队列的实现方式。
值得注意的是,这里的单线程不代表之前提到的所有线程都被“干掉”了,控制器只是把缓存状态变更方面的工作委托给了这个线程而已。
这个方案的最大好处在于,控制器缓存中保存的状态只被一个线程处理,因此不再需要重量级的线程同步机制来维护线程安全,Kafka 不用再担心多线程并发访问的问题,非常利于社区定位和诊断控制器的各种问题。事实上,自 0.11 版本重构控制器代码后,社区关于控制器方面的 Bug 明显少多了,这也说明了这种方案是有效的。
针对控制器的第二个改进就是,将之前同步操作 ZooKeeper 全部改为异步操作。
ZooKeeper 本身的 API 提供了同步写和异步写两种方式。之前控制器操作 ZooKeeper 使用的是同步的 API,性能很差,集中表现为,当有大量主题分区发生变更时,ZooKeeper 容易成为系统的瓶颈。新版本 Kafka 修改了这部分设计,完全摒弃了之前的同步 API 调用,转而采用异步 API 写入 ZooKeeper,性能有了很大的提升。根据社区的测试,改成异步之后,ZooKeeper 写入提升了 10 倍!
除了以上这些,社区最近又发布了一个重大的改进!之前 Broker 对接收的所有请求都是一视同仁的,不会区别对待。这种设计对于控制器发送的请求非常不公平,因为这类请求应该有更高的优先级。
举个简单的例子,假设我们删除了某个主题,那么控制器就会给该主题所有副本所在的 Broker 发送一个名为 StopReplica 的请求。如果此时 Broker 上存有大量积压的 Produce 请求,那么这个 StopReplica 请求只能排队等。如果这些 Produce 请求就是要向该主题发送消息的话,这就显得很讽刺了:主题都要被删除了,处理这些 Produce 请求还有意义吗?此时最合理的处理顺序应该是,赋予 StopReplica 请求更高的优先级,使它能够得到抢占式的处理。
这在 2.2 版本之前是做不到的。不过自 2.2 开始,Kafka 正式支持这种不同优先级请求的处理。简单来说,Kafka 将控制器发送的请求与普通数据类请求分开,实现了控制器请求单独处理的逻辑。鉴于这个改进还是很新的功能,具体的效果我们就拭目以待吧。
转载至:https://www.huaweicloud.com/articles/a5e5aafc84e1bbad4203dfb7dc34f4a9.html
作者:华为云
8.3. Controller作用
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
监听partition相关的变化。为Zookeeper中的/admin/reassign_partitions节点注册PartitionReassignmentListener,用来处理分区重分配的动作。为Zookeeper中的/isr_change_notification节点注册IsrChangeNotificetionListener,用来处理ISR集合变更的动作。为Zookeeper中的/admin/preferred-replica-election节点添加PreferredReplicaElectionListener,用来处理优先副本的选举动作。
监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
启动并管理分区状态机和副本状态机。
更新集群的元数据信息。Client可以从任何一台broker上获取集群完整的元数据信息,这就需要controller在集群元数据信息发生变更后通知每一个broker。当有分区信息变更时,controller会将变更后的信息封装进UpdateMetadataRequest请求中,然后发送给集群中的每个Broker。
为了避免分区副本分配不均匀,引入preferred副本的概念,假设一个分区副本的列表是[1,2,3],那么broker1就是该分区的preferred leader。但是随着时间的推进,分区leader发生变化,最后preferred leader不一定就是分区leader。
- broker段参数auto.leader.reblance.enable设置true,controller会定时自动调整preferred leader
- 通过kafka-preferred-replica-election脚本触发
上面两种方法都会往Zookeeper的/admin/preferredreplicaelection节点写入数据。controller也会注册该节点的目录监听器。一旦接收到改变通知,controller会将对应分区的leader调整回副本列表中的第一个,并且广播出去。
受控关闭是指的以kafka-server-stop.sh或者kill -15的方式关闭kafka broker。
受控关闭是由即将关闭的broker向controller发送ControlledShutdownRequest。当发送完请求后,broker处于阻塞状态,controller会进行leader重选举和ISR收缩调整后,会给broker发送ControlledShutdownResoponse,表示broker可以关闭。
参考资料还有:https://cloud.tencent.com/developer/article/1596095
8.4. Controller与broker通信
controller启动时会与集群中的所有broker(包括controller在的broker)建立TCP连接,并且会为每个TCP连接建立一个RequestSendThread,也就是说controller会和每个broker建立一个TCP连接,并且开启一个I/O线程。
controller目前主要有以下三种请求:
- UpdateMetaRequest:更新集群元数据请求,包含了集群的元数据信息。broker接收到该请求后,会更新本地的缓存信息
- LeaderAndIsrRequest:用于创建分区和副本
- StopReplicaRequest:停止指定副本的数据请求操作,另外还负责删除副本数据功能。
8.4 controller结构
控制器中到底保存了哪些数据。我用一张图来说明一下。
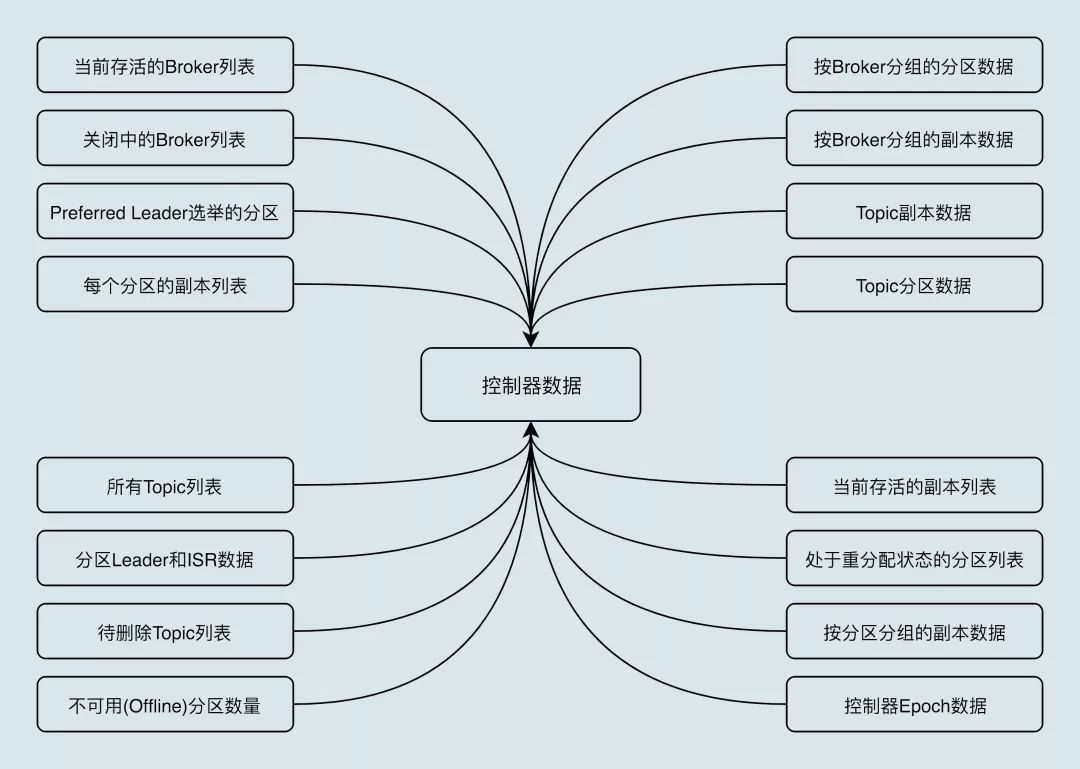
怎么样,图中展示的数据量是不是很多?几乎把我们能想到的所有 Kafka 集群的数据都囊括进来了。这里面比较重要的数据有:
所有主题信息。包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
所有 Broker 信息。包括当前都有哪些运行中的 Broker,哪些正在关闭中的 Broker 等。
所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
值得注意的是,这些数据其实在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。有了这些数据,控制器就能对外提供数据服务了。这里的对外主要是指对其他 Broker 而言,控制器通过向这些 Broker 发送请求的方式将这些数据同步到其他 Broker 上。
转载至:https://www.huaweicloud.com/articles/a5e5aafc84e1bbad4203dfb7dc34f4a9.html
作者:华为云
目前总共有9种controller event,它们分别是:
- Idle
- ControllerChange
- BrokerChange
- TopicChange
- TopicDeletion
- PartitionReassignment
- AutoLeaderBalance
- ManualLeaderBalance
- ControlledShutdown
- IsrChange
9. kafka的Connector
9.1. Connector概念
Kafka Connect 是一种用于在 Apache Kafka 和其他系统之间可扩展且可靠地流式传输数据的工具。它使快速定义将大量数据移入和移出 Kafka 的连接器变得简单。Kafka Connect 可以摄取整个数据库或从所有应用程序服务器收集指标到 Kafka 主题中,使数据可用于低延迟的流处理。导出作业可以将数据从 Kafka 主题传送到二级存储和查询系统或批处理系统进行离线分析。
Kafka Connect 功能包括:
- Kafka 连接器的通用框架- Kafka Connect 标准化了其他数据系统与 Kafka 的集成,简化了连接器的开发、部署和管理
- 分布式和独立模式- 向上扩展为支持整个组织的大型集中管理服务,或向下扩展为开发、测试和小型生产部署
- REST 接口- 通过易于使用的 REST API 提交和管理到 Kafka Connect 集群的连接器
- 自动偏移管理- 只需来自连接器的少量信息,Kafka Connect 就可以自动管理偏移提交过程,因此连接器开发人员无需担心连接器开发中这个容易出错的部分
- 默认情况下分布式和可扩展- Kafka Connect 建立在现有的组管理协议上。可以添加更多工作人员来扩展 Kafka Connect 集群。
- 流/批处理集成- 利用 Kafka 的现有功能,Kafka Connect 是桥接流和批处理数据系统的理想解决方案
9.2. Connector作用
bootstrap.servers- 用于引导到 Kafka 的连接的 Kafka 服务器列表key.converter- 转换器类,用于在 Kafka Connect 格式和写入 Kafka 的序列化格式之间进行转换。这控制了写入 Kafka 或从 Kafka 读取的消息中密钥的格式,并且由于它独立于连接器,因此它允许任何连接器使用任何序列化格式。常见格式的示例包括 JSON 和 Avro。value.converter- 转换器类,用于在 Kafka Connect 格式和写入 Kafka 的序列化格式之间进行转换。这控制了写入 Kafka 或从 Kafka 读取的消息中值的格式,并且由于它独立于连接器,因此它允许任何连接器使用任何序列化格式。常见格式的示例包括 JSON 和 Avro。offset.storage.file.filename- 用于存储偏移数据的文件group.id(defaultconnect-cluster) - 集群的唯一名称,用于形成 Connect 集群组;请注意,这不能与消费者组 ID冲突config.storage.topic(defaultconnect-configs) - 用于存储连接器和任务配置的主题;请注意,这应该是单个分区、高度复制、压缩的主题。您可能需要手动创建主题以确保正确配置,因为自动创建的主题可能有多个分区或自动配置为删除而不是压缩offset.storage.topic(默认connect-offsets)- 用于存储偏移量的主题;这个主题应该有很多分区,被复制,并被配置为压缩status.storage.topic(默认connect-status)- 用于存储状态的主题;这个主题可以有多个分区,并且应该被复制并配置为压缩
9.3. Connector配置
Kafka Connect 目前支持两种执行模式:独立(单进程)和分布式。
大多数配置都依赖于连接器,因此无法在此处进行概述。但是,有一些常见的选项:
name- 连接器的唯一名称。尝试使用相同名称再次注册将失败。connector.class- 连接器的 Java 类tasks.max- 应为此连接器创建的最大任务数。如果连接器无法达到这种并行度级别,它可能会创建更少的任务。key.converter- (可选)覆盖工作人员设置的默认密钥转换器。value.converter-(可选)覆盖工作人员设置的默认值转换器。
Sink 连接器还有一些额外的选项来控制它们的输入。每个接收器连接器必须设置以下之一:
topics- 用作此连接器输入的主题的逗号分隔列表topics.regex- 用作此连接器输入的主题的 Java 正则表达式
更多连接器配置:
官方网站:https://kafka.apache.org/documentation/#connect_user
9.4. Connector错误报告
Kafka Connect 提供错误报告来处理在处理的各个阶段遇到的错误。默认情况下,在转换期间或转换中遇到的任何错误都会导致连接器失败。每个连接器配置还可以通过跳过此类错误来允许容忍此类错误,可选择将每个错误以及失败操作的详细信息和有问题的记录(具有各种详细级别)写入 Connect 应用程序日志。当接收器连接器处理从其 Kafka 主题消费的消息时,这些机制还会捕获错误,并且所有错误都可以写入可配置的“死信队列”(DLQ)Kafka 主题。
要将连接器的转换器、转换或接收器连接器本身内的错误报告到日志,请errors.log.enable=true在连接器配置中设置以记录每个错误和问题记录的主题、分区和偏移的详细信息。出于额外的调试目的,设置errors.log.include.messages=true为还将问题记录键、值和标题记录到日志中(注意这可能会记录敏感信息)。
9.5. Connector开发指南
为了在 Kafka 和另一个系统之间复制数据,用户Connector为他们想要从中提取数据或推送数据的系统创建一个。连接器有两种形式:SourceConnectors从另一个系统导入数据(例如JDBCSourceConnector将关系数据库导入 Kafka)和SinkConnectors导出数据(例如HDFSSinkConnector将 Kafka 主题的内容导出到 HDFS 文件)。
Connectors自己不执行任何数据复制:它们的配置描述了要复制的数据,并且Connector负责将该作业分解为一组Tasks可以分发给工作人员的数据。这些Tasks也有两种相应的风格:SourceTask和SinkTask。
有了任务,每个人都Task必须将其数据子集复制到 Kafka 或从 Kafka 复制。在 Kafka Connect 中,应该始终可以将这些分配构建为一组由具有一致模式的记录组成的输入和输出流。有时这种映射是显而易见的:一组日志文件中的每个文件都可以被认为是一个流,每个解析的行使用相同的模式和偏移量形成一个记录,作为文件中的字节偏移量存储。在其他情况下,映射到这个模型可能需要更多的努力:JDBC 连接器可以将每个表映射到一个流,但偏移量不太清楚。一种可能的映射使用时间戳列生成查询,增量返回新数据,最后查询的时间戳可以用作偏移量。
开发连接器只需要实现两个接口,即Connector和Task。file包中的Kafka 源代码包含一个简单示例。此连接器旨在用于独立模式,并实现了SourceConnector/SourceTask以读取文件的每一行并将其作为记录发出,而SinkConnector/SinkTask将每条记录写入文件。
Kafka是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析)。为何集成其他系统和解耦应用,经常使用Producer来发送消息到Broker,并使用Consumer来消费Broker中的消息。Kafka Connect是到0.9版本才提供的并极大的简化了其他系统与Kafka的集成。Kafka Connect运用用户快速定义并实现各种Connector(File,Jdbc,Hdfs等),这些功能让大批量数据导入/导出Kafka很方便。
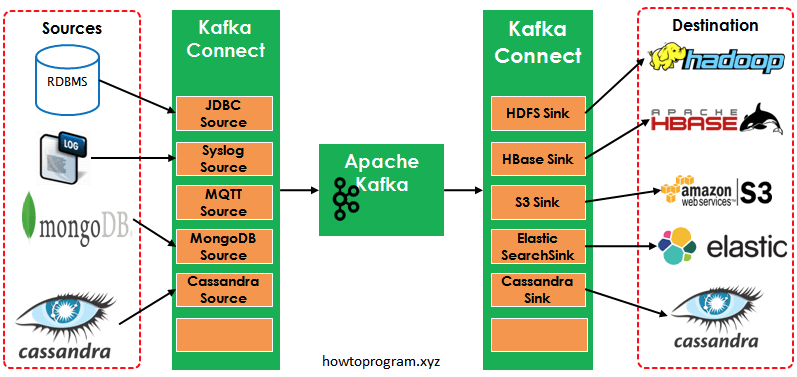
如图中所示,左侧的Sources负责从其他异构系统中读取数据并导入到Kafka中;右侧的Sinks是把Kafka中的数据写入到其他的系统中。
Kafka Connector很多,包括开源和商业版本的。如下列表中是常用的开源Connector。
| Connectors | References |
|---|---|
| Jdbc | Source, Sink |
| Elastic Search | Sink1, Sink2, Sink3 |
| Cassandra | Source1, Source 2, Sink1, Sink2 |
| MongoDB | Source |
| HBase | Sink |
| Syslog | Source |
| MQTT (Source) | Source |
| Twitter (Source) | Source, Sink |
| S3 | Sink1, Sink2 |
这是已经得到支持的组件,不需要做额外的开发: https://www.confluent.io/product/connectors/ 括号中的Source表示将数据从其他系统导入Kafka,Sink表示将数据从Kafka导出到其他系统。 其他的我没看,但是JDBC的实现比较的坑爹,是通过primary key(如id)和时间戳(如updateTime)字段,
来判断数据是否更新,这样的话应用范围非常受局限。
转载至:https://blog.csdn.net/wjandy0211/article/details/93642257
作者:wandy0211
10. kafka的安全
10.1. kafka的安全策略
在 0.9.0.0 版本中,Kafka 社区添加了许多单独或一起使用的功能,以提高 Kafka 集群的安全性。目前支持以下安全措施:
- 使用 SSL 或 SASL 验证从客户端(生产者和消费者)、其他代理和工具到代理的连接。Kafka 支持以下 SASL 机制:
- SASL/GSSAPI (Kerberos) - 从 0.9.0.0 版本开始
- SASL/PLAIN - 从 0.10.0.0 版本开始
- SASL/SCRAM-SHA-256 和 SASL/SCRAM-SHA-512 - 从版本 0.10.2.0 开始
- SASL/OAUTHBEARER - 从 2.0 版开始
- 对从代理到 ZooKeeper 的连接进行身份验证
- 使用 SSL 加密代理和客户端之间、代理之间或代理和工具之间传输的数据(请注意,启用 SSL 会导致性能下降,其大小取决于 CPU 类型和 JVM 实现。)
- 客户端对读/写操作的授权
- 授权是可插拔的,并且支持与外部授权服务的集成
值得注意的是,安全性是可选的——支持非安全集群,以及经过身份验证、未经身份验证、加密和非加密客户端的混合。
Apache Kafka 允许客户端使用 SSL 进行流量加密和身份验证。默认情况下,SSL 处于禁用状态,但可以根据需要打开。以下段落详细解释了如何设置您自己的 PKI 基础设施,使用它来创建证书并配置 Kafka 以使用这些。
官网配置地址:https://kafka.apache.org/documentation/#security_overview
包含如下内容:
- 为每个 Kafka 代理生成 SSL 密钥和证书
- 主机名验证(主机名验证(启用后)是根据该服务器的实际主机名或 IP 地址检查您正在连接的服务器提供的证书的属性的过程,以确保您确实连接到正确的服务器。 此检查的主要原因是为了防止中间人攻击。对于 Kafka,默认情况下已禁用此检查很长时间,但从 Kafka 2.0.0 开始,服务器的主机名验证默认为客户端连接以及代理间连接启用。)
- 签署证书等。
Kafka 附带了一个可插入的授权器和一个开箱即用的授权器实现,它使用 zookeeper 来存储所有的 acl。Authorizer 是通过在 server.properties 中设置authorizer.class.name来配置的。要启用开箱即用的实现,请使用:
1 | authorizer.class.name=kafka.security.authorizer.AclAuthorizer |
安全实现允许您为代理-客户端和代理-代理通信配置不同的协议。这些必须在单独的反弹中启用。PLAINTEXT 端口必须始终保持打开状态,以便代理和/或客户端可以继续通信。
ZooKeeper 从 3.5.x 版本开始支持双向 TLS (mTLS) 身份验证。从 2.5 版开始,Kafka 支持使用 SASL 和 mTLS 对 ZooKeeper 进行身份验证——单独或同时使用。
除了认证外kafka还可以通过acl设置权限控制,没有配置acl权限的用户默认是不能访问任何topic的(admin用户可以访问所有)
10.2. kafka中的SASL
需要先明确的一点是,用户认证和权限控制是两码事。用户认证是确认这个用户能否访问当前的系统,而权限控制是控制用户对当前系统中各种资源的访问权限。
用户认证就是下面要讲的内容,而kafka的权限控制,则是对应bin/kafka-acls.sh工具所提供的一系列功能。
标题特地说明kafka2.x是因为kafka2.0的时候推出一种新的用户认证方式,SASL/OAUTHBEARER,在此前的版本是不存在这个东西的。那么加上这个之后,kafka目前共有4种常见的认证方式。
- SASL/GSSAPI(kerberos):kafka0.9版本推出,即借助kerberos实现用户认证,如果公司恰好有kerberos环境,那么用这个是比较合适的。
- SASL/PLAIN:kafka0.10推出,非常简单,简单得有些鸡肋,不建议生产环境使用,除非对这个功能二次开发,这也是我后面要讲的。
- SASL/SCRAM:kafka0.10推出,全名Salted Challenge Response Authentication Mechanism,为解决SASL/PLAIN的不足而生,缺点可能是某些客户端并不支持这种方式认证登陆(使用比较复杂)。
- SASL/OAUTHBEARER:kafka2.0推出,实现较为复杂,目前业内应该较少实践。
其实除了上述四种用户认证功能之外,还有一个叫Delegation Token的东西。这个东西说一个轻量级的工具,是对现有SASL的一个补充,能够提高用户认证的性能(主要针对Kerberos的认证方式)。算是比较高级的用法,一般也用不到,所以也不会多介绍,有兴趣可以看这里Authentication using Delegation Tokens。
SASL/GSSAPI
如果已经有kerberos的环境,那么会比较适合使用这种方式,只需要让管理员分配好principal和对应的keytab,然后在配置中添加对应的选项就可以了。需要注意的是,一般采用这种方案的话,zookeeper也需要配置kerberos认证。
SASL/PLAIN
这种方式其实就是一个用户名/密码的认证方式,不过它有很多缺陷,比如用户名密码是存储在文件中,不能动态添加,明文等等!这些特性决定了它比较鸡肋,但好处是足够简单,这使得我们可以方便地对它进行二次开发。本篇文章后续会介绍SASL/PLAIN的部署方式和二次开发的例子(基于kafka2.x)。
SASL/SCRAM
针对PLAIN方式的不足而提供的另一种认证方式。这种方式的用户名/密码是存储中zookeeper的,因此能够支持动态添加用户。该种认证方式还会使用sha256或sha512对密码加密,安全性相对会高一些。
而且配置起来和SASL/PLAIN差不多同样简单,添加用户/密码的命令官网也有提供,个人比较推荐使用这种方式。不过有些客户端是不支持这个方式认证登陆的,比如python的kafka客户端,这点需要提前调研好。
具体的部署方法官网或网上有很多,这里不多介绍,贴下官网的Authentication using SASL/SCRAM。
SASL/OAUTHBEARER
SASL/OAUTHBEARER是基于OAUTH2.0的一个新的认证框架,这里先说下什么是OAUTH吧,引用维基百科。
OAuth是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照片,视频,联系人列表),而无需将用户名和密码提供给第三方应用。而 OAUTH2.0算是OAUTH的一个加强版。
说白了,SASL/OAUTHBEARER就是一套让用户使用第三方认证工具认证的标准,通常是需要自己实现一些token认证和创建的接口,所以会比较繁琐。
说了这么多,接下来就说实战了,先介绍下如何配置SASL/PLAIN。配置流程可以查看官网或者下面博客。
转载至:https://www.cnblogs.com/listenfwind/p/14026462.html
作者:zzzzMing
官网地址: https://kafka.apache.org/documentation/#security_sasl
10.3. 针对SASL、SSL补充说明
SSL(Secure Sockets Layer 安全套接字协议),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层与应用层之间对网络连接进行加密。
SASL 库称为 libsasl。libsasl 是一个框架,允许正确编写的 SASL 消费方应用程序使用系统中可用的所有 SASL 插件。术语插件是指为 SASL 提供服务的对象。插件位于 libsasl 的外部。SASL 插件可用于验证和安全性、名称标准化以及辅助属性(如口令)的查找。加密算法存储在插件中,而不是 libsasl 中。
libsasl 为消费方应用程序和库提供应用编程接口 (application programming interface, API)。服务提供者接口 (service provider interface, SPI) 是为插件提供的,用于为 libsasl 提供服务。libsasl 不能识别网络或协议。相应地,应用程序必须负责在客户机与服务器之间发送和接收数据。
SASL 对用户使用两个重要的标识符。验证 ID (authid) 是用于验证用户的用户 ID。验证 ID 授予用户系统访问权限。授权 ID (userid) 用于检查是否允许用户使用特定选项。
SASL 客户机应用程序和 SASL 服务器应用程序将协商公用的 SASL 机制和安全级别。通常,SASL 服务器应用程序会将其可接受的验证机制的列表发送给客户机。随后 SASL 客户机应用程序便可决定哪种验证机制最能满足其要求。此后,客户机与服务器使用双方同意的验证机制,对它们之间交换的由 SASL 提供的验证数据进行验证。此交换将持续下去,直到验证成功完成、失败或被客户机或服务器中止。
在验证过程中,SASL 验证机制可以协商安全层。如果已选择安全层,则必须在 SASL 会话期间使用该层。
更详细内容可以查看下面博客。
转载至:https://blog.csdn.net/AMDS123/article/details/69569176
作者:算法学习者
10.4. GSS-API/Kerberos
通用安全服务应用程序编程接口(Generic Security Service Application Program Interface),也叫GSSAPI或GSS-API,以一种统一的模式为使用者提供机制无关,平台无关,程序语言环境无关,可移植的安全服务。程序员在编写应用程序时,可以应用通用的安全机制。开发者不必针对任何特定的平台、安全机制、保护类型或传输协议来定制安全实现。使用 GSS-API,程序员可忽略保护网络数据方面的细节。使用 GSS-API 编写的程序在网络安全方面具有更高的可移植性。这种可移植性是通用安全服务 API 的一个特点。
GSS-API 是一个以通用方式为调用者提供安全服务的框架。许多底层机制和技术(如 Kerberos v5 或公钥技术)都支持 GSS-API 框架,如下图所示:

GSS-API并不提供任何的安全机制,而是由安全机制提供方在实现安全的机制的基础上,实现GSS-API接口规范(通常是随着安全软件一同安装的库文件)。从而向应用程序编写者提供独立于安全机制提供方的GSS-API,这样,如果改变了底层安全机制(同样是实现了GSS-API规范的),那么应用不需要做任何改变。
可用的底层安全机制:
Kerberos v5
Diffie-Hellman
SPNEGO(伪机制)
原文链接:https://blog.csdn.net/zhoubangtao/article/details/26280565
作者:zhoubangtao
关于kerberos协议讲解可以参考:https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-2000-server/cc961976(v=technet.10)?redirectedfrom=MSDN,也可以翻阅《计算机网络第7版》338面

11. kafka其他
11.1. 消息
消息由可变长度的报头、可变长度的不透明密钥字节数组和可变长度的不透明值字节数组组成。保持键和值不透明是正确的决定:目前在序列化库方面取得了很大进展,任何特定选择都不太可能适合所有用途。使用 Kafka 的特定应用程序可能会要求特定的序列化类型作为其使用的一部分。该RecordBatch接口只是消息上的迭代器,具有用于批量读取和写入 NIO 的专门方法Channel。
消息(又名记录)总是成批写入的。一批消息的技术术语是一个记录批,一个记录批包含一个或多个记录。在退化的情况下,我们可以有一个包含单个记录的记录批次。记录批次和记录有自己的标题。
对于传统的MQ而言,一般经过消费后的消息都会被删除,而Kafka却不会被删除,始终保留着所有的消息,只记录一个消费者消费消息的offset(偏移量)作为标记,可以允许消费者可以自己设置这个offset,从而可以重复消费一些消息。但不删除肯定不行,日积月累,消息势必会越来越多,占用空间也越来越大。Kafka提供了两种策略来删除消息:一是基于时间,二是基于Partition文件的大小,可以通过配置来决定用那种方式。不过现在磁盘那么廉价,空间也很大,隔个一年半载删除一次也不为过。
消息的序列化器介绍Avro和Json可以查看:https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
11.1.1 消息丢失问题
生产者丢失消息
producer.send(Object msg) ; 这个发送消息的方式是异步的;fire and forget,发送而不管结果如何;
失败的原因可能有很多,比如网络抖动,发送消息超出大小限制;
怎么破呢?永远使用带有返回值值的消息发送方式,即 producer.send(msg,callback)
通过callback可以准确的告诉你消息是否发送成功了,发送失败了你也可以有处置方法:
网络抖动: 重发
发送消息超出大小:调整消息大小进行发送
这种情况并不是broker丢失消息了,是producer的消息没有提交成功。
消费者丢失消息
什么时候消费者丢失数据呢?即先更新位移,再消费消息,如果消费程序出现故障,没消费完毕,则丢失了消息,此时,broker并不知道。
怎么破?总是先消费消息,再更新位移;这种可能带来消息重复消费的问题,但是不会出现消息丢失问题;
多线程消费丢失消息
即开启了位移自动提交,多线程处理的时候,如果有一个线程出现问题,但是还是提交了位移,会发生消息丢失。
怎么破? 关闭自动提交位移,消费者端配置参数:enable.auto.commit=false
调优broker参数防止消息丢失
主要通过调整配置来保证kafka消息不丢失。
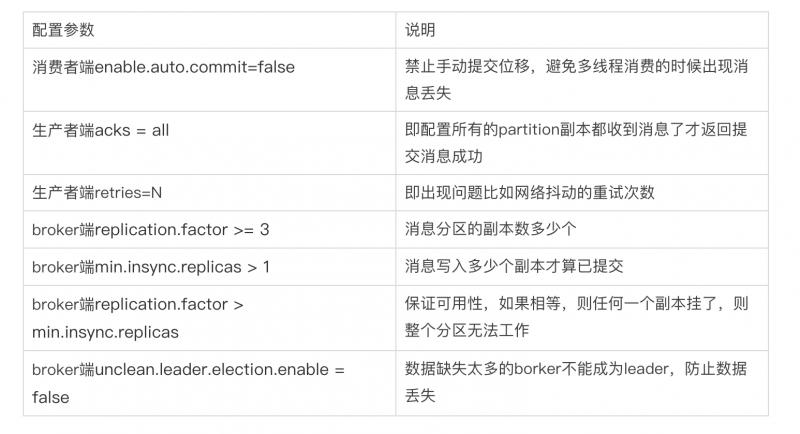
然后就是producer发送消息一定要使用带回调函数的方法,并对发送失败的情况进行处理。
同时写consumer程序的时候先消费再提交;
转载至:https://zhuanlan.zhihu.com/p/136576215
作者:李福春
11.1.2 消息积压问题
Kafka消息积压的典型场景:
1.实时/消费任务挂掉
比如,我们写的实时应用因为某种原因挂掉了,并且这个任务没有被监控程序监控发现通知相关负责人,负责人又没有写自动拉起任务的脚本进行重启。
那么在我们重新启动这个实时应用进行消费之前,这段时间的消息就会被滞后处理,如果数据量很大,可就不是简单重启应用直接消费就能解决的。
2.Kafka分区数设置的不合理(太少)和消费者”消费能力”不足
Kafka单分区生产消息的速度qps通常很高,如果消费者因为某些原因(比如受业务逻辑复杂度影响,消费时间会有所不同),就会出现消费滞后的情况。
此外,Kafka分区数是Kafka并行度调优的最小单元,如果Kafka分区数设置的太少,会影响Kafka consumer消费的吞吐量。
3.Kafka消息的key不均匀,导致分区间数据不均衡
在使用Kafka producer消息时,可以为消息指定key,但是要求key要均匀,否则会出现Kafka分区间数据不均衡。
那么,针对上述的情况,有什么好的办法处理数据积压呢?
一般情况下,针对性的解决办法有以下几种:
1.实时/消费任务挂掉导致的消费滞后
a.任务重新启动后直接消费最新的消息,对于”滞后”的历史数据采用离线程序进行”补漏”。
此外,建议将任务纳入监控体系,当任务出现问题时,及时通知相关负责人处理。当然任务重启脚本也是要有的,还要求实时框架异常处理能力要强,避免数据不规范导致的不能重新拉起任务。
b.任务启动从上次提交offset处开始消费处理
如果积压的数据量很大,需要增加任务的处理能力,比如增加资源,让任务能尽可能的快速消费处理,并赶上消费最新的消息
2.Kafka分区少了
如果数据量很大,合理的增加Kafka分区数是关键。如果利用的是Spark流和Kafka direct approach方式,也可以对KafkaRDD进行repartition重分区,增加并行度处理。
3.由于Kafka消息key设置的不合理,导致分区数据不均衡
可以在Kafka producer处,给key加随机后缀,使其均衡。
11.1.3 消息有序性
kafka是无法保证全局的消息顺序性的,只能保证主题的某个分区的消息顺序性。
11.1.4 消息格式
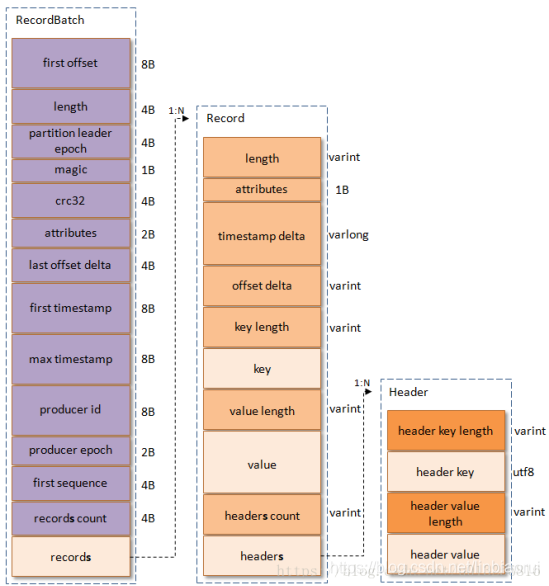
crc32:消息校验码
magic:消息版本号,0=v0,1=v1,2=v2,目前是2
attributes:占用2字节,低3位指压缩格式,0=none,1=gzip,2=snappy,3=lz4;第4位指时间戳,第5位值是否为事务消息,第6位指是否为control消息,用于支持事务,0=否,1=是,其余保留
key length:消息的key的长度,若为-1,则表示没有设置key,即key=null
key:可选,如果没有key则无此字段
value length:实际消息体的长度,若为-1,则表示消息为空(墓碑消息)
value:消息体,可以为空,即墓碑消息
中图length:消息总长度
timestamp delta:时间戳增量,这里保存与RecordBatch的起始时间戳的差值
offset delta:位移增量,保存与RecordBatch起始位移的差值
headers:用来支持应用级别的扩展,而无需像v0和v1版本一样将一些应用级别的属性值嵌入在消息体里面
first offset:表示当前RecordBatch的起始位移
左图length:计算partition leader epoch到headers之间的长度
partition leader epoch:用来确保数据可靠性
last offset delta:RecordBatch中最后一个Record的offset与第一个Record的offset的差值,主要被broker用来确认RecordBatch中Records的组装正确性
first timestamp:RecordBatch中第一条Record的时间戳
max timestamp:RecordBatch中最大的时间戳,一般情况下是指最后一个Record的时间戳, 和last offset delta的作用一样,用来确保消息组装的正确性
producer id:用来支持幂等性
producer epoch:和producer id一样,用来支持幂等性
first sequence:和producer id与producer epoch一样,用来支持幂等性
records count:RecordBatch中Record的个数
11.2. 监控
Kafka 使用 Yammer Metrics 在服务器中报告指标。Java 客户端使用 Kafka Metrics,这是一个内置的指标注册表,可以最大限度地减少引入客户端应用程序的传递依赖关系。两者都通过 JMX 公开指标,并且可以配置为使用可插拔的统计报告器来报告统计数据,以连接到您的监控系统。
所有 Kafka 速率指标都有一个相应的累积计数指标,后缀为-total。例如, records-consumed-rate有一个名为 的相应指标records-consumed-total。
查看可用指标的最简单方法是启动 jconsole 并将其指向正在运行的 kafka 客户端或服务器;这将允许使用 JMX 浏览所有指标。
Apache Kafka 默认禁用远程 JMX。您可以通过JMX_PORT为使用 CLI 或标准 Java 系统属性启动的进程设置环境变量来启用使用 JMX 的远程监控, 从而以编程方式启用远程 JMX。在生产场景中启用远程 JMX 时,您必须启用安全性,以确保未经授权的用户无法监视或控制您的代理或应用程序以及运行它们的平台。请注意,默认情况下,Kafka 中对 JMX 禁用身份验证,并且必须通过为KAFKA_JMX_OPTS使用 CLI 启动的进程设置环境变量或通过设置适当的 Java 系统属性来覆盖生产部署的安全配置 。请参阅 使用 JMX 技术进行监控和管理 有关保护 JMX 的详细信息。
具体监控配置可查看官网:https://kafka.apache.org/documentation/#monitoring
11.2.1 监控可视化
使用kafka-manager:
1 | # 我这里首先安装的是java 16.0版本一直报错No JVMCI compiler found,后面换成了java-1.8.0。这里可以搜索java版本yum -y list java* |
1 | 安装sbt:(很多网上教程都是坑,试了很多还是官方地址这个好用) |
1 | 这一步是配置国内源: |
1 | 配置完源之后就可以安装了 |
1 | 编译完成后会提示,编译好的文件保存到了:当前目录下/target/universal/cmak-3.0.0.1.zip |
使用systemctl管理kafka-manager服务
创建文件 /usr/lib/systemd/system/kafka-manager.service :
1 | [Unit] |
完成上述配置后,执行 systemctl daemon-reload 。
启动、停止、重启
1 | $ systemctl start kafka-manager |
配置日志切割
1 | /data/kafka-manager/target/universal/cmak-3.0.0.5/logs/application.log { |
11.3. 日志
具有两个分区的名为“my_topic”的主题的日志包含两个目录(即my_topic_0和my_topic_1),其中填充了包含该主题消息的数据文件。日志文件的格式是“日志条目”序列;每个日志条目是一个 4 字节的整数N,存储消息长度,后跟N 个消息字节。每条消息由 64 位整数偏移量唯一标识在发送到该分区上该主题的所有消息的流中,给出此消息开始的字节位置。下面给出了每条消息的磁盘格式。每个日志文件都以其包含的第一条消息的偏移量命名。因此,创建的第一个文件将是 00000000000.kafka,并且每个附加文件都将有一个整数名称,大约是前一个文件的S字节,其中S是配置中给出的最大日志文件大小。
使用消息偏移量作为消息 id 是不寻常的。我们最初的想法是使用生产者生成的 GUID,并在每个代理上维护从 GUID 到偏移量的映射。但是由于消费者必须为每个服务器维护一个 ID,因此 GUID 的全局唯一性没有任何价值。此外,维护从随机 id 到偏移量的映射的复杂性需要一个必须与磁盘同步的重量级索引结构,本质上需要一个完整的持久性随机访问数据结构。因此,为了简化查找结构,我们决定使用一个简单的每个分区原子计数器,它可以与分区 id 和节点 id 耦合来唯一标识一条消息;这使得查找结构更简单,尽管每个消费者请求仍可能进行多次搜索。然而,一旦我们在柜台上安顿下来,直接使用偏移量的跳转似乎很自然——毕竟两者都是分区独有的单调递增整数。由于偏移量对消费者 API 是隐藏的,所以这个决定最终是一个实现细节,我们采用了更有效的方法。
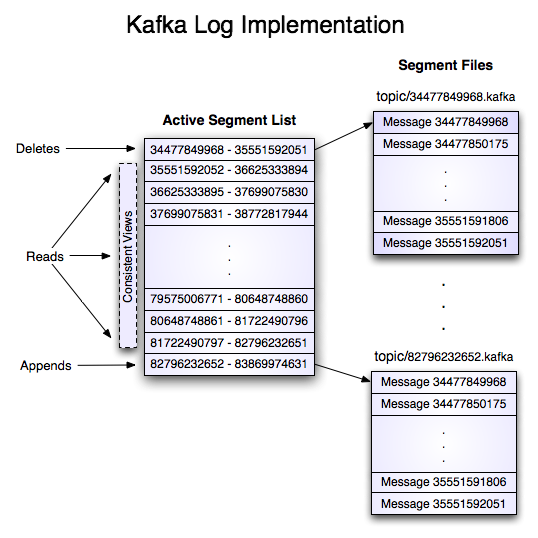
写
日志允许串行追加,它总是到最后一个文件。当此文件达到可配置的大小(例如 1GB)时,它会转存为新文件。该日志采用两个配置参数:M,它给出了在强制操作系统将文件刷新到磁盘之前要写入的消息数,以及S,它给出了强制刷新后的秒数。这提供了在系统崩溃时最多丢失M 条消息或S秒数据的持久性保证。
读取
读取是通过提供消息的 64 位逻辑偏移量和S字节最大块大小来完成的。这将在S字节缓冲区中包含的消息上返回一个迭代器。S旨在大于任何单个消息,但如果出现异常大的消息,可以多次重试读取,每次将缓冲区大小加倍,直到成功读取消息。可以指定最大消息和缓冲区大小,以使服务器拒绝大于某个大小的消息,并在客户端获得完整消息所需读取的最大值上进行绑定。读取缓冲区很可能以部分消息结束,这很容易通过大小分隔来检测。
从偏移量读取的实际过程需要首先定位存储数据的日志段文件,从全局偏移量值计算特定于文件的偏移量,然后从该文件偏移量中读取。搜索是作为针对每个文件维护的内存范围的简单二进制搜索变体完成的。
日志提供了获取最近写入的消息的能力,以允许客户从“现在”开始订阅。这在消费者未能在其 SLA 指定的天数内使用其数据的情况下也很有用。在这种情况下,当客户端尝试使用不存在的偏移量时,会给出 OutOfRangeException 并且可以根据用例自行重置或失败。
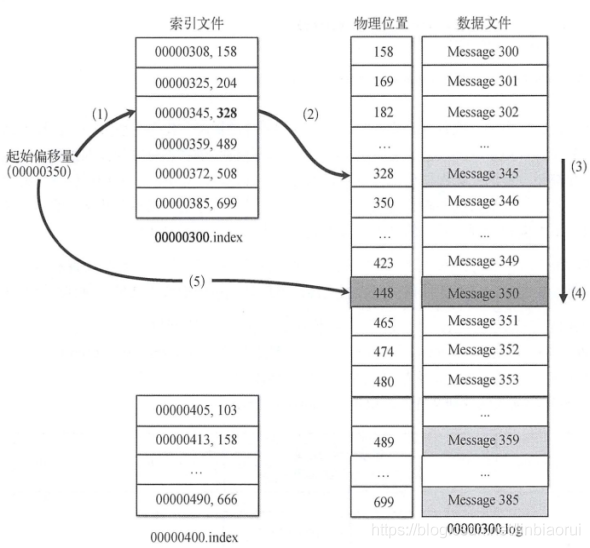
日志压缩
在默认的删除规则之外提供的另一种数据清除策略,对于有相同key的的不同value值,只保留最后一个版本 kafka中用于保存消费者消费位移的主题”__consumer_offsets”使用的就是log compaction策略。
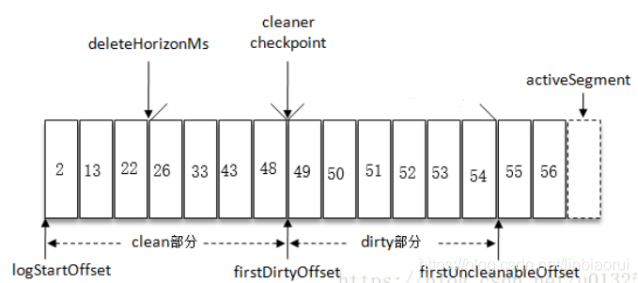
每个日志目录下,有名为”cleaner-offset-checkpoint”的文件,根据该文件可以将日志文件分成2部分
clean部分:偏移量是断续的,经过压缩的部分
dirty部分:偏移量是连续的,未清理过的部分
activeSegment部分:活跃的热点数据,不参与log campaction,默认情况下firstUncleanableOffset等于activeSegment的baseOffset
log campaction使用时应注意每个消息的key值不为null,这种方式当客户端进行消费时总能赶上dirty部分的情况,它就能读取到日志的所有消息,反之,就不可能读到全部的消息
如何确选择合适的log文件进行清理:
选择污浊率最高的,可通过配置log.cleaner.min.cleanable.ratio参数(默认0.5)
dirtyRatio = dirtyBytes / (cleanBytes + dirtyBytes)
如何对log文件中消息的key进行筛选:
1.创建一个名为”SkimpyOffsetMap”的哈希表来构建key与offset的映射表
2.遍历第一遍log文件,把每个key的hashCode和最后出现的offset都保存在SkimpyOffsetMap中
3.遍历第二遍log文件,检查每个消息是否符合保留条件,如果符合就保留下来,否则就会被清理掉
保留条件:假设一条消息的offset为O1,这条消息的key在SkimpyOffsetMap中所对应的offset为O2,如果O1>=O2即为满足保留条件
hash冲突处理:采用线性探测法来处理哈希冲突
线性探测法:通过hash计算出来的值如果冲突了则向后顺序存储。
缺点:遇到两个不同的key但哈希值相同的情况,那么其中一个key所对应的消息就会丢失
日志压缩步骤举例:
1.第一次日志压缩,清理点为0,日志头部的范围从0到活动分段的基准偏移量13
2.第一次压缩后,清理点更新为13,第二次日志压缩时,日志头部范围从13到活动日志分段的基准偏移量20,日志尾部范围从0到清理点的位置13
3.第二次压缩后,清理点更新为20,第三次日志压缩时,日志头部范围从20到活动日志分段的基准偏移量28,日志尾部范围从2到清理点的位置20
日志压缩合并:
1.第一次日志压缩,清理点等于0,没有尾部日志,日志头部从6:00带7:40,所有日志分段文件都是1GB,不考虑删除的消息
2.第一次日志压缩后,清理点改为日志头部末尾即7:40,每个新日志分段的大小都小于1GB
3.第二次日志压缩时,清理点为7:40,日志头部从8:00到8:10,日志尾部从6:00到7:40,压缩操作会将多个小文件分成1组,每一组不超过1GB
原文链接:https://blog.csdn.net/linbiaorui/article/details/84574458
作者:循环ing
日志定期删除
默认日志定期删除为168小时,即7天,可以通过配置server log.retention.hours=168进行修改
11.4. 配额
官网地址:https://kafka.apache.org/documentation/#design_quotas
一、为什么需要配额?
生产者和消费者可能会以非常高的速度生产/消费大量数据或生成请求,从而垄断broker资源,导致网络饱和,并且通常会 DOS 其他客户端和代理本身。
配额可以应用于(用户、客户端 ID)、用户或客户端 ID 组。
二、如何配置
可以通过两种方式来作配额管理:
- 在配置文件中指定所有client-id的统一配额。
- 动态修改zookeeper中相关znode的值,可以配置指定client-id的配额。
使用第一种方式,必须重启broker,而且还不能针对特定client-id设置。所以,推荐大家使用第二种方式。
配额配置的优先顺序是:
- /config/users/
/clients/ - /config/users/
/clients/ - /config/users/<用户>
- /config/users/<默认>/clients/
- /config/users/<默认>/clients/<默认>
- /config/users/<默认>
- /config/clients/
- /config/clients/<默认>
三、优先级
首先,我们需要明白,kafka在管理配额的时候,是以“组”的概念来管理的。而管理的对象,则是producer或consumer到broker的一条条的TCP连接。
那么在进行额度管理的时候,kafka首先需要确认,这条连接属于哪个“组”,进而确定当前连接是否超过了所属“组”的总额度。
四、超额处理
如果连接超过了配额值会怎么样呢?kafka给出的处理方式是:延时回复给业务方,不使用特定返回码。
五、配额方式
网络带宽配额定义为共享配额的每组客户端的字节速率阈值。默认情况下,每个唯一的客户端组都会收到集群配置的以字节/秒为单位的固定配额。此配额是基于每个代理定义的。在客户端被限制之前,每组客户端可以为每个代理发布/获取最多 X 字节/秒。
请求率配额定义为客户端可以在配额窗口内在每个代理的请求处理程序 I/O 线程和网络线程上使用的时间百分比。n%的配额表示 一个线程的n%,因此配额超出((num.io.threads + num.network.threads) * 100)%的总容量。每组客户端最多可使用n%的总百分比``在限制之前跨配额窗口中的所有 I/O 和网络线程。由于分配给 I/O 和网络线程的线程数通常基于代理主机上可用的内核数,因此请求率配额表示共享配额的每组客户端可能使用的 CPU 总百分比。
六、配额设置
为 (user=user1, client-id=clientA) 配置自定义配额:
1 | bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1 --entity-type clients --entity-name clientA |
通过在代理上设置这些配置,可以设置适用于所有客户端 ID 的默认配额。仅当 Zookeeper 中未配置配额覆盖或默认值时,才应用这些属性。默认情况下,每个客户端 ID 都会收到无限配额。下面将每个生产者和消费者客户端 ID 的默认配额设置为 10MB/秒。
1 | quota.producer.default=10485760 |
参照:官网地址:https://kafka.apache.org/documentation/#quotas
11.5. 异地复制
Kafka 管理员可以定义跨越单个 Kafka 集群、数据中心或地理区域边界的数据流。组织、技术或法律要求通常需要此类事件流设置。常见场景包括:
- 异地复制
- 灾难恢复
- 将边缘集群馈入中央聚合集群
- 集群的物理隔离(例如生产与测试)
- 云迁移或混合云部署
- 法律和合规要求
管理员可以使用 Kafka 的 MirrorMaker(版本 2)设置此类集群间数据流,这是一种以流方式在不同 Kafka 环境之间复制数据的工具。MirrorMaker 建立在 Kafka Connect 框架之上,并支持以下功能:
- 复制主题(数据加配置)
- 复制消费者组包括偏移量以在集群之间迁移应用程序
- 复制 ACL
- 保留分区
- 自动检测新主题和分区
- 提供广泛的指标,例如跨多个数据中心/集群的端到端复制延迟
- 容错和水平可扩展的操作
注意:使用 MirrorMaker 进行异地复制可跨 Kafka 集群复制数据。这种集群间复制不同于 Kafka 的集群内复制,后者复制同一 Kafka 集群内的数据。
使用 MirrorMaker,Kafka 管理员可以将主题、主题配置、消费者组及其偏移量以及 ACL 从一个或多个源 Kafka 集群复制到一个或多个目标 Kafka 集群,即跨集群环境。简而言之,MirrorMaker 使用连接器从源集群消费并生产到目标集群。
具体配置可以参考官网:
https://kafka.apache.org/documentation/#georeplication
11.6. 拦截器、序列化器、分区器、RecordAccumulator、InFlightRequests
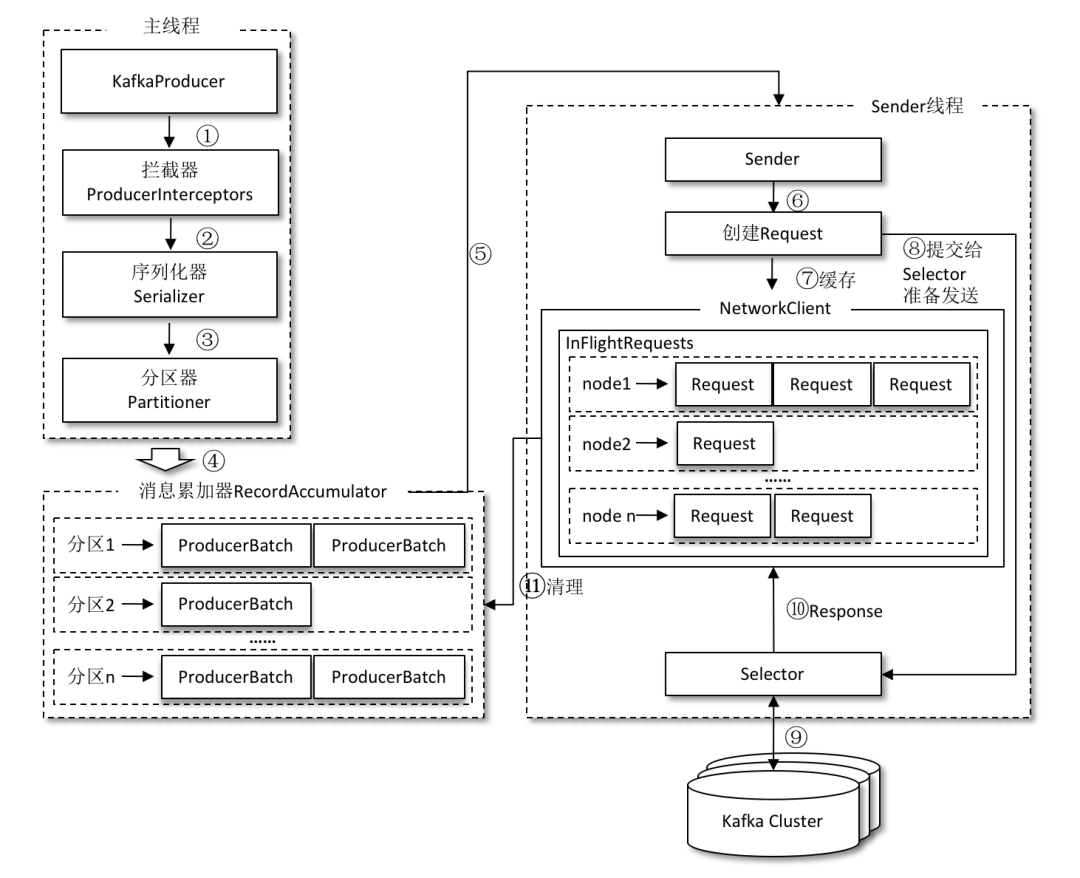
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。
在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
11.6.1. 拦截器
拦截器是在Kafka0.10.0.0版本中就已经引入的一个功能,Kafka一共有两种拦截器。生产者拦截器和消费者拦截器。
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
生产者拦截器的使用也很方便,主要是自定义实现 org.apache.kafka.clients.producer. ProducerInterceptor 接口。ProducerInterceptor 接口中包含3个方法:
1 | Copypublic ProducerRecord<K, V> onSend(ProducerRecord<K, V> record); |
KafkaProducer 在将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。一般来说最好不要修改消息 ProducerRecord 的 topic、key 和 partition 等信息。
KafkaProducer 会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的 onAcknowledgement() 方法,优先于用户设定的 Callback 之前执行。这个方法运行在 Producer 的I/O线程中,所以这个方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。
close() 方法主要用于在关闭拦截器时执行一些资源的清理工作。
11.6.2. 序列化器
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给 Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从 Kafka 中收到的字节数组转换成相应的对象。
生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的,如果生产者使用了某种序列化器,比如 StringSerializer,而消费者使用了另一种序列化器,比如 IntegerSerializer,那么是无法解析出想要的数据的。
序列化器都需要实现org.apache.kafka.common.serialization.Serializer 接口,此接口有3个方法:
1 | Copypublic void configure(Map<String, ?> configs, boolean isKey) |
configure() 方法用来配置当前类,serialize() 方法用来执行序列化操作。而 close() 方法用来关闭当前的序列化器。
如下:
1 | public class StringSerializer implements Serializer<String> { |
configure() 方法,这个方法是在创建 KafkaProducer 实例的时候调用的,主要用来确定编码类型。
serialize用来编解码,如果 Kafka 客户端提供的几种序列化器都无法满足应用需求,则可以选择使用如 Avro、JSON、Thrift、ProtoBuf 和 Protostuff 等通用的序列化工具来实现,或者使用自定义类型的序列化器来实现。
11.6.3. 分区器
消息经过序列化之后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为 partition 代表的就是所要发往的分区号。
如果消息 ProducerRecord 中没有指定 partition 字段,那么就需要依赖分区器,根据 key 这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。
Kafka 中提供的默认分区器是 org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了 org.apache.kafka.clients.producer.Partitioner 接口,这个接口中定义了2个方法,具体如下所示。
1 | Copypublic int partition(String topic, Object key, byte[] keyBytes, |
其中 partition() 方法用来计算分区号,返回值为 int 类型。partition() 方法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息,通过这些信息可以实现功能丰富的分区器。close() 方法在关闭分区器的时候用来回收一些资源。
在默认分区器 DefaultPartitioner 的实现中,close() 是空方法,而在 partition() 方法中定义了主要的分区分配逻辑。如果 key 不为 null,那么默认的分区器会对 key 进行哈希,最终根据得到的哈希值来计算分区号,拥有相同 key 的消息会被写入同一个分区。如果 key 为 null,那么消息将会以轮询的方式发往主题内的各个可用分区。
自定义的分区器,只需同 DefaultPartitioner 一样实现 Partitioner 接口即可。由于每个分区下的消息处理都是有顺序的,我们可以利用自定义分区器实现在某一系列的key都发送到一个分区中,从而实现有序消费。
11.6.4. RecordAccumulator
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
主线程中发送过来的消息都会被追加到 RecordAccumulator 的某个双端队列(Deque)中,在 RecordAccumulator 的内部为每个分区都维护了一个双端队列。
消息写入缓存时,追加到双端队列的尾部;Sender 读取消息时,从双端队列的头部读取。
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区, Deque< ProducerBatch>> 的保存形式转变成 <Node, List< ProducerBatch> 的形式,其中 Node 表示 Kafka 集群的 broker 节点。
KafkaProducer 要将此消息追加到指定主题的某个分区所对应的 leader 副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指定)目标分区,之后 KafkaProducer 需要知道目标分区的 leader 副本所在的 broker 节点的地址、端口等信息才能建立连接,最终才能将消息发送到 Kafka。
所以这里需要一个转换,对于网络连接来说,生产者客户端是与具体的 broker 节点建立的连接,也就是向具体的 broker 节点发送消息,而并不关心消息属于哪一个分区。
11.6.5. InFlightRequests
请求在从 Sender 线程发往 Kafka 之前还会保存到 InFlightRequests 中,InFlightRequests 保存对象的具体形式为 Map<NodeId, Deque>,它的主要作用是缓存了已经发出去但还没有收到响应的请求(NodeId 是一个 String 类型,表示节点的 id 编号)。
11.7. 数据同步
分区中的所有副本统称为 AR(Assigned Replicas)。所有与 leader 副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。
与 leader 副本同步滞后过多的副本(不包括 leader 副本)组成 OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
Leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当 follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除。默认情况下,当 leader 副本发生故障时,只有在 ISR 集合中的副本才有资格被选举为新的 leader。
HW 是 High Watermark 的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。 LEO 是 Log End Offset 的缩写,它标识当前日志文件中下一条待写入消息的 offset。
转载至:https://mp.weixin.qq.com/s/C6dfvzFkNDYgiNeZ4eWPBQ
作者:luozhiyun
12. kafka部署
下载 最新的 Kafka 版本并解压,如果习惯Zookeeper分离,下载地址:https://downloads.apache.org/zookeeper/
zookeeper部署
记得放行端口2181,2888,3888,9092
1 | tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz |
1 | 如果报错:Cannot open channel to 3 at election address /172.19.212.46:3888,No route to host |


命令
1 | kafka Zookeeper |
1 | 后台启动broker |
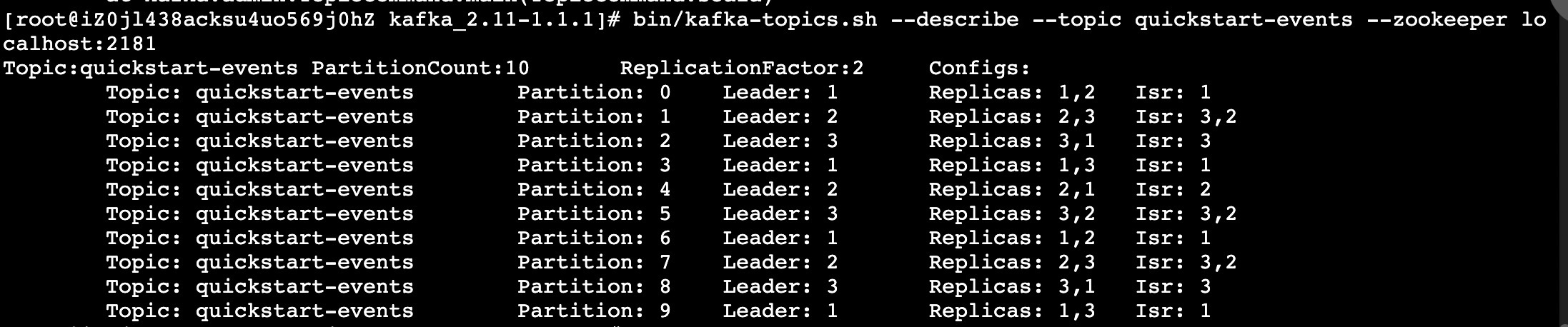
1 | 查看部署情况,在Zookeeper安装包下面,我的是/data/apache-zookeeper-3.6.3-bin执行 |
1 | 发送消息,生产者broker-list可以指定为localhost:9092 |

1 | # 消费消息 |
可以看出上面发布的消息是无序的,接下来我们指定分区,当然producer配置:max.in.flight.requests.per.connection=1
1 | bin/kafka-console-producer.sh --broker-list 172.19.212.41:9092 --topic quickstart-events --property parse.key=true |
这里的1和2不是分区,是我们producer指定的消息key,但是相同的key会通过hash落到相同的分区


我们可以看到同一个分区的消息是有序,不同分区的消息无法保证顺序
1 | 修改主题 |

1 | 添加配置 |
1 | 查看消费组 |

1 | 检查消费者位置 |
1 | # --members:此选项提供消费者组中所有活动成员的列表。 |

1 | --members --verbose:除了上面“--members”选项报告的信息之外,此选项还提供分配给每个成员的分区。 |

还有很多其他配置,可以参考官方文档:https://kafka.apache.org/documentation/#basic_ops_leader_balancing
包括集群扩展,数据迁移,增加副本,配额,分区平衡,正常关机等
可能出现的问题
如果出现报错bootstrap-server is not a recognized option,版本不一样,导致参数名称不一样,可以执行:
1
2
3$ bin/kafka-topics.sh查看参数后面问题一样处理
#我的执行命令:
$ bin/kafka-topics.sh --create --topic quickstart-events --zookeeper localhost:2181 --partitions 10 --replication-factor 2不同服务器部署集群时出现timeout:
1
检查一下是否是阿里云服务器,端口是否开放。
Configured broker.id 1 doesn’t match stored broker.id 0 in meta.properties
1
2
3
4
5
6broker.id=2
log.dirs=/tmp/kafka-logs
这是kafka产生log目录,log目录 下有meta.properties文件,而meta.properties文件中也写有broker.id,这是在运行时产生的。找到/tmp/kafka-logs/meta.properties,修改
version=0
broker.id=2
13. kafka流
13.1. Kafka Stream是什么
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。
Kafka Streams 是一个客户端库,用于处理和分析存储在 Kafka 中的数据。它建立在重要的流处理概念之上,例如正确区分事件时间和处理时间、窗口支持以及简单而高效的管理和应用程序状态的实时查询。
Kafka Streams入门门槛低:您可以在单台机器上快速编写和运行小规模的概念验证;并且您只需要在多台机器上运行应用程序的其他实例即可扩展到大批量生产工作负载。Kafka Streams 通过利用 Kafka 的并行模型透明地处理同一应用程序的多个实例的负载平衡。
Kafka Streams 的一些亮点:Kafka是一个开源分布式事件流平台,
- 设计为简单轻量级的客户端库,可轻松嵌入任何 Java 应用程序,并与用户为其流应用程序拥有的任何现有打包、部署和操作工具集成。
- 具有上比Apache kafka本身其他系统没有外部的依赖作为内部消息传输层; 值得注意的是,它使用 Kafka 的分区模型来水平扩展处理,同时保持强大的排序保证。
- 支持容错本地状态,这可以实现非常快速和高效的有状态操作,如窗口连接和聚合。
- 支持仅一次处理语义,以确保即使在处理过程中 Streams 客户端或 Kafka 代理出现故障时,每条记录也将被处理一次且仅一次。
- 采用一次一条记录处理以实现毫秒级处理延迟,并支持基于事件时间的窗口操作,记录无序到达。
- 提供必要的流处理原语,以及高级 Streams DSL和低级 Processor API。
13.2. 什么是流式计算
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。
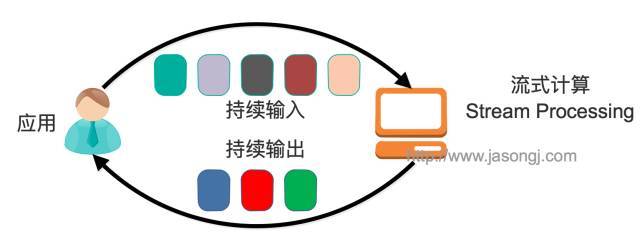
批量处理模型中,一般先有全量数据集,然后定义计算逻辑,并将计算应用于全量数据。特点是全量计算,并且计算结果一次性全量输出。
Mac mvn命令:https://www.jianshu.com/p/e572979171cd
官网地址:https://kafka.apache.org/28/documentation/streams/tutorial
Kafka流配置:https://kafka.apache.org/documentation/#streamsconfigs
文档地址:https://cloud.tencent.com/developer/article/1031210
14. kafka-python运行测试
PYPI 地址 https://pypi.org/project/kafka-python/
1 | # 生产者 |

1 | def consumer_data(topic, group_id): |

1 | 生产者和消费者更多配置可以查看kafka.py DEFAULT_CONFIG和group.py DEFAULT_CONFIG |
15. kafka与RabbitMQ
15.1. 设计
RabbitMQ 和 Kafka 在设计上存在非常明显的差异,因此在用例上也存在差异。RabbitMQ 的消息代理设计在具有特定路由需求和每条消息保证的用例中表现出色,而 Kafka 的仅附加日志允许开发人员访问流历史记录和更直接的流处理。虽然这两种技术可以实现的用例的维恩图非常紧凑,但在某些情况下,其中一种显然比另一种更好。
15.2 基准测试
作者: ALOK NIKHIL Vinoth Chandar
背景
Kafka是一个开源分布式事件流平台,也是 Apache 软件基金会最活跃的五个项目之一。从本质上讲,Kafka 被设计为一个复制的、分布式的、持久的提交日志,用于为事件驱动的微服务或大规模流处理应用程序提供动力。客户端直接向/从代理集群生成或消费事件,这些代理持久地将事件读/写到底层文件系统,并且还在集群内同步或异步地自动复制事件以实现容错和高可用性。
RabbitMQ是一个开源的传统消息中间件,它实现了 AMQP 消息标准,迎合了低延迟排队用例。RabbitMQ 由一组代理进程组成,这些进程托管用于向其发布消息的“交换”和用于从中消费消息的队列。可用性和持久性是提供的各种队列类型的属性。经典队列提供最少的可用性保证。经典镜像队列将消息复制到其他代理并提高可用性。通过最近引入的仲裁队列提供了更强的持久性,但以性能为代价。由于这是一篇以性能为导向的博文,我们将评估限制在经典队列和镜像队列上。
Apache Kafka ®是最流行的事件流系统之一。在这个领域有很多方法可以比较系统,但每个人都关心的一件事是性能。众所周知,Kafka速度很快,但今天它有多快,它与其他系统相比如何?我们决定在最新的云硬件上测试 Kafka 的性能以找出答案。
为了进行比较,我们选择了传统消息代理RabbitMQ和 基于Apache BookKeeper™的消息代理之一Apache Pulsar。我们专注于 (1)系统吞吐量和 (2)系统延迟,因为这些是生产中事件流系统的主要性能指标。特别是,吞吐量测试衡量每个系统在利用硬件(特别是磁盘和 CPU)方面的效率。延迟测试衡量每个系统与实时消息传递的接近程度,包括高达 p99.9% 的尾部延迟,这是实时和关键任务应用程序以及微服务架构的关键要求。
我们发现 Kafka 提供了最好的吞吐量,同时提供了最低的端到端延迟,最高可达 p99.9。在较低的吞吐量下,RabbitMQ 以非常低的延迟传递消息。
| 卡夫卡 | 脉冲星 | RabbitMQ (镜像) | |
|---|---|---|---|
| 峰值吞吐量 (MB/s) | 605 MB/秒 | 305 MB/秒 | 38 MB/秒 |
| p99 延迟 (毫秒) | 5 毫秒 (200 MB/s 负载) | 25 毫秒 (200 MB/s 负载) | 1 毫秒* (减少 30 MB/s 负载) |
*RabbitMQ 延迟在吞吐量高于 30 MB/s 时显着降低。此外,镜像的影响在更高的吞吐量下是显着的,并且可以通过仅使用经典队列而不使用镜像来实现更好的延迟。
(p99 1.403 表示过去的10秒内最慢的1%请求的平均延时为1.403秒)
分布式系统的耐久性
单节点存储系统(例如,RDBMS)依靠 fsyncing 写入磁盘来确保最大的持久性。但在分布式系统中,持久性通常来自复制,数据的多个副本独立失败。fsyncing 数据只是在故障发生时减少故障影响的一种方式(例如,fsyncing 更频繁可能会导致更短的恢复时间)。相反,如果有足够多的副本失败,无论 fsync 与否,分布式系统都可能无法使用。因此,我们是否 fsync 只是每个系统选择依赖于其复制设计的保证的问题。虽然有些人密切依赖永远不会丢失写入磁盘的数据,因此每次写入都需要 fsync,而其他人则在他们的设计中处理这种情况。
Kafka 的复制协议经过精心设计,通过跟踪已同步到磁盘和未同步到磁盘的内容来确保一致性和持久性保证,而无需同步 fsync。通过假设较少,Kafka 可以处理更广泛的故障,例如文件系统级损坏或意外的磁盘取消配置,并且不会理所当然地认为未知数据的正确性会被 fsync。Kafka 还能够利用操作系统批量写入磁盘以获得更好的性能。
在任何情况下,由于这可能是一个有争议的话题,我们在这两种情况下都给出了结果,以确保我们尽可能公平和完整,尽管使用同步 fsync 运行 Kafka 非常罕见,也没有必要。
试验台
OMB 包含用于其基准测试的测试平台定义(实例类型和 JVM 配置)和工作负载驱动程序配置(生产者/消费者配置和服务器端配置),我们将其用作测试的基础。所有测试都部署了四个工作实例来驱动工作负载、三个代理/服务器实例、一个监控实例,以及可选的用于 Kafka 和 Pulsar 的三实例 Apache ZooKeeper 集群。在对多种实例类型进行试验后,我们确定了 Amazon EC2 实例的网络/存储优化类,具有足够的 CPU 内核和网络带宽来支持磁盘 I/O 绑定工作负载。在下面的部分中,我们会指出我们对这些基线配置所做的任何更改,以及针对不同测试的过程。
吞吐量测试
fsync的效果
Apache Kafka 的默认推荐配置是使用底层操作系统规定的页面缓存刷新策略将消息刷新/同步到磁盘(而不是同步同步每条消息),并依靠复制来实现持久性。从根本上说,这提供了一种简单有效的方法来分摊 Kafka 生产者采用的不同批量大小的成本,以在所有条件下实现最大可能的吞吐量。如果 Kafka 被配置为在每次写入时进行 fsync,我们只会通过强制 fsync 系统调用来人为地降低性能,而没有任何额外的收益。
了解 fsyncing 对 Kafka 中每次写入的影响可能仍然是值得的。各种生产者批处理大小对 Kafka 吞吐量的影响如下所示。在达到“最佳点”之前,吞吐量随着批量大小的增加而增加,此时批量大小足以使底层磁盘完全饱和。将每条消息 Fsync 到 Kafka 上的磁盘(图 2 中的橙色条)会在更高的批量大小下产生可比较的结果。请注意,这些结果仅在所述测试台中的 SSD 上得到验证。Kafka 确实充分利用了所有批量大小的底层磁盘,即使在被迫对每条消息进行 fsync 时,也可以在较低批量大小下最大化 IOPS 或在较高批量大小下最大化磁盘吞吐量。
Kafka 中批处理大小对消息/秒吞吐量的影响,绿色条表示fsync=off(默认),橙色条分别表示fsync 每条消息
从上面的图表中可以明显看出,使用默认的 fsync 设置(绿色条)可以让 Kafka 代理更好地管理页面刷新以提供更好的整体吞吐量。特别是,较低生产者批次大小(1 KB 和 10 KB)的默认同步设置的吞吐量~3–5x高于通过 fsyncing 每条消息实现的吞吐量。然而,对于更大的批次(100 KB 和 1 MB),fsyncing 的成本被摊销,吞吐量与默认的 fsync 设置相当。
Kafka 和 RabbitMQ 以与测试实例兼容很简单。两者都主要依赖于操作系统的页面缓存,它会随着新实例自动缩小。
RabbitMQ 使用持久队列运行,当且仅当消息尚未被消费时,该队列将消息持久化到磁盘。然而,与 Kafka 和 Pulsar 不同,RabbitMQ 不支持“倒带”队列以再次读取旧消息。从持久性的角度来看,我们的基准测试表明消费者跟上生产者的步伐,因此我们没有注意到对磁盘的任何写入。我们还设置了 RabbitMQ,通过在三个代理的集群中使用镜像队列来提供与 Kafka 和 Pulsar 相同的可用性保证。
测试设置
该实验是根据以下原则和预期保证设计的:
- 消息被复制 3 次以实现容错(具体配置见下文)。
- 我们为所有三个系统启用批处理以优化吞吐量。我们最多批处理1 MB的数据,最多10 毫秒。
- Pulsar 和 Kafka在一个主题上配置了100 个分区。
- RabbitMQ 不支持主题中的分区。为了匹配 Kafka 和 Pulsar 设置,我们声明了一个直接交换(相当于一个主题)和链接队列(相当于分区)。可以在下面找到有关此设置的更多详细信息
OMB 使用自动速率发现算法,该算法通过以多种速率探测积压来动态得出目标生产者吞吐量。在许多情况下,我们看到确定的速率从 2.0 条消息/秒到 500,000 条消息/秒的剧烈波动。这些严重损害了实验的可重复性和保真度。在我们的实验中,我们在不使用此功能的情况下明确配置了目标吞吐量,并在每秒10K、50K、100K、200K、500K 和 100 万条生产者消息中稳步增加目标吞吐量,其中四个生产者和四个消费者使用1 KB消息。然后,我们观察了每个系统为不同配置提供稳定端到端性能的最大速率。
吞吐量结果
我们发现 Kafka 在我们比较的系统中提供了最高的吞吐量。鉴于其设计,产生的每个字节都只写入一次在代码路径上的磁盘上,该代码路径已被全球数千家组织优化了近十年。我们将在下面的每个系统中更详细地研究这些结果。
我们将 Kafka 配置为使用batch.size=1MB并linger.ms=10让生产者有效地批量写入发送到代理。此外,我们acks=all在生产者中进行了配置,min.insync.replicas=2以确保每条消息在将其确认回生产者之前至少复制到两个代理。我们观察到 Kafka 能够有效地最大化每个代理上的两个磁盘——这是存储系统的理想结果。详见 Kafka 的驱动配置。
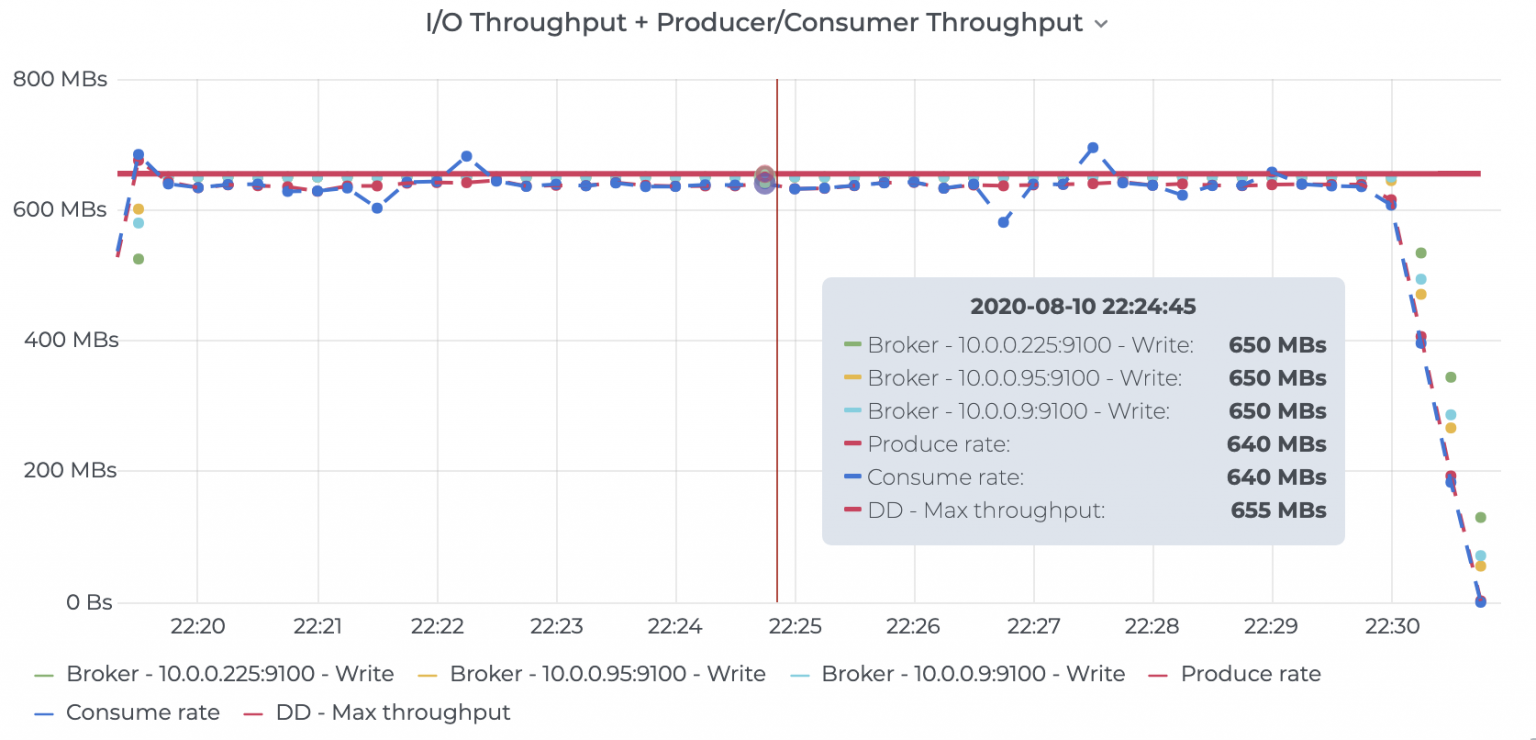
我们还使用另一种配置对 Kafka 进行了基准测试,即在使用flush.messages=1和flush.ms=0确认写入之前将每条消息同步到所有副本上的磁盘。结果如下图所示,与默认配置非常接近。
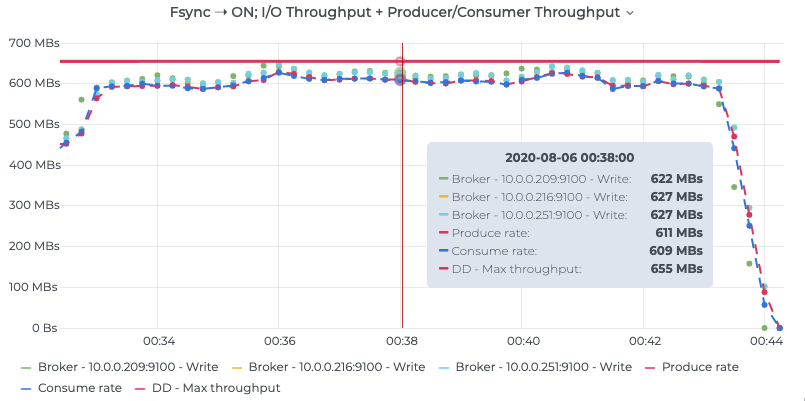
延迟测试
鉴于流处理和事件驱动架构的日益普及,消息系统的另一个关键方面是消息从生产者到系统再到消费者的管道中的端到端延迟。我们设计了一个实验,以每个系统可以维持的最高稳定吞吐量在所有三个系统上进行比较,而不会显示任何过度使用的迹象。
为了优化延迟,我们将所有系统的生产者配置更改为最多仅 1 毫秒的批处理消息(而我们用于吞吐量测试的 10 毫秒),并且还将每个系统保留在其默认推荐配置,同时确保高可用性。Kafka 被配置为使用其默认的 fsync 设置(即 fsync off),而 RabbitMQ 被配置为在仍然镜像队列的同时不保留消息。基于重复运行,我们选择在200K 消息/秒或 200MB/秒下比较 Kafka 和 Pulsar ,这低于此测试平台上 300 MB/s 的单磁盘吞吐量限制。我们观察到,当吞吐量高于30K 消息/秒时,RabbitMQ 将面临 CPU 瓶颈。
图 中为高可用性配置的标准模式的端到端延迟在 Kafka 和 Pulsar 上测量为 200K 消息/s(1 KB 消息大小),而在 RabbitMQ 上测量为 30K 消息/s,因为它无法维持更高的负载。注意:延迟 (ms) — 越低越好。
Kafka 始终提供比 Pulsar 更低的延迟。RabbitMQ 在三个系统中实现了最低的延迟,但鉴于其有限的垂直可扩展性,吞吐量只能低得多。由于实验是特意设置的,因此对于每个系统,消费者始终能够跟上生产者的步伐,因此几乎所有读取都由所有三个系统的缓存/内存提供。
Kafka 的大部分性能可归功于针对消费者的高度优化的读取实现,建立在高效的数据组织之上,没有任何额外的开销,如数据跳过。Kafka 深度利用 Linux 页面缓存和零复制机制,避免将数据复制到用户空间。通常,许多系统(例如数据库)都构建了应用程序级缓存,从而使它们能够更灵活地支持随机读/写工作负载。但是,对于消息传递系统,依靠页面缓存是一个不错的选择,因为典型的工作负载会执行顺序读/写。Linux 内核经过多年优化,可以智能地检测这些模式,并采用预读等技术来大幅提高读取性能。类似地,建立在页面缓存之上允许 Kafka 使用基于sendfile 的网络传输,避免额外的数据副本。与吞吐量测试保持一致,我们还通过将 Kafka 配置为 fsync 每条消息来运行相同的测试。
RabbitMQ 的性能是生产者端的交换和消费者端绑定到这些交换的队列的一个因素。我们在延迟实验中使用了吞吐量实验中相同的镜像设置,特别是直接交换和镜像队列。由于 CPU 瓶颈,我们无法驱动高于 38K 消息/s 的吞吐量,并且以该速率测量延迟的任何尝试都显示性能显着下降,p99 延迟接近2毫秒。
将吞吐量从 38K 消息/s 逐渐降低到 30K 消息/s 使我们能够建立稳定的吞吐量,此时系统似乎没有被过度使用。明显更好的 1 毫秒 p99 延迟证实了这一点。我们认为在三个节点上复制 24 个队列的开销似乎对更高吞吐量下的端到端延迟产生了深远的负面影响,而低于 30K 消息/s 或 30 MB/s(实心洋红色线)的吞吐量允许 RabbitMQ提供明显低于其他两个系统的端到端延迟。
一般来说,遵循其最佳实践允许 RabbitMQ 提供有限的延迟。鉴于延迟实验是故意设置的,以便消费者始终能够跟上生产者,RabbitMQ 消息传递管道的效率归结为 Erlang BEAM VM(以及 CPU)需要执行的上下文切换次数处理队列。因此,通过为每个 CPU 内核指定一个队列来限制这种情况,可以实现尽可能低的延迟。此外,使用 Direct 或 Topic 交换允许复杂的路由(类似于专用于 Kafka 和 Pulsar 上的分区的消费者)到特定队列。但是直接交换提供了更好的性能,因为没有通配符匹配,这增加了更多的开销并且是这个测试的合适选择。
图中Kafka、Pulsar 和 RabbitMQ 的端到端延迟,在 Kafka 和 Pulsar 上测量为 200K 消息/s(1 KB 消息大小),在 RabbitMQ 上测量为 30K 消息/s。有关详细信息,请参阅原始结果(Kafka、Pulsar和RabbitMQ)。注意:延迟 (ms) — 越低越好。
我们已经在本节开头介绍了 Kafka 在其默认推荐的 fsync 配置(绿色实线)中的延迟结果。在 Kafka fsync 将每条消息发送到磁盘(绿色虚线)的替代配置中,我们发现 Kafka 的延迟仍然比 Pulsar 低,几乎直到 p99.9th 百分位数,而 Pulsar(蓝线)在高尾百分位数上表现更好. 虽然在 p99.9 百分位及以上准确推断尾部延迟是困难的,但我们认为,对于替代的 Kafka fsync 配置(绿色虚线),非线性延迟在 p99.9 百分位飙升可归因于极端情况考虑到生产者延迟似乎遵循相同的趋势,因此涉及 Kafka 生产者。
图 中RabbitMQ 的端到端延迟:10K、20K、30K 和 40K 消息/秒的镜像队列(测试中使用的配置)与经典队列(无复制)。注意:在此图表中,y 轴上的刻度是对数的。
我们承认,每个系统的设计都有一定的权衡。尽管对 Kafka 和 Pulsar 不公平,但我们发现在不提供高可用性的配置中比较 RabbitMQ 与 Kafka 和 Pulsar 的配置很有趣,两者都以较低的延迟来提供更强的持久性保证以及比 RabbitMQ 高 3 倍的可用性。这可能与某些用例(例如,设备位置跟踪)相关,在这些用例中,为了更好的性能而折衷可用性是可以接受的,尤其是在用例需要实时消息传递并且对可用性问题不敏感的情况下。我们的结果表明,当禁用复制时,RabbitMQ 可以在更高的吞吐量下更好地维持更低的延迟,
尽管 Kafka 和 Pulsar 速度较慢(分别在 p99 处计时**5 ms和25 ms**),但它们提供的持久性、更高的吞吐量和更高的可用性对于大规模事件流用例(例如处理金融交易或零售库存管理。对于需要较低延迟的用例,RabbitMQ 可以实现 p99 ~1 ms 的延迟,只要它是轻载的,因为消息只是在内存中排队,没有复制开销。
在实践中,运营商需要谨慎地配置 RabbitMQ 以保持足够低的速率以维持这些低延迟,除非延迟迅速且显着地降低。但这项任务很难,甚至几乎不可能在所有用例中以一般方式实现。总体而言,具有更低运营开销和成本的更好架构选择可能是为所有用例选择一个像 Kafka 这样的持久系统,该系统可以在所有负载级别提供最佳吞吐量和低延迟。
RabbitMQ 在复制开销方面表现不佳,严重降低了系统的吞吐量。我们注意到在此工作负载期间所有节点都受 CPU 限制(参见下图中带有右侧 y 轴的绿线),几乎没有空间用于代理任何其他消息。有关详细信息,请参阅RabbitMQ 驱动程序配置。
在这节中,我们对三种消息传递系统进行了全面、平衡的分析:Kafka、RabbitMQ 和 Pulsar,由此得出以下结论。
吞吐量:Kafka 提供所有系统中最高的吞吐量,写入速度比 RabbitMQ 快 15 倍,比 Pulsar 快 2 倍。
延迟: Kafka 在更高的吞吐量下提供最低的延迟,同时还提供强大的持久性和高可用性。在所有延迟基准测试中,默认配置中的 Kafka 比 Pulsar 更快,并且当在每条消息上设置为 fsync 时,速度最高可达 p99.9。RabbitMQ 可以实现比 Kafka 更低的端到端延迟,但只是在吞吐量显着降低的情况下。
成本/复杂性
成本往往是性能的反函数。Kafka 作为具有最高稳定吞吐量的系统,由于其高效的设计,在所有系统中提供了最佳价值(即每字节写入的成本)。事实上,Twitter 的Kafka摆脱 Pulsar 等基于 BookKeeper 的架构的历程证实了我们的观察,即 Kafka 较少的移动部件显着降低了其成本(在 Twitter 的案例中高达 75%)。此外,从 Apache Kafka 中删除 ZooKeeper(参见KIP-500)的工作正在进行中,并进一步简化了 Kafka 的架构。
实现
不同于基于队列和交换器的RabbitMQ,Kafka的存储层是使用分区事务日志来实现的。
尽管有时候RabbitMQ和Kafka可以当做等价来看,但是他们的实现是非常不同的。所以我们不能把他们当做同种类的工具来看待;一个是消息中间件,另一个是分布式流式系统。
16. kafka 源码查看
抱歉目前java讲义还没看完,看完之后正好研究一下kafka源码